

一、CRL总览
A. 定义(Definition)
-
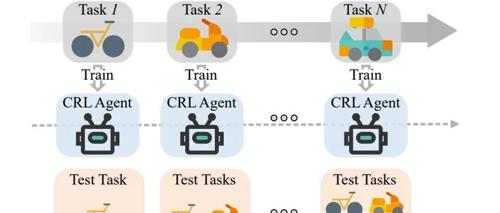
CRL的定义:CRL是强化学习(RL)的扩展,强调智能体在动态、多任务环境中持续学习、适应和保留知识的能力。
-
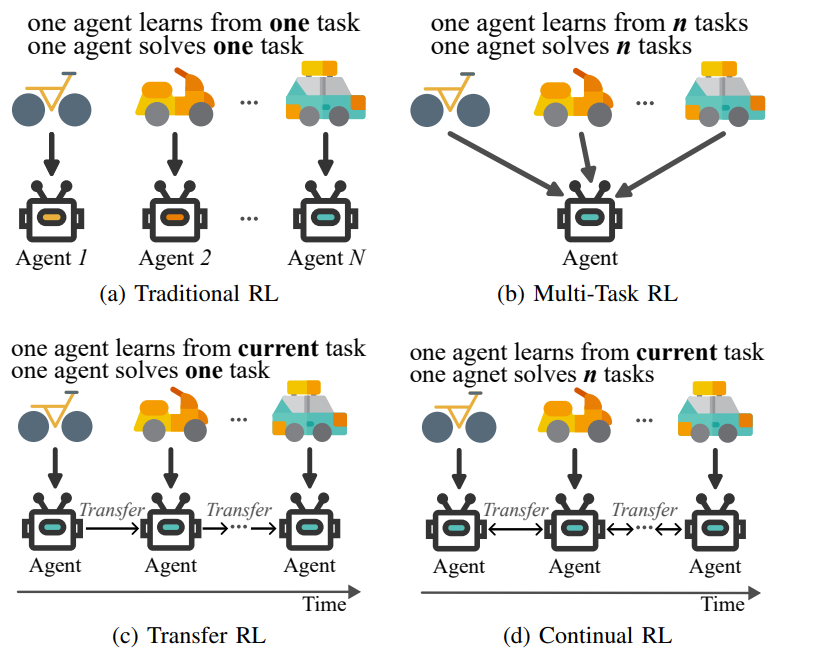
与传统RL的区别:传统RL通常专注于单一任务,而CRL强调在任务序列中保持和提升泛化能力。
-
与多任务RL(MTRL)和迁移RL(TRL)的关系:
-
MTRL:同时处理多个任务,任务集固定且已知。
-
TRL:将知识从源任务迁移到目标任务,加速目标任务的学习。
-
CRL:任务通常按顺序到达,环境持续变化,目标是积累知识并快速适应新任务。
B. 挑战(Challenges)
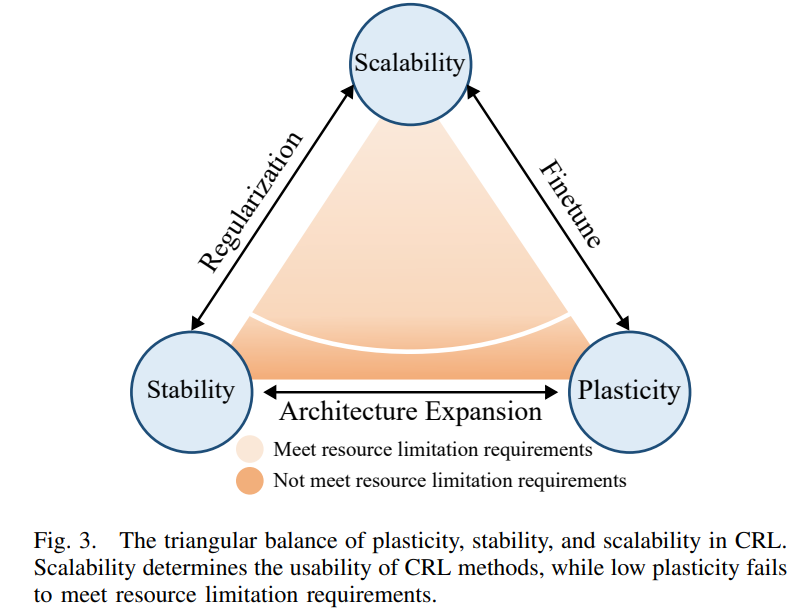
-
CRL面临的主要挑战:在可塑性(plasticity)、稳定性(stability)和可扩展性(scalability)之间实现三角平衡。
-
稳定性:避免灾难性遗忘,保持对旧任务的性能。
-
可塑性:学习新任务的能力,以及利用先前知识提高新任务性能的能力。
-
可扩展性:在资源有限的情况下学习多个任务的能力。
C. 度量标准(Metrics)
-
传统RL的度量:通常使用累积奖励或成功率来衡量智能体的性能。
-
CRL的度量:
-
平均性能(Average Performance):智能体在所有已学习任务上的整体性能。
-
遗忘(Forgetting):智能体在后续训练后对旧任务性能的下降程度。
-
转移(Transfer):智能体利用先前任务知识提高未来任务性能的能力,包括前向转移和后向转移。
D. 任务(Tasks)
-
导航任务:在二维状态空间中使用离散动作集,智能体探索未知环境以到达目标。
-
控制任务:涉及三维状态空间和离散动作集,智能体使用控制命令达到特定目标状态。
-
视频游戏:状态空间通常为图像,动作为离散,智能体执行复杂控制以实现目标。
E. 基准测试(Benchmarks)
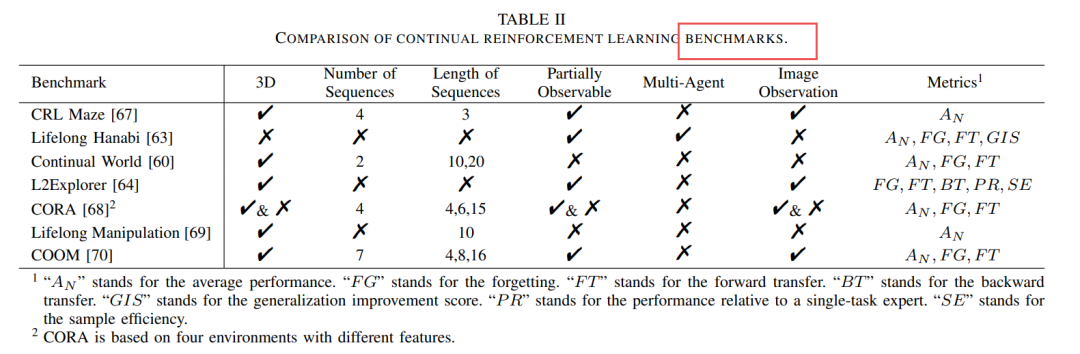
-
CRL基准测试:如CRL Maze、Lifelong Hanabi、Continual World等,这些基准测试在任务数量、任务序列长度和观察类型等方面有所不同。
F. 场景设置(Scenario Settings)

-
CRL场景分类:
-
终身适应(Lifelong Adaptation):智能体在任务序列上训练,仅在新任务上评估性能。
-
非平稳性学习(Non-Stationarity Learning):任务在奖励函数或转移函数上有所不同,智能体在所有任务上评估性能。
-
任务增量学习(Task Incremental Learning):任务在奖励和转移函数上显著不同,智能体在所有任务上评估性能。
-
任务无关学习(Task-Agnostic Learning):智能体在没有任务标签或身份的情况下训练,需要推断任务变化。
二、CRL分类

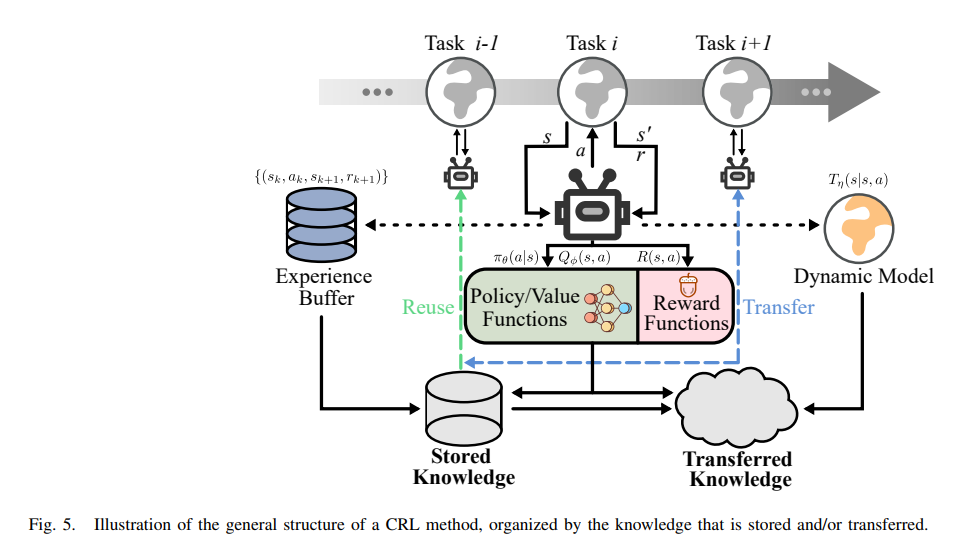
系统地回顾了持续强化学习(CRL)领域的主要方法,并提出了一种新的分类体系,将CRL方法按照所存储和/或转移的知识类型分为四大类:基于策略的(Policy-focused)、基于经验的(Experience-focused)、基于动态的(Dynamic-focused)和基于奖励的(Reward-focused)方法。
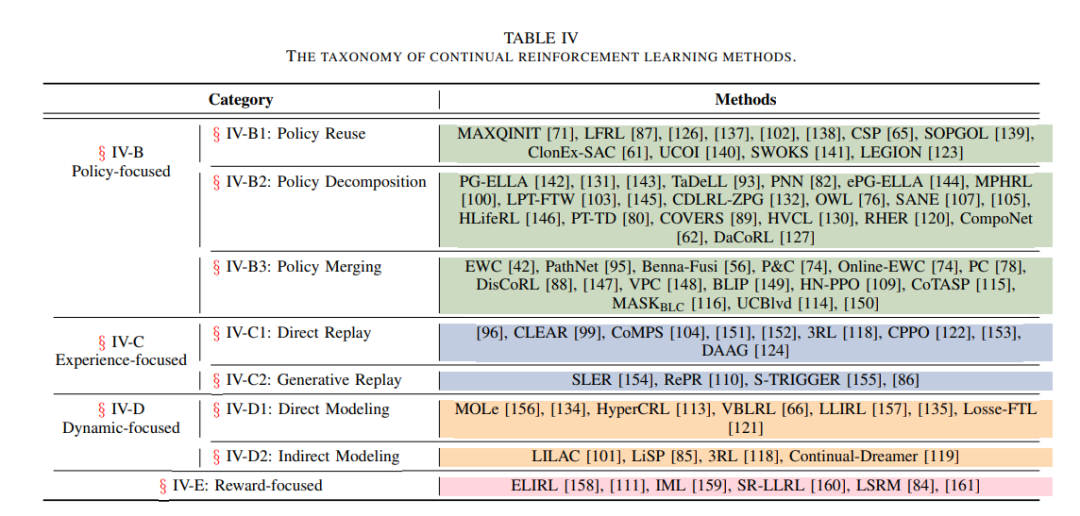
A. 基于策略的方法
这是最主流的一类方法,强调对策略函数或价值函数的存储与复用,分为三个子类:
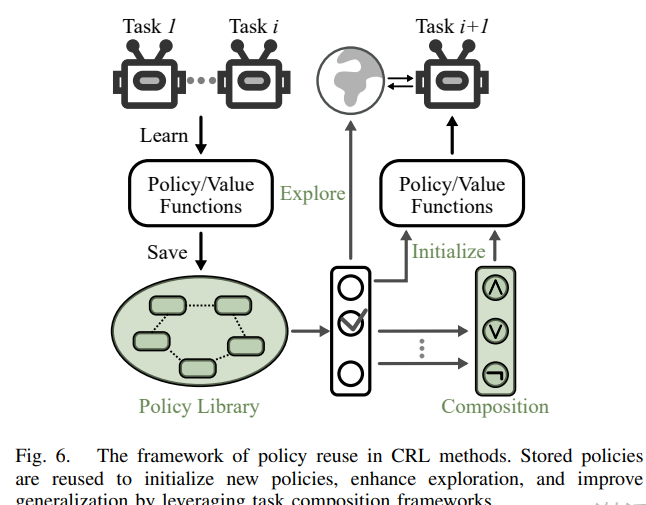
1)策略重用(Policy Reuse)
-
保留并重用先前任务的完整策略。
-
常见做法:使用旧策略初始化新策略(如MAXQINIT、ClonEx-SAC)。
-
高级方法:使用任务组合(如布尔代数)实现零样本泛化(如SOPGOL)。
-
可扩展性较差,但知识迁移能力强。
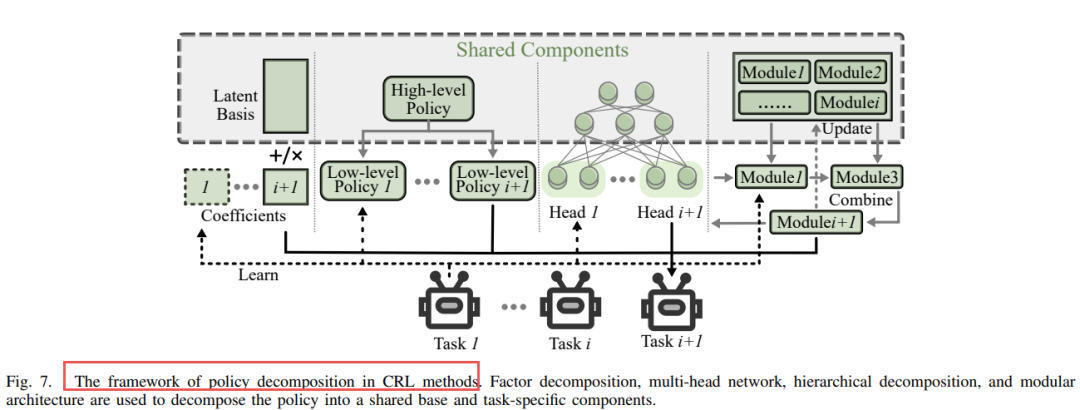
2)策略分解(Policy Decomposition)
-
将策略分解为共享组件和任务特定组件。
-
方法包括:
-
因子分解(如PG-ELLA、LPG-FTW)
-
多头网络(如OWL、DaCoRL)
-
模块化结构(如SANE、CompoNet)
-
层次化结构(如H-DRLN、HLifeRL、MPHRL)
-
优点:结构清晰、可扩展性强、适合复杂任务。
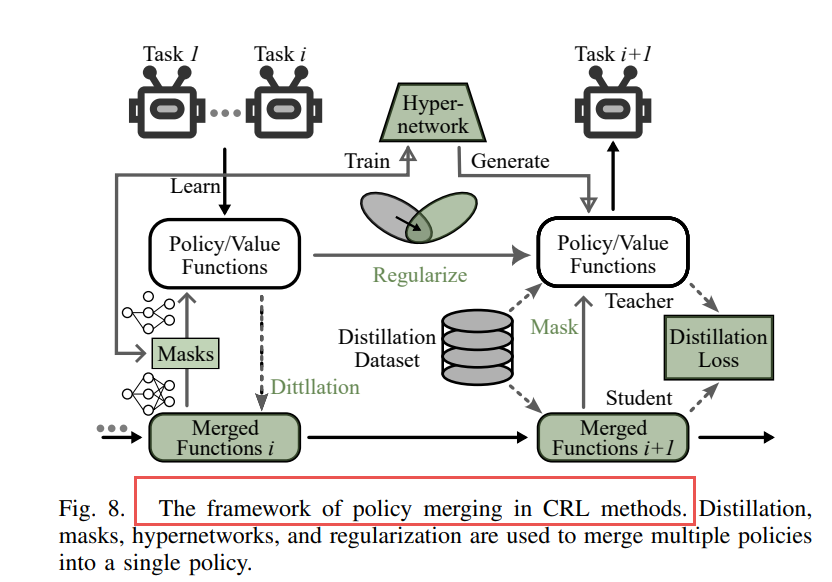
3)策略合并(Policy Merging)
-
将多个策略合并为一个模型,节省存储资源。
-
技术手段包括:
-
蒸馏(如P&C、DisCoRL)
-
超网络(如HN-PPO)
-
掩码(如MASKBLC)
-
正则化(如EWC、Online-EWC、TRAC)
-
优点:节省内存、适合资源受限场景。
B. 基于经验的方法
强调对历史经验的存储与复用,类似于经验回放机制,分为两类:

1)直接回放(Direct Replay)
-
使用经验缓冲区保存旧任务数据(如CLEAR、CoMPS、3RL)。
-
优点:简单有效,适合任务边界明确的场景。
-
缺点:内存消耗大,存在隐私风险。
2)生成回放(Generative Replay)
-
使用生成模型(如VAE、GAN)合成旧任务经验(如RePR、SLER、S-TRIGGER)。
-
优点:节省内存,适合任务边界模糊或资源受限场景。
-
缺点:生成质量影响性能。
C. 基于动态的方法(Dynamic-focused Methods)
通过建模环境动态(状态转移函数)来适应非平稳环境,分为两类:
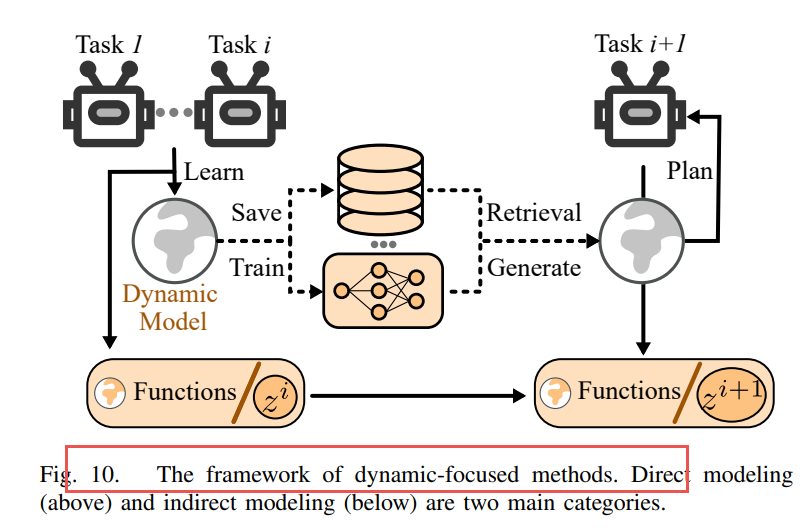
1)直接建模(Direct Modeling)
-
显式学习环境转移函数(如MOLe、LLIRL、HyperCRL)。
-
优点:适合需要长期规划的任务。
-
缺点:建模复杂,计算开销大。
2)间接建模(Indirect Modeling)
-
使用潜变量或抽象表示推断环境变化(如LILAC、3RL、Continual-Dreamer)。
-
优点:更灵活,适合任务边界不明确或动态变化的环境。
-
常与内在奖励机制结合使用。
D. 基于奖励的方法(Reward-focused Methods)
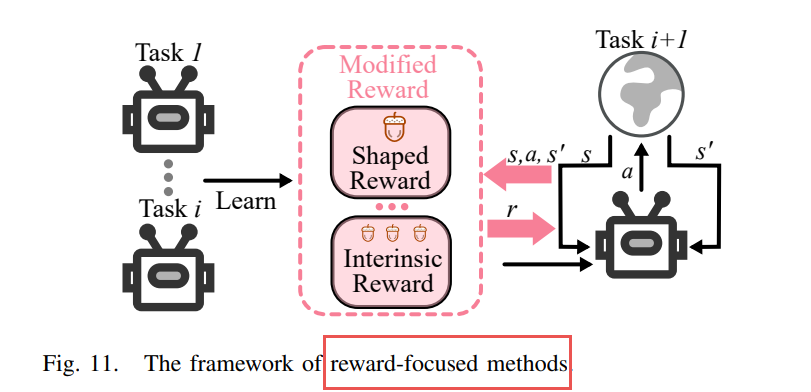
通过修改或重塑奖励函数来促进知识迁移和探索,常见方法包括:
-
奖励塑形(Reward Shaping):如SR-LLRL、基于时序逻辑的塑形方法。
-
内在奖励(Intrinsic Rewards):如IML、Reactive Exploration,通过好奇心驱动探索。
-
逆强化学习(IRL):如ELIRL,从专家演示中学习奖励函数。
-
大模型辅助奖励设计:如MT-Core,使用大语言模型生成任务相关的内在奖励。
https://arxiv.org/pdf/2506.21872A Survey of Continual Reinforcement Learning
(文:PaperAgent)