


MIRIX,一个由 UCSD 和 NYU 团队主导的新系统,正在重新定义 AI 的记忆格局。
在过去的十年里,我们见证了大型语言模型席卷全球,从写作助手到代码生成器,无所不能。然而,即使最强大的模型依然有一个根本性的弱点:它们不记得你。
针对这一现状,加利福尼亚大学圣迭戈分校(UCSD) 博士生 Yu Wang 和纽约大学教授陈溪(Xi Chen)联合推出并开源了 MIRIX —— 全球首个真正意义上的多模态、多智能体 AI 记忆系统。
-
论文标题:MIRIX: Multi-Agent Memory System for LLM-Based Agents
-
论文链接:https://arxiv.org/abs/2507.07957
-
官方网站:https://mirix.io/
-
开源仓库:https://github.com/Mirix-AI/MIRIX
MIRIX 的表现非常亮眼!在 ScreenshotVQA 这一需要深度多模态理解的挑战性基准上,MIRIX 的准确率比传统 RAG 方法高出 35%,存储开销降低 99.9%,与长文本方法相比超出 410%,开销降低 93.3%。在 LOCOMO 长对话任务中,MIRIX 以 85.4% 的成绩显著超越所有现有基线,树立了新的性能标杆。
不仅如此,该团队还上线了一款 Mac 端应用产品。通过这款开箱即用的应用程序,任何人都可以让 AI 看见你所看、理解你所做,并将一切转化为持久的电子记忆。
一套彻底不同的范式
回顾过去三年 AI 进化史,我们可以看到:
-
大模型推理极限:参数暴增 × 算力飙升;
-
向量检索应急:RAG 拼接碎片;
-
「短期记忆」上线:对话历史有限回看。
但所有这些,都不是「心智系统」。MIRIX 首先做到了:
-
支持多模态输入:不仅能理解文本,还能在高分辨率屏幕截图、对话日志等多源数据中构建全局记忆。
-
拥有六大类人记忆系统:每个记忆模块都有专属的数据结构、生命周期管理策略,和独立的检索路由。
-
内置多智能体协作:通过一个 Meta Memory Manager 进行总控,六个记忆 Agent 并行更新、分工检索,搭配对话 Agent 统一交互。
-
主动话题生成与分层检索:不同于「先查再答」,MIRIX 会先分析用户意图,自动生成 topic embeddings,再匹配合适的记忆类型进行多层检索。
-
产品化落地:该团队开发了一款个人助理的应用,目前已经在 Mac 端上线,可在其官方网站上下载体验。
它不再是把知识塞进「嵌入空间」,而是用结构化、多通道、可演化的方式构建认知基底。
为什么说它是 AI「心智雏形」?
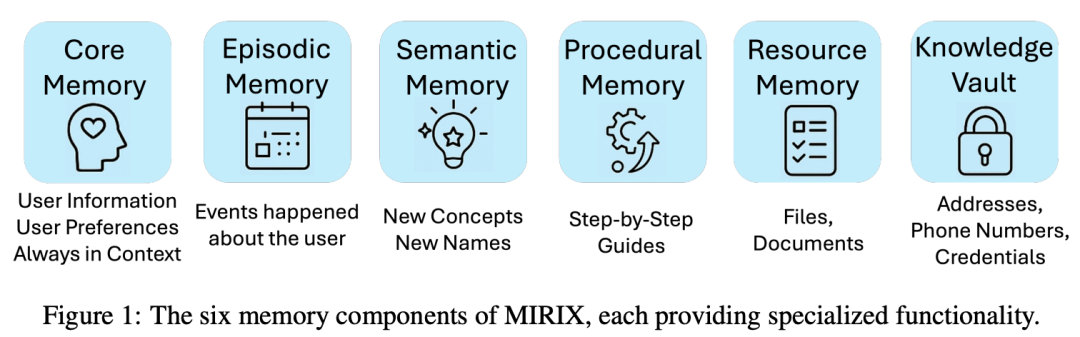
MIRIX 拥有六类核心记忆,能够细分认知角色:
-
核心记忆(Core Memory):存储 AI 的「人格」与用户长期偏好:如对话风格、偏好设定、身份信息。数据以永久 KV 对存在,优先级最高,任何回答都自动加载。
-
情景记忆(Episodic Memory):类似人类的「事件日志」,带有时间戳、事件类型、主体、简述与详情,可以追溯用户所有历史操作。
-
语义记忆(Semantic Memory):储存概念、事实和社交图谱。每条记录包含「名称、定义、详细说明、来源」四元组。支持多跳推理与知识组合。
-
程序记忆(Procedural Memory):以分步工作流形式保存任务:如「如何填写报销表」、「如何创建演示文档」。每个条目是 JSON 结构的多步操作。
-
资源记忆(Resource Memory):用于保存完整文件或截取片段,支持跨任务上下文引用。示例:用户上传的合同、会议记录、网页快照。
-
知识金库(Knowledge Vault):保存敏感信息,如密码、API Key、身份证号码,配有多级访问控制和加密机制。
以往 RAG 只能「一口气查一堆」,MIRIX 可以先理解需求,再决定在哪种记忆中搜索,再组合答案。换句话说:它会思考「我要回忆什么」,而不是机械索引。
多智能体工作流
Multi-Agent Workflow
在面向长期记忆的现代 AI 系统中,模型必须能够处理高度动态且异构的用户交互输入,这些输入既包括即时对话消息、结构化任务指令,也包括大规模多模态信息,如屏幕截图或文件。要在保证一致性、可扩展性和高效检索的前提下管理如此多样化的数据,仅依赖单一的工作流是远远不够的。
为此,该团队提出了一种模块化多智能体架构(multi-agent architecture),由若干专用组件在统一调度机制下协作完成输入处理、记忆更新和信息检索。整个系统包括:元记忆管理器(Meta Memory Manager)、记忆管理器(Memory Managers)以及对话智能体(Chat Agent)。
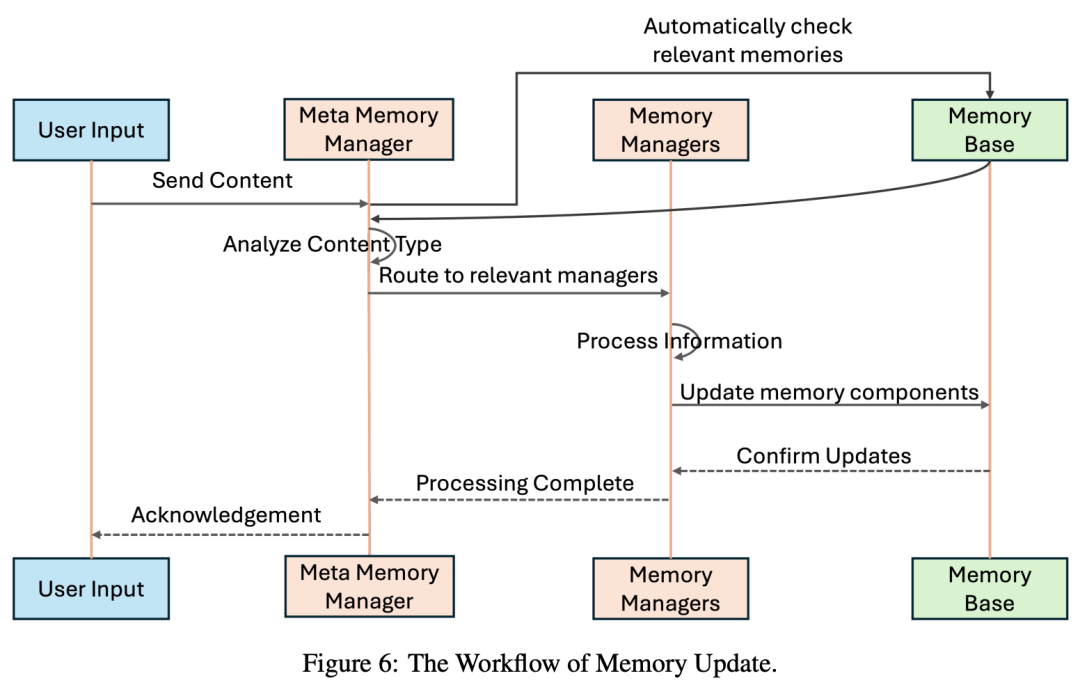
当系统接收到新的输入(如用户提供的文本、推断出的事件、上传的文件)时,会按如下流程进行处理:
-
初步检索:系统会先在现有记忆库上执行自动搜索,以检测是否存在与输入内容高度相似的记录。此步骤有助于避免冗余存储,并在必要时更新已存在条目。
-
路由与分析:检索出的相关信息与原始输入内容一同传递给元记忆管理器,由其解析内容,提取元数据(如时间戳、来源类型、相关性评分),并判断哪些记忆组件需要更新。
-
并行更新:元记忆管理器将输入内容分发给各个相关的记忆管理器。每个管理器独立完成以下操作:(1)提取结构化字段(例如摘要、详情、事件参与方)(2)去重或合并相似记录(3)更新索引和嵌入表示,供后续检索使用
-
完成确认:当所有相关记忆管理器完成更新后,它们将状态反馈给元记忆管理器,系统再向外发送确认,表明本次记忆更新已结束。
对话检索流程
Chat Workflow
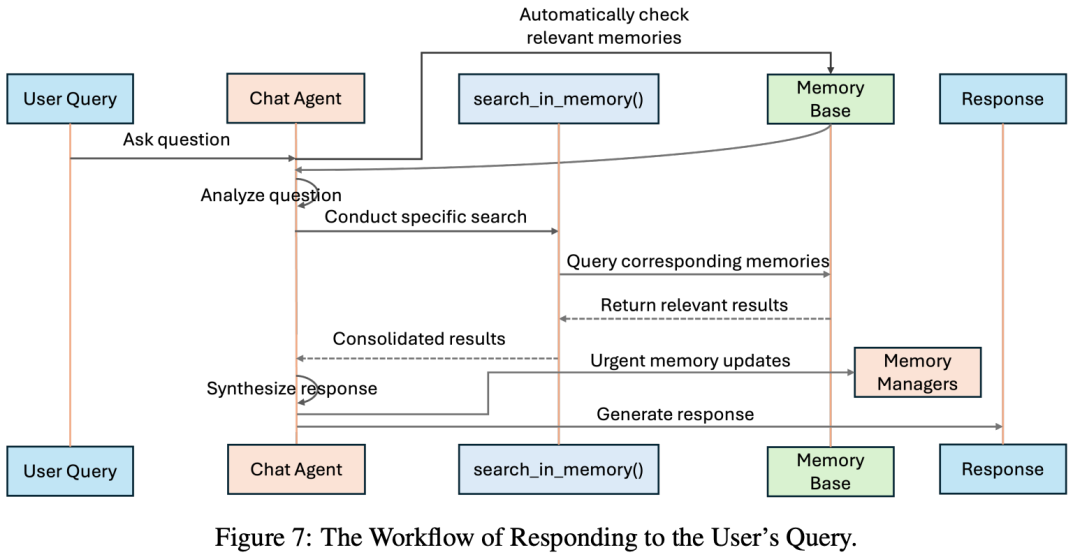
在交互式对话场景下,检索流程主要分为以下步骤:
-
粗检索:当接收到用户查询时,对话智能体首先会在所有六个记忆组件中执行一次粗粒度检索,返回高层级的摘要或元数据信息,用于判断记忆分布。
-
目标检索选择:对话智能体基于粗检索结果和查询内容进行分析,例如:若问题为操作性流程(如「如何提交报销单?」),则聚焦程序记忆;若问题为事实性回顾,则主要面向情景记忆或语义记忆。
-
精细检索:针对确定的目标记忆组件,系统会使用更精准的检索策略,包括:基于嵌入向量的相似性搜索;BM25 文本相关性排序;关键字匹配。
-
结果整合与答案生成:检索结果会带上来源标签(如 <episodic_memory>),与用户问题一同输入模型生成提示(system prompt),由模型生成最终回答。
-
交互式更新:如果用户的查询涉及记忆修改(如添加新信息或纠正历史记录),对话智能体会即时与对应的记忆管理器进行交互,完成更新操作。
这一流程确保了系统的回答不仅有一致性,也能根据最新知识动态调整。
性能突破
碾压 RAG Baseline 以及其他 memory 系统
在该团队新构建的多模态极限任务 ScreenshotVQA 里,MIRIX 存储占用相比 RAG 降低 99.9%,然而精准率比 RAG 高 35%;相比全上下文推理,存储缩小 93.3%,准确率提升 410%!
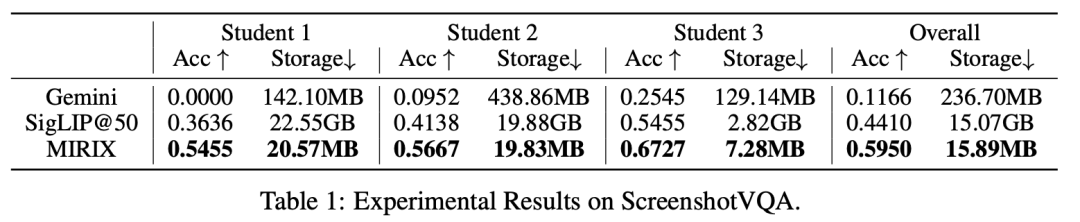
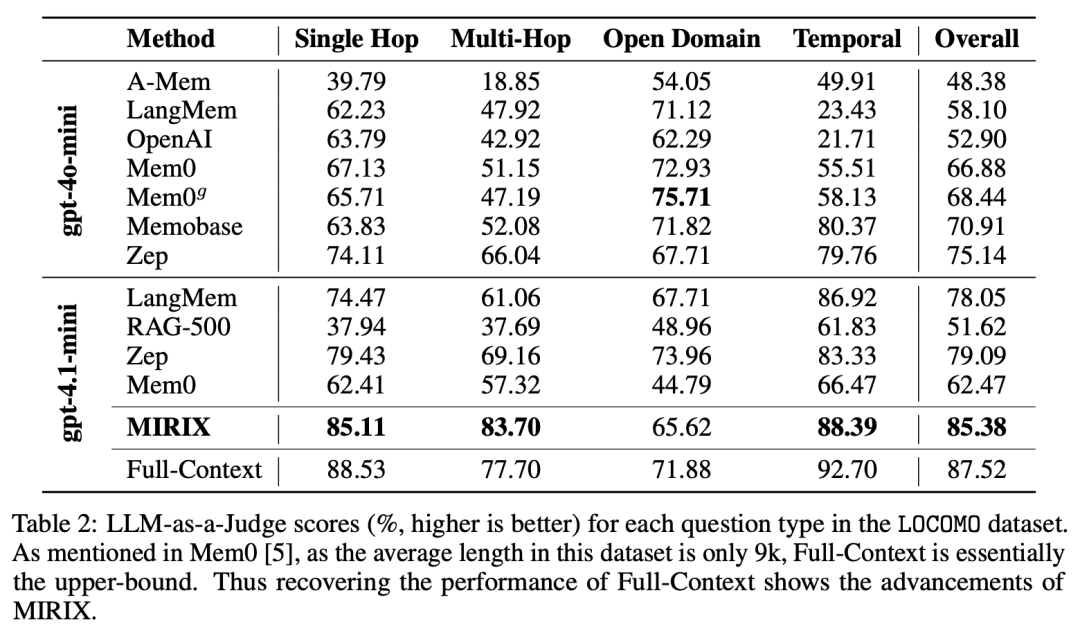
在 LOCOMO 多轮对话推理任务中,综合准确率达到 85.4%,远超一众现有模型,包括 MemOS,Mem0 等;在多跳问题胜过所有开源基线。综合性能几乎接近全上下文模型(由于 gpt-4.1-mini 的上下文窗口为 1M,它的 LOCOMO 性能几乎是上限)。
这不仅是「更好」
更是「完全不同」
用 MIRIX 团队的话说:「检索增强生成只是临时补丁。真正的记忆,要让 AI 在时间维度上成长」。 这是大模型迭代的新周期:从「对话生成」走向「长期记忆驱动心智」。
此外,MIRIX 不只是论文,MIRIX 团队同步上线了桌面版个人助理应用,可实现即时多模态数据采集,并将记忆进行可视化树状记忆管理,并且将 memory 存于本地 SQLite 中保护隐私,即刻安装,体验 AI 首次「真正记住你」。

©
(文:机器之心)