


李浩然,CMU 机器学习系研究生,研究方向是基础模型的长上下文建模、对齐、以及检索增强生成。
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。
虽然旋转位置编码 (RoPE, Rotary Position Embedding) 被广泛用于提升大语言模型的长度泛化能力,但是如何将 RoPE 有效地扩展到多模态领域仍然是一个开放问题。具体而言,常用的扩展方法是使用 RoPE 中不同的频率来编码不同的位置信息 (x,y,t)。然而,由于 RoPE 中每个维度携带的频率不同,所以存在着不同的分配策略。那么,到底什么是将 RoPE 扩展到多模态领域的最佳策略呢?
来自 CMU 和小红书的研究团队对这一问题进行了深入研究,他们首次提出了针对多模态 RoPE 扩展策略的理论评估框架,指出现有多模态 RoPE 泛化能力不足的原因之一是保留 RoPE 中所有频率对长上下文语义建模有负面影响。基于此分析,他们提出的混合位置编码(HoPE, Hybrid of Position Embedding)大幅提升了 VLM 的长度泛化能力,在长视频理解和检索等任务中达到最优表现。

-
论文标题:HoPE: Hybrid of Position Embedding for Length Generalization in Vision-Language Models
-
arXiv 链接:https://arxiv.org/pdf/2505.20444
-
代码链接:https://github.com/hrlics/HoPE
研究亮点
发现 —— 保留所有频率限制语义建模
作者们首先定义了语义偏好这一性质,即在任意的相对距离下,使用多模态 RoPE 的注意力机制分配给语义相近的 Query, Key pair 的注意力应该要高于语义上无关的 Query, Key pair。如果这一基本性质不能得以保证,那么上下文中明明应该被关注的部分将不被重点关注,进而影响长度泛化能力。
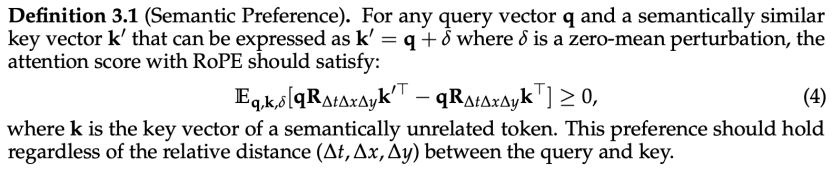
然而,在现有的多模态 RoPE 的频率分配策略中,语义偏好性质都无法在长上下文场景中得到保证。其缘由是用于时间维度的任意非零频率在长上下文中都会产生过多的旋转,导致语义相近的 Query, Key pair 注意力分数期望低于语义上无关的 Query, Key pair。
基于语义偏好性质的多模态 RoPE 分析框架
(1)低频率时间建模优于高频率时间建模
作者们定义的语义偏好性质可以进一步简化为下面的形式:
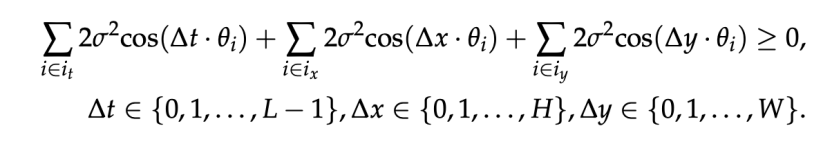
其中,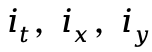 分别是分配给时间 (t) 和空间 (x,y) 的频率,
分别是分配给时间 (t) 和空间 (x,y) 的频率,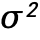 是 Query/Key 每个维度的方差,而
是 Query/Key 每个维度的方差,而 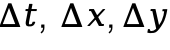 代表了 Query 和 Key 之间的相对位置。
代表了 Query 和 Key 之间的相对位置。
考虑一个长上下文场景,也就是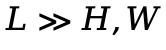 ,基于语义偏好性质的分析框架可以首先证明为什么在多模态 RoPE 中,使用最低频率建模时间维度(VideoRoPE)要优于最高频率建模时间维度 (M-RoPE)。首先,考虑到单一图像尺寸的有限性,语义偏好性质中的空间项几乎保持非负性。
,基于语义偏好性质的分析框架可以首先证明为什么在多模态 RoPE 中,使用最低频率建模时间维度(VideoRoPE)要优于最高频率建模时间维度 (M-RoPE)。首先,考虑到单一图像尺寸的有限性,语义偏好性质中的空间项几乎保持非负性。
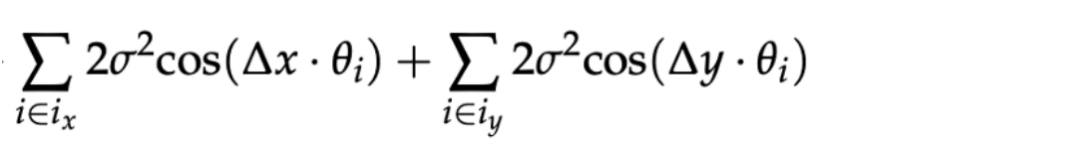
然而,由于在长上下文中 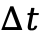 较大。语义偏好性质中的时间项很容易为负,从而破坏语义偏好性质:
较大。语义偏好性质中的时间项很容易为负,从而破坏语义偏好性质:

因此易得,使用高频率来建模时间维度相比于使用低频率更容易破坏语义偏好性质,从而在长上下文中表现更差。
(2)低频率时间建模在长上下文中仍不可靠
虽然使用低频率建模时间维度更有助于保持语义偏好性质,但是在足够长的上下文中,这一性质依然会被破坏。在最极端的情况下,多模态 RoPE 中用于建模时间维度的频率都是 RoPE 中最小的频率,也就是:
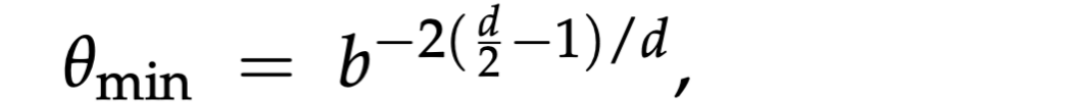
那么,语义偏好性质中的时间项可以化简为:
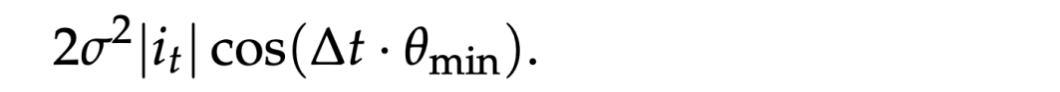
然而,当上下文长度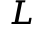 足够大时,即满足:
足够大时,即满足:

就存在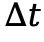 ,使得
,使得

从而令语义偏好性质不成立。
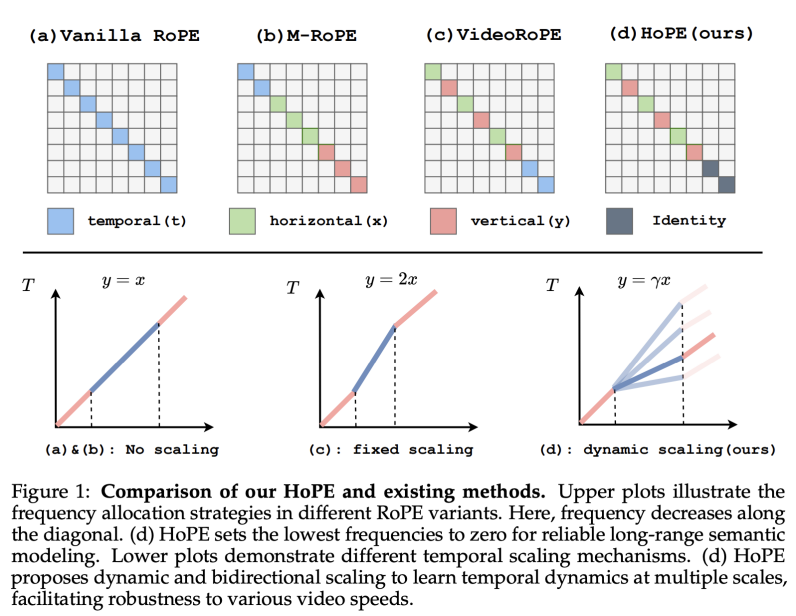
算法 —— 零频率时间建模和多尺度时序学习
在以往的研究中,大家通常利用注意力可视化分析来决定多模态 RoPE 中的频率分配策略。该研究首次从理论上分析了不同频率分配策略对 VLM 长度泛化能力的影响,指出了保留所有频率的策略抑制了多模态长下文中的语义建模。根据此分析,该研究提出了混合位置编码(HoPE, Hybrid of Postion Embedding), 旨在提升 VLM 在长上下文中的语义建模能力,从而进一步提升其长度泛化能力。
具体而言,在频率分配策略中,HoPE 提出了混合频率分配策略,结合了时间维度的无位置编码(NoPE, No Position Embedding)和空间维度的多模态位置编码,达成了在任意长度上下文中稳定保持语义偏好性质的效果。具体而言,时间维度的零频率建模相比于任意其他的频率分配策略提供了更强的语义偏好性质保障:
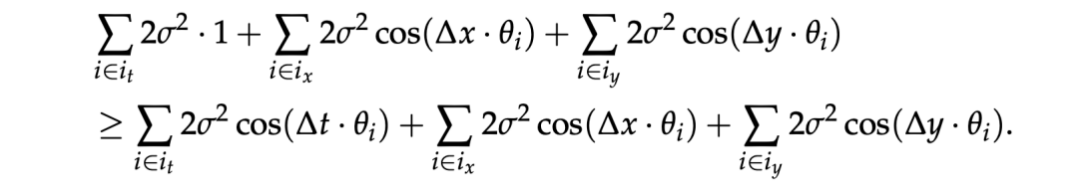
也就是在任意相对距离下,语义相近的 QK pair 所获的的注意力期望大于语义无关的 QK pair 的概率更大。
其对应的旋转矩阵如下:

在位置编码方面,部分方法对于视觉 token 的时间编码 (t) 采取不缩放 (No Scaling) 的策略,而考虑到视觉 token 的冗余性和信息密度方面与文本 token 的不同,有方法采用的固定缩放 (Fixed Scaling) 的策略。相比之下,HoPE 考虑了实际场景中不同视频的进行速度的不同(如纪录片和动作片),对于视觉 token 的时间编码 (t) 采取了动态缩放策略。在训练阶段通过取不同的缩放因子使 VLM 学习不同尺度的时序关系,增强其对不同视频速度的鲁棒性,另外,在推理期间,缩放因子可以随着应用场景的不同而调整,提供了适应性的选择。
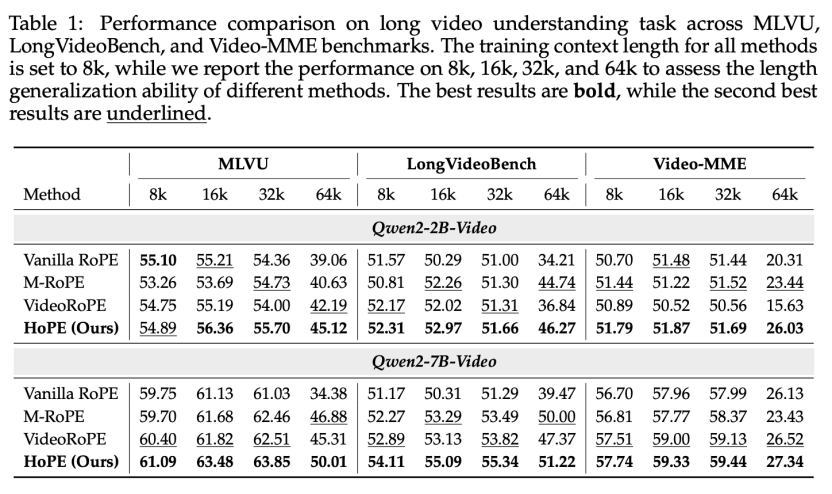
实验
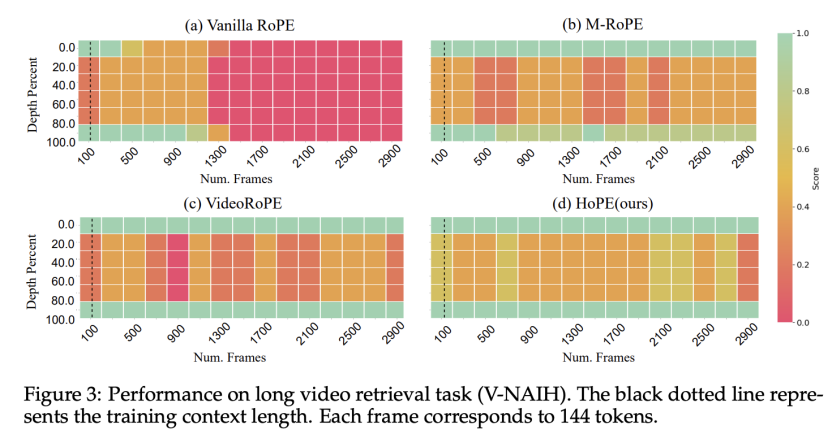
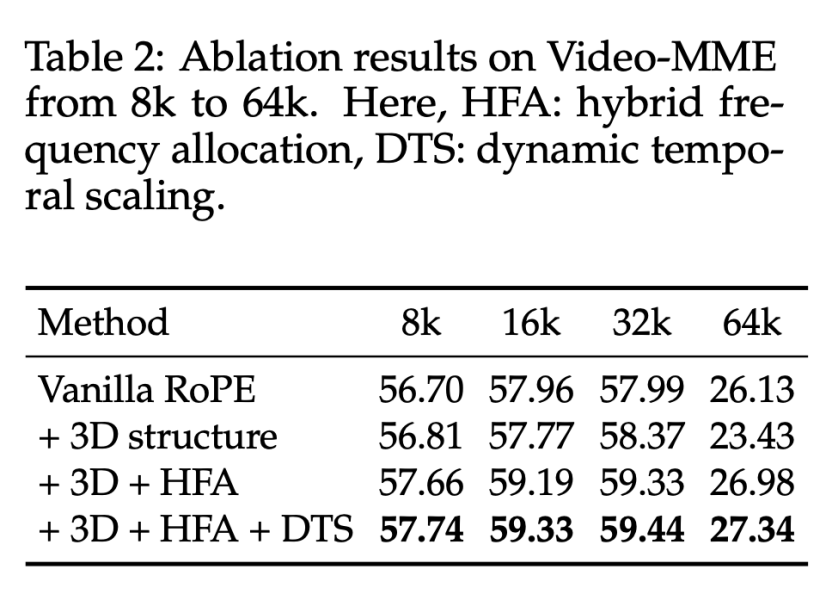
该文章在长视频理解、长视频检索的多个 benchmark 中对不同的方法进行了对比,验证了 HoPE 在多模态长上下文建模中的卓越表现,在不同模型尺寸、测试长度、测试任务上几乎都达到了最优的表现。

©
(文:机器之心)