

极市导读
本文提出了一种基于正交子空间分解的新方法,有效解决了 AI 生成图像检测中的泛化难题,显著提升了检测模型的泛化能力,为 AI 安全和生成图像识别提供了新的思路。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?尽管目前有很多研究已在尝试解决这个挑战,然而这个挑战深层次的泛化难题一直没有得到合理的探究,生成图像和真实图像的区别真的是简单的 「真假二分类 」吗?
近日,北京大学与腾讯优图实验室等机构的研究人员针对这一泛化难题做了一些深层次的探究,研究表明 AI 生成图像检测任务远比 「真假二分类 」复杂!这里基于正交子空间的分解对该挑战提出了一种新的解决思路,实现了检测模型从 「记忆式背诵」 到 「理解式泛化」 的跨越,显著提升 AI 生成图像检测的泛化能力,具有理论深度与实践价值的双重突破。论文被 ICML2025 接收为 Oral (TOP ~1%)。

-
论文题目:
Orthogonal Subspace Decomposition for Generalizable Al-Generated Image Detection -
论文地址:https://openreview.net/pdf?id=GFpjO8S8Po
-
代码链接:https://github.com/YZY-stack/Effort-AIGI-Detection
文章摘要
我们设计了一种新的基于正交分解的高效微调方法,既保留原有大模型原有的丰富预训练知识,又 「正交」 地学习下游任务相关的新知识。同时,我们对当前检测模型泛化性失效的原因给出了深入的量化分析,最后也总结了一些能够泛化性成功的关键 Insight。
解决了什么问题
随着 AIGC 的爆火,区分生成图像和真实图像十分重要,无论是对 AI 安全还是促进生成(类似 GAN)都有益处。在该工作中,我们发现,AI 生成图像(AIGI)检测中的真假(Real-Fake)二分类,与普遍、标准的 「猫狗二分类」 不同的是,AIGI 的二分类是不对称的,即如果直接训练一个检测器,模型会非常快的过拟合到训练集里固定的 Fake Patterns 上,限制了模型对未见攻击的泛化性,如图 1 所示。
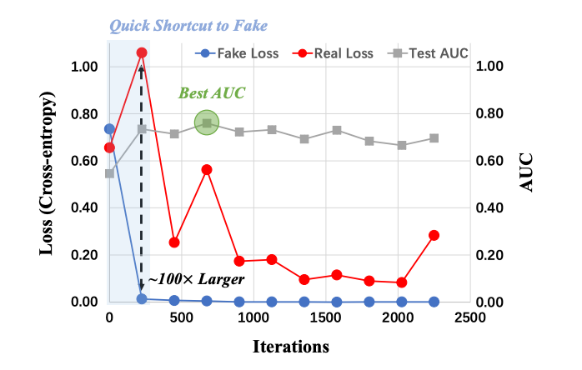
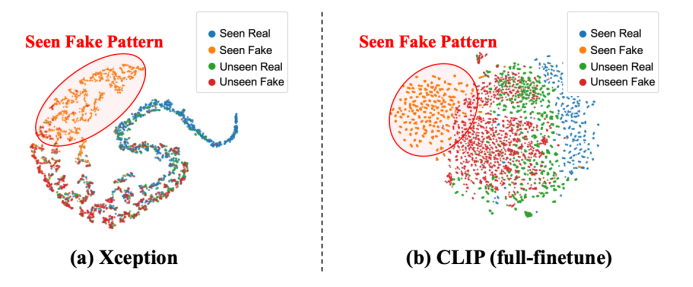
由于模型快速过拟合到了训练集里的 Fake 上,整体学习到的知识就会被训练集固定的 Fake Pattern 主导,但由于训练集里 fake 的单一性,导致整个模型的特征空间变得非常低秩(Low-Ranked)且高度受限(Highly Constrained),这也被现有工作证实,会限制模型的表达能力和泛化能力。图 2 是我们对现有直接做简单二分类的传统方法得到的模型特征的 t-SNE 分析图,可以看到 Unseen Fake 和 Unseen Real 被混杂在一起无法区分。
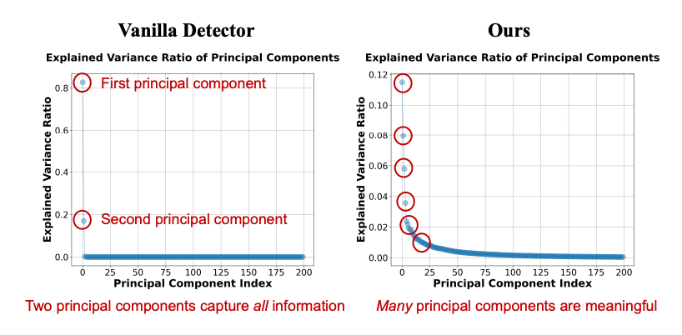
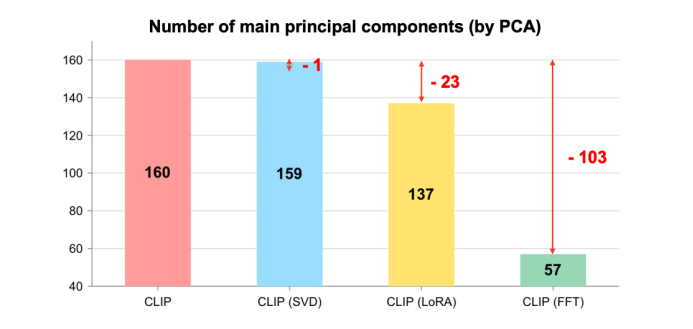
接下来是具体量化分析结果,图 3 是我们对模型特征做了主成分分析(PCA)可视化,可以发现传统方法的特征空间的解释方差比率(Explained Variance Ratio)主要集中在前两个主成分上,这导致特征空间其实是低秩的。图 4 是我们用 PCA 主成分数量来量化模型的过拟合情况,可以发现无论是直接微调 CLIP 还是通过 CLIP+LoRA 的方式在 fake 检测任务上微调,都会导致模型预训练知识的遗忘(PCA 主成分数量显著降低)。
解法与思路
我们提出了一种基于 SVD 的显式的正交子空间分解方法,通过 SVD 构建两个正交的子空间,Principal 的主成分(对应 Top 奇异值)部分负责保留预训练知识,Residual 的残差部分(「尾部」 奇异值)负责学习新的 AIGI 相关知识,两个子空间在 SVD 的数学约束下严格正交且互不影响(图 5)。
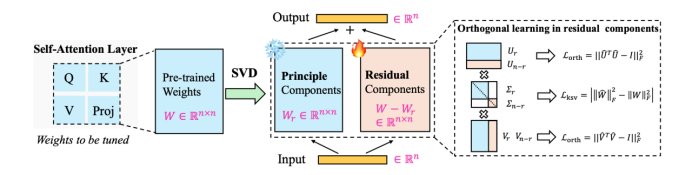
图 6 是具体整个方法的算法流程,其主要对 ViT 模型每一层 Block 的线性层参数进行 SVD 分解,我们保留其奇异值较大的参数空间不动,微调剩余奇异值对应的参数空间,除了真假二分类损失函数外,这里还施加了两个正则化约束损失函数来限制微调的力度。

实验效果
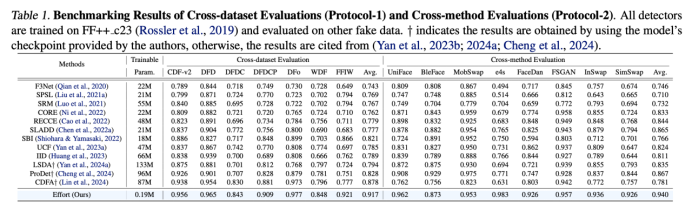
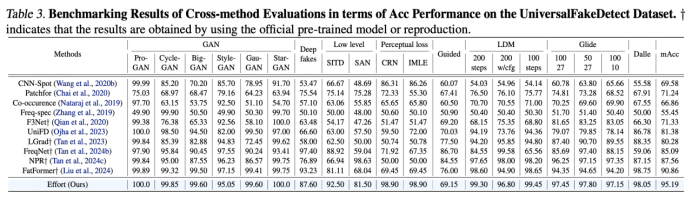
通过我们提出的上述方法,能维持高秩的模型特征空间,最大程度的保留了原来的预训练的知识,同时学到了 Fake 相关的知识,因此取得更好的泛化性能。我们在 DeepFake 人脸检测和 AIGC 全图生成检测两个任务中均取得不错效果(表 1、表 2)
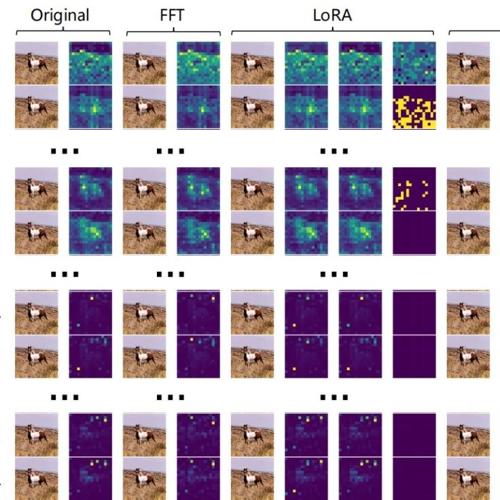
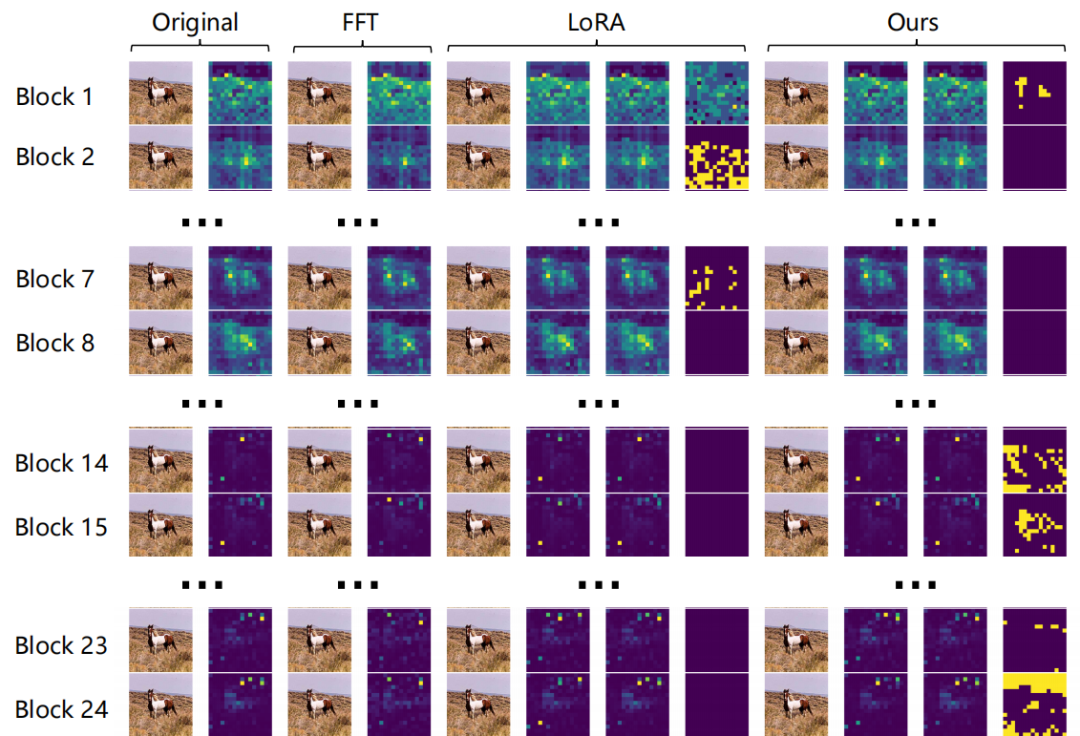
此外,如图 7 所示,我们对原始的 CLIP-ViT 模型(Original)、全微调的 CLIP-ViT 模型(FFT)、LoRA 训练的 CLIP-ViT 模型(LoRA)以及我们提出的正交训练的 CLIP-ViT 模型(Ours)的自注意力图(Attention Map)进行了可视化。具体来说,从上到下是逐层 block 的自注意力图。对于 LoRA 而言,自注意力图从左到右依次使用原始权重 + LoRA 权重、原始权重、LoRA 权重生成的。对于我们的方法而言,自注意力图从左到右依次使用主成分权重 + 残差权重、主成分权重、残差权重生成的。这里,我们观察到语义信息主要集中在浅层的 Block 中,而我们提出的方法在自注意力图层面上确实实现了语义子空间与学习到的伪造子空间之间的正交性。这进一步说明了我们的方法能够在学习 Fake 特征的同时,更好地保留预训练知识。
启发与展望
虽然检测任务表面上看是一个 Real 与 Fake 的二分类问题,但实际上 Real 与 Fake 之间的关系并不像猫狗分类那样完全独立,而是存在层级结构。也就是说,Fake 是从 Real 「衍生」 而来的。掌握这一关键的强先验知识,是检测模型实现良好泛化的核心原因。相反,如果像训练猫狗分类器那样简单地训练二分类模型,容易导致模型过拟合于固定的 Fake 特征,难以捕捉到这一重要的先验信息。
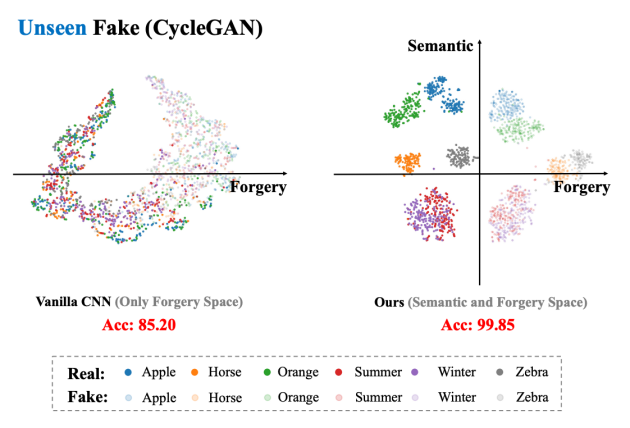
见图 8,模型(右侧)可以把不同的类别(Semantic 相同)聚到一起,并在每个 Semantic 子类别里做判别(假苹果 vs 真苹果),大大减小了判别复杂度,进而可以提升模型的泛化性(Rademacher Complexity 理论),这强调了语义对齐的重要性,即在一个对齐的语义子空间里(例如苹果的子空间里)区分 Real 和 Fake,可以大幅降低判别的复杂度,进而保证模型的泛化性。
在 AI 生成图像日益逼真的今天,如何准确识别 「真」 与 「假」 变得尤为关键。传统方法依赖训练集内的 Fake Pattern 匹配,该研究通过正交子空间分解,使模型能在真实图像的语义先验的基础上判别 Fake 信息,解决了生成图像检测中跨模型泛化性差的核心难题。此外,该研究成果提出的正交分解框架,还可迁移至其他 AI 任务(如微调大模型、OOD、域泛化、Diffusion 生成、异常检测等等),为平衡模型已有知识与在新领域的适应性提供了新的范式。
(文:极市干货)