

极市导读
本文提出了一种轻量级的遥感视觉模型,通过构建大规模遥感数据集 RemoteSAM-270K 和统一的模型架构,实现了从像素级到图像级的多种视觉任务,显著提升了遥感视觉任务的效率和性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
论文介绍
题目:RemoteSAM: Towards Segment Anything for Earth Observation
会议:33rd ACM International Conference on Multimedia (ACM MM 2025)
论文:https://arxiv.org/pdf/2505.18022
数据&模型:https://github.com/1e12Leon/RemoteSAM
年份: 2025
单位: 河海大学(RemoteCLIP作者团队)、香港科技大学、东南大学

动机
地球观测任务(如灾害监测、城市发展)需处理多粒度视觉任务(像素级分割、区域检测、图像分类)。但当前主流范式存在两大瓶颈:
-
任务专用模型(如RingMo、ScaleMAE):
-
每个任务需独立设计解码器 → 知识无法共享,扩展性差。 -
文本统一模型(如Falcon、GeoChat):
-
依赖语言模型处理视觉任务 → 像素级任务(如分割)性能弱。 -
动辄数十亿参数 → 计算成本高,难以处理高分辨率遥感数据。
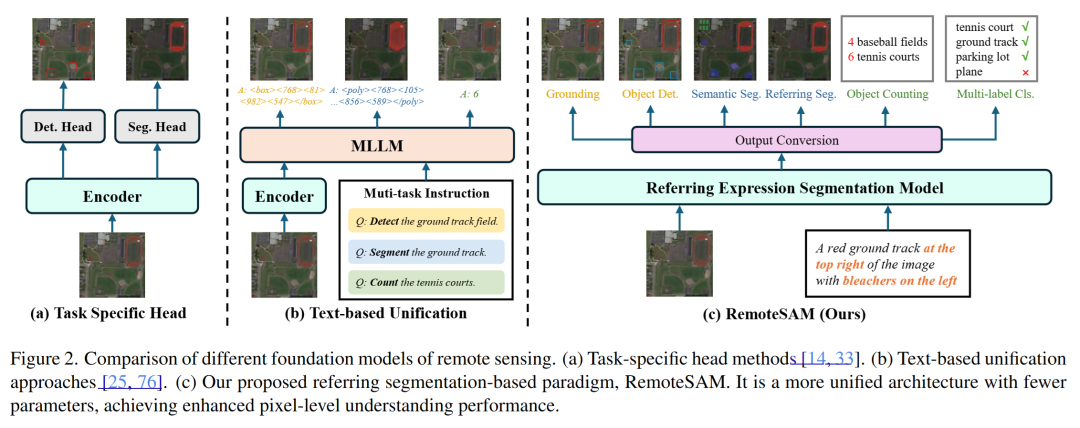
核心贡献
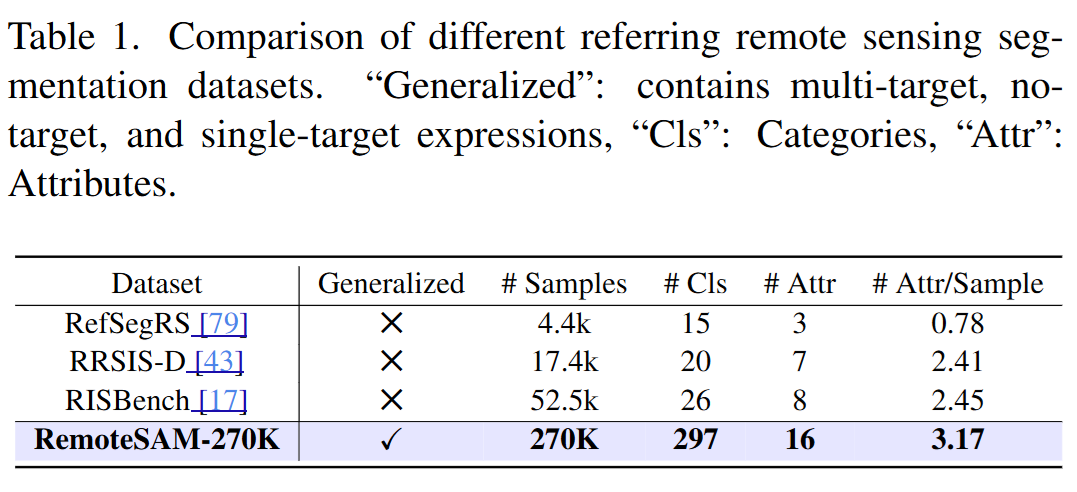
-
最大遥感RES数据集:
-
RemoteSAM-270K:27万组高质量图文掩码三元组,覆盖297种目标类别(建筑、农田、船舶等)和16种属性(颜色、空间关系等)。 -
广义指代表达式:支持单目标、多目标、零目标的指代分割指令。 -
自动化构建:利用VLMs生成描述 + 多教师模型定位目标 + SigLIP过滤噪声。 -
统一模型RemoteSAM:
-
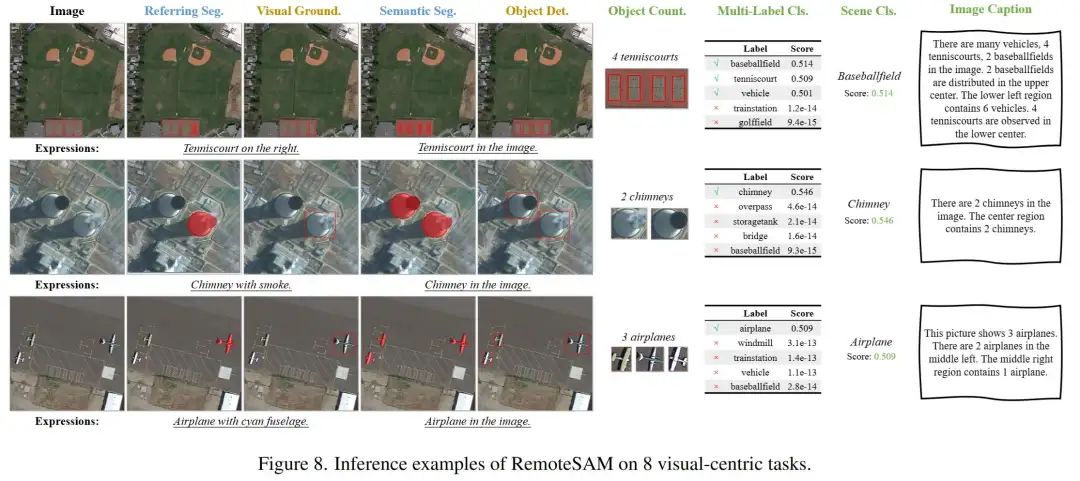
以指代分割(RES)为核心,通过像素级掩码的决策级转换,统一支持8类视觉任务: – 像素级:指代分割、实例分割; – 区域级:目标检测、视觉定位; – 图像级:多标签分类、场景分类、计数、描述生成。 -
轻量设计(仅180M参数),抛弃冗余的LLM模块,效率大幅度提升。
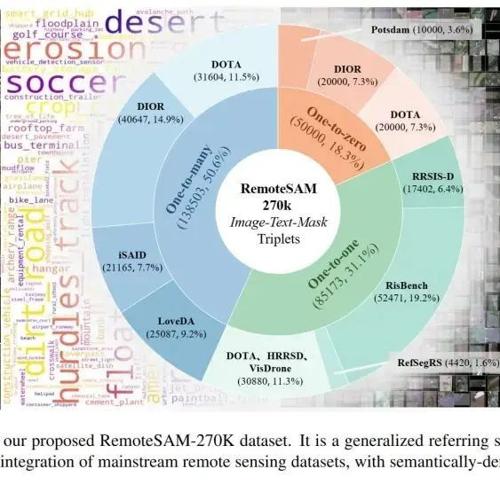
RemoteSAM-270K数据集
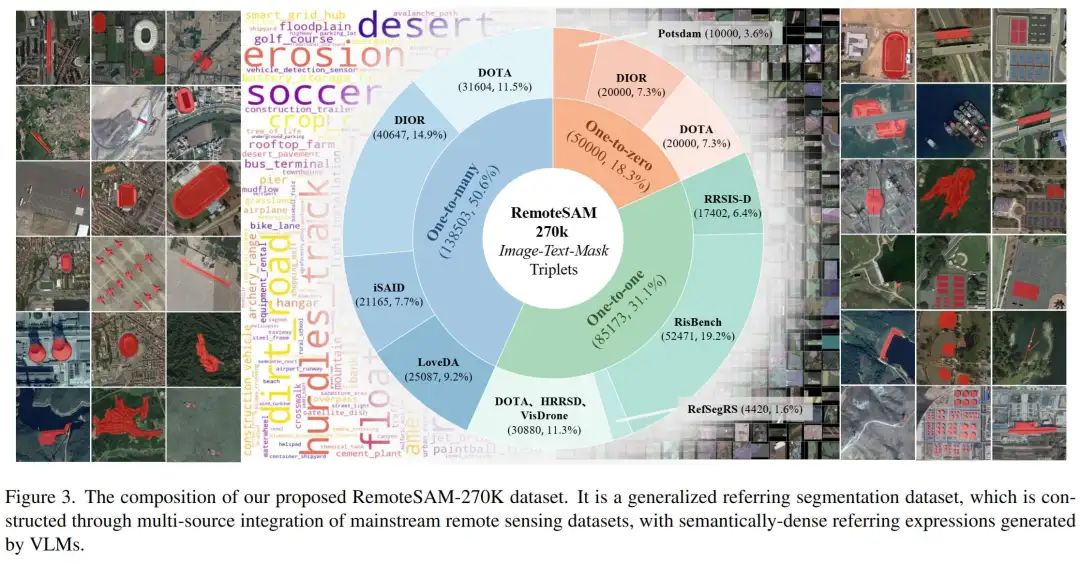
-
步骤1: 整合多源数据集(iSAID、RRSISD等) -
步骤2: Qwen2-VL-72B生成语义丰富的指代表达(如“图片最右侧停在最上面一排的黄色巴士,展示了流线型车身和专为学生交通量身定制的设计。”) -
步骤3: 混合教师模型(GroundedSAM2 + RMSIN)生成标签 -
步骤4: SigLIP计算图文相似度 → 迭代过滤低质量样本
为衡量构建数据的语义覆盖的丰富性,构建了用于衡量遥感数据集语义覆盖情况的术语库RSVocab-1K,包含了三种层级共1000种细粒度遥感目标类别。有助于后续数据集和模型的通用性分析。
RemoteSAM模型
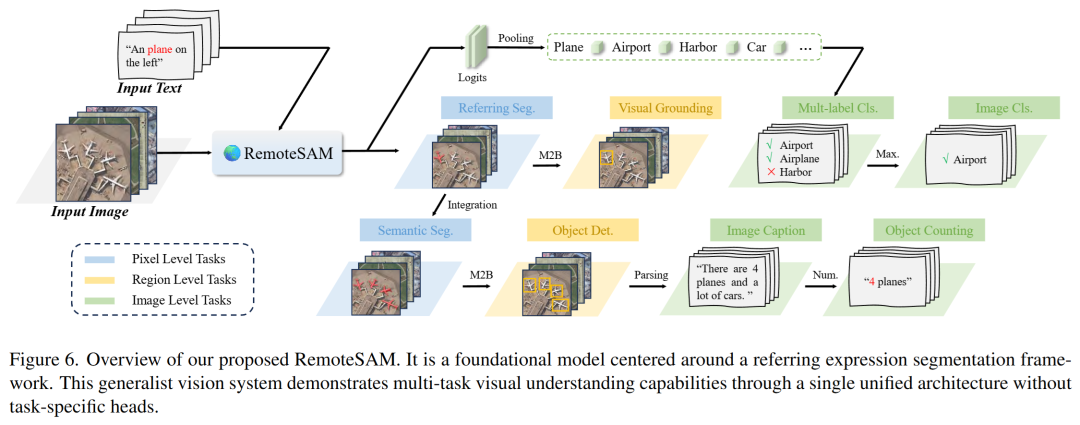
核心思想:
“一切任务始于分割”:像素级任务的掩码作为视觉最基础的输出单元,可以很顺畅的向上兼容到区域级任务和图像级任务。为了便于灵活调整,模型还需要集成自然语言理解功能。这种方法类似于“指代表达分割”任务的架构。
任务转换方法:
-
指代分割:输入「图像+文本指令」,直接输出目标像素级掩码。 -
语义分割:对每个类别生成指令(如“所有建筑”),聚合多个掩码生成全图分割结果。 -
视觉定位:将指代分割的掩码转换为目标边界框(Mask2Bbox策略,取掩码坐标极值)。 -
目标检测:先获语义分割掩码,分割粘连目标后转成独立边界框。 -
多标签分类:统计语义分割掩码中各类别的平均/最大置信度,超过阈值即判定存在。 -
图像分类:选择多标签分类中置信度最高的类别作为场景标签。 -
目标计数:统计目标检测结果中指定类别的边界框数量。 -
图像描述:结合检测框位置、类别和数量,用规则生成自然语言描述。
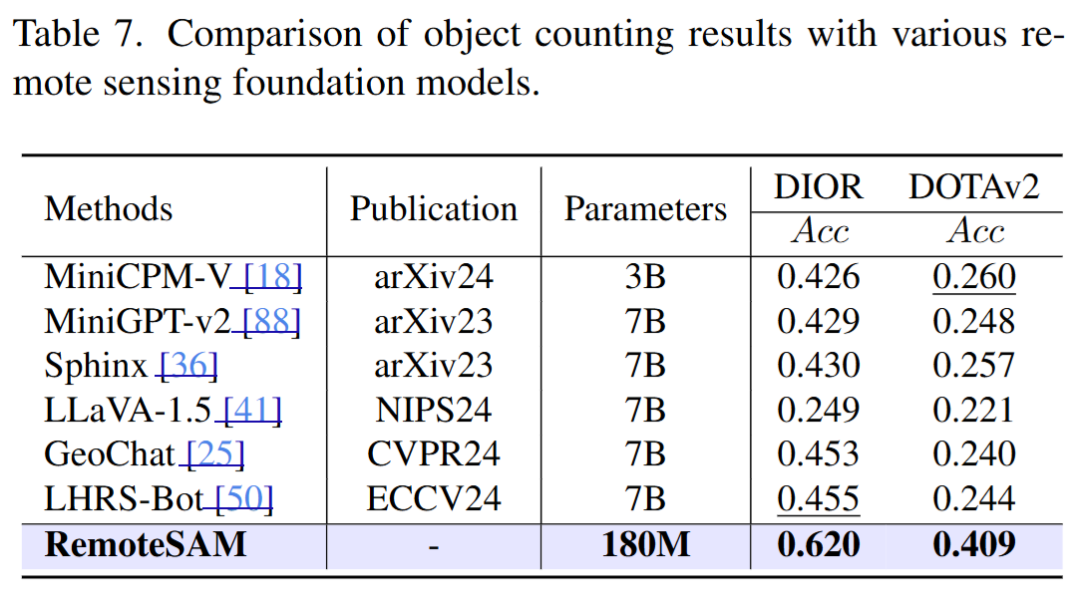
实验
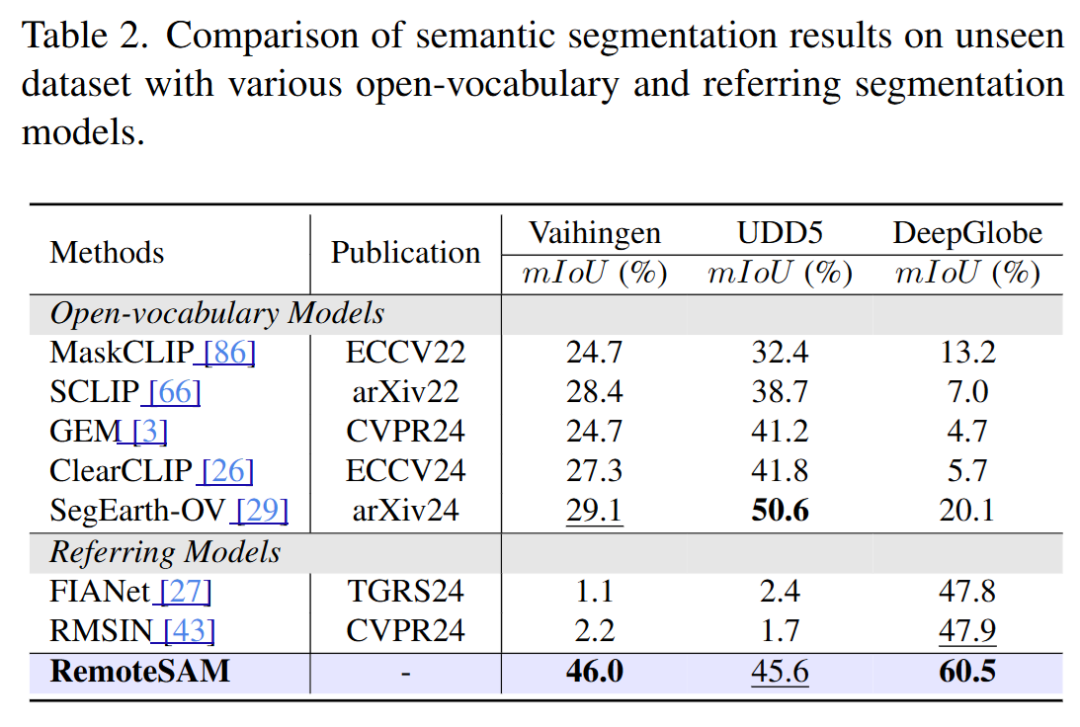
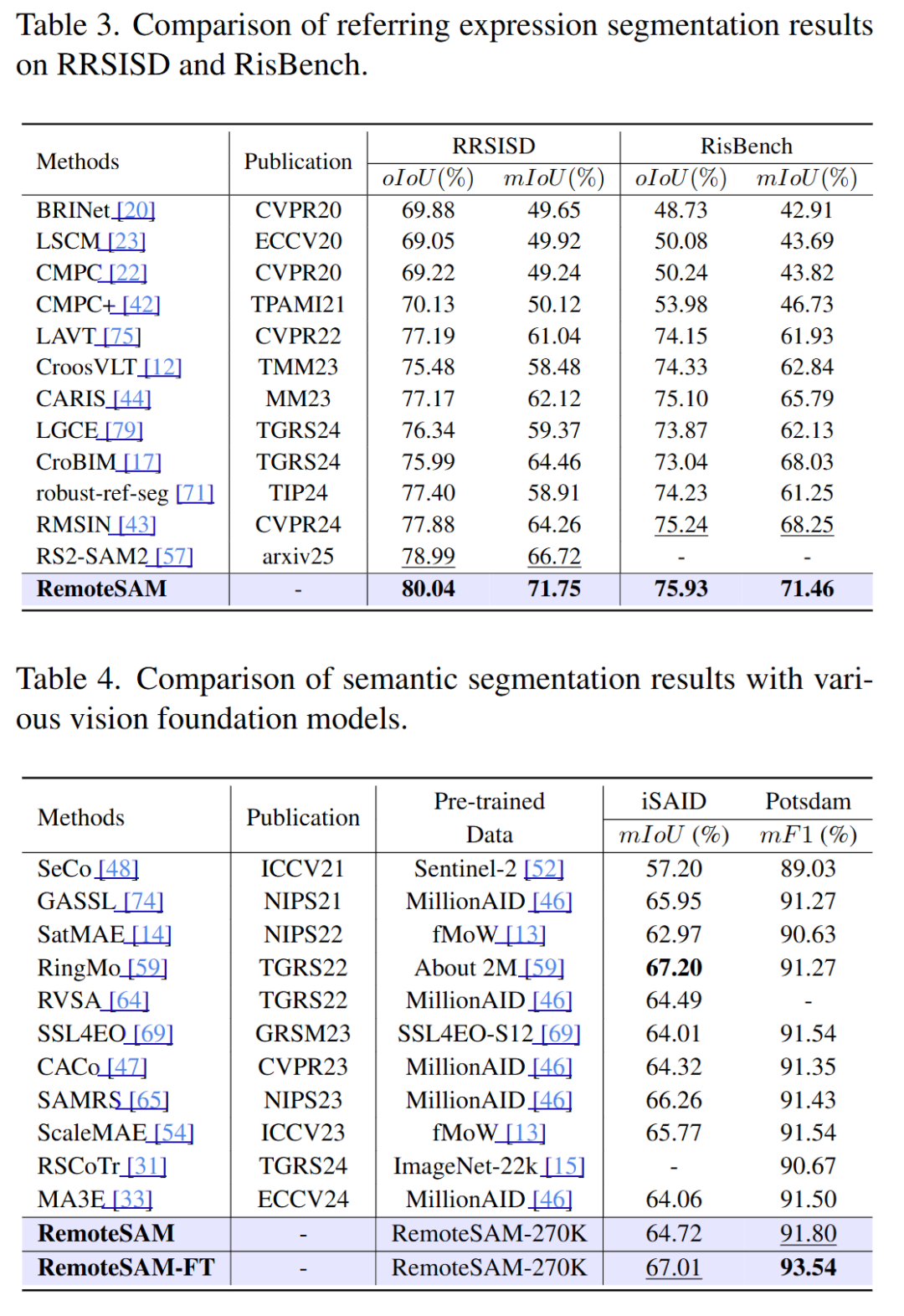
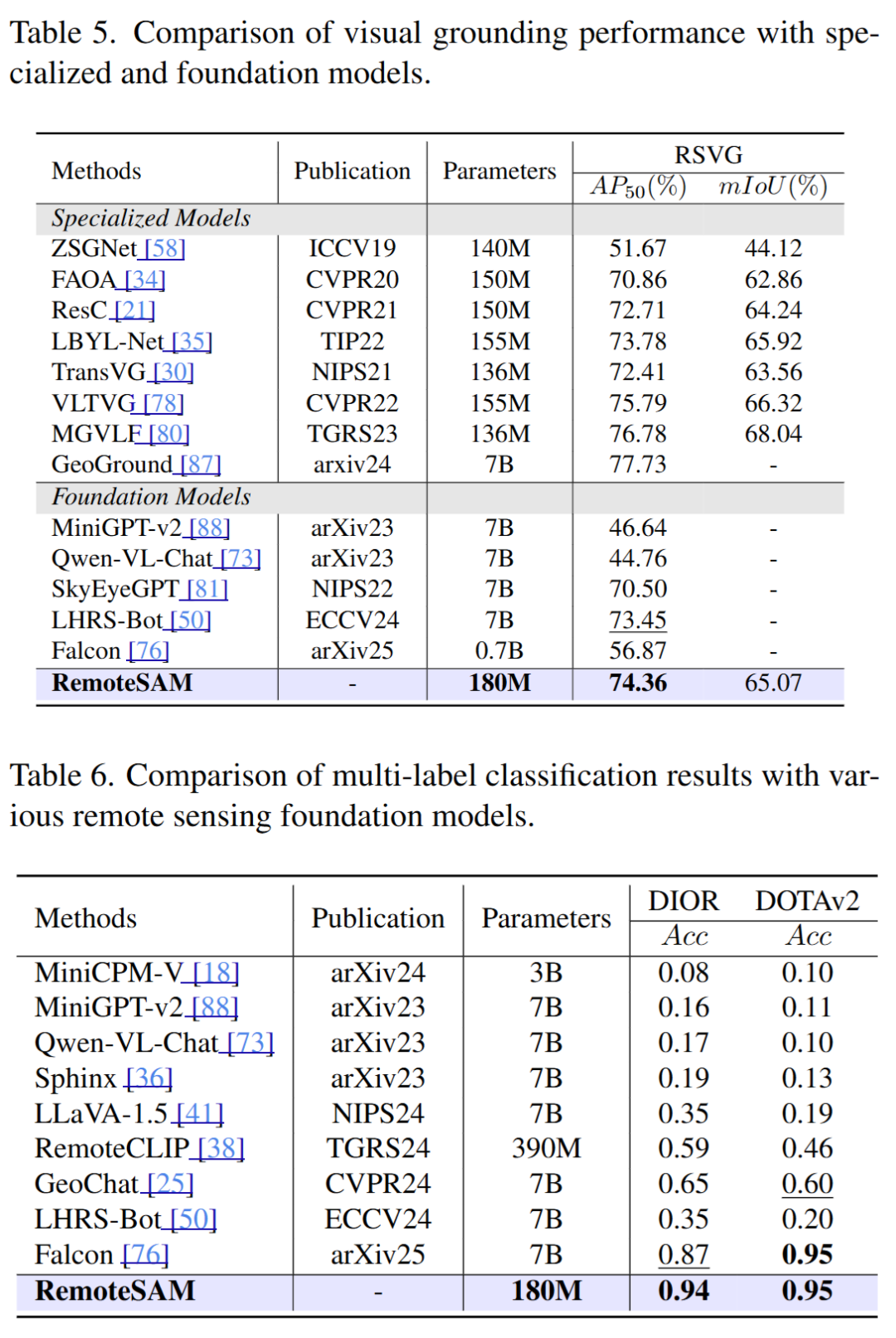
RemoteSAM在像素级、区域级和图像级任务上显著优于现有主流遥感基础模型,尤其在像素级任务上表现突出。其统一架构不仅提升了任务适应性,还大幅减少了模型参数量和训练成本。

(文:极市干货)