
OpenAI的realtime多模态大模型,大家是不是已经体验过了,国内也有几家大厂做了类似的多模态视觉、语音交互大模型。
今天看到一个牛的开源项目,直接把GPT4o级别的实时视觉和语音交互模型开源了。
先感谢作者!感谢南京大学AI团队!
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)


项目简介
VITA-1.5 是一款开源的交互式多模态大型语言模型,实现接近实时的视觉和语音交互体验。相较于之前的VITA-1.0版本,VITA-1.5 在多个方面取得了显著进步。VITA-1.5 还采用了渐进式训练策略,确保在加入语音模态时,对其他多模态性能的影响最小化。该模型支持中英文两种语言,适用于多种应用场景。
DEMO
如果看到这,你还不知道VITA是什么,看下视频就懂了。
而且它真的很强,跟我在用GPT4o实时视频模型的体验差不多。
VITA-1.5功能特点
-
显著降低交互延迟。端到端的语音交互延迟已从大约4秒降低到1.5秒,实现了近乎即时的交互,并极大地提升了用户体验。
-
多模态性能增强。在MME、MMBench和MathVista等多模态基准测试中的平均性能显著提高,从59.8提升到70.8。
-
语音处理能力提升。语音处理能力已提升到新的水平,ASR WER(词错误率,测试其他)从18.4降低到7.5。用了一个端到端的TTS模块替换了VITA-1.0的独立TTS模块,该模块接受LLM的嵌入作为输入。
-
渐进式训练策略。通过这种方式,添加语音对其他多模态性能(视觉-语言)的影响很小。平均图像理解性能仅从71.3下降到70.8。
实验结果
-
在图像和视频理解基准测试中的评估。
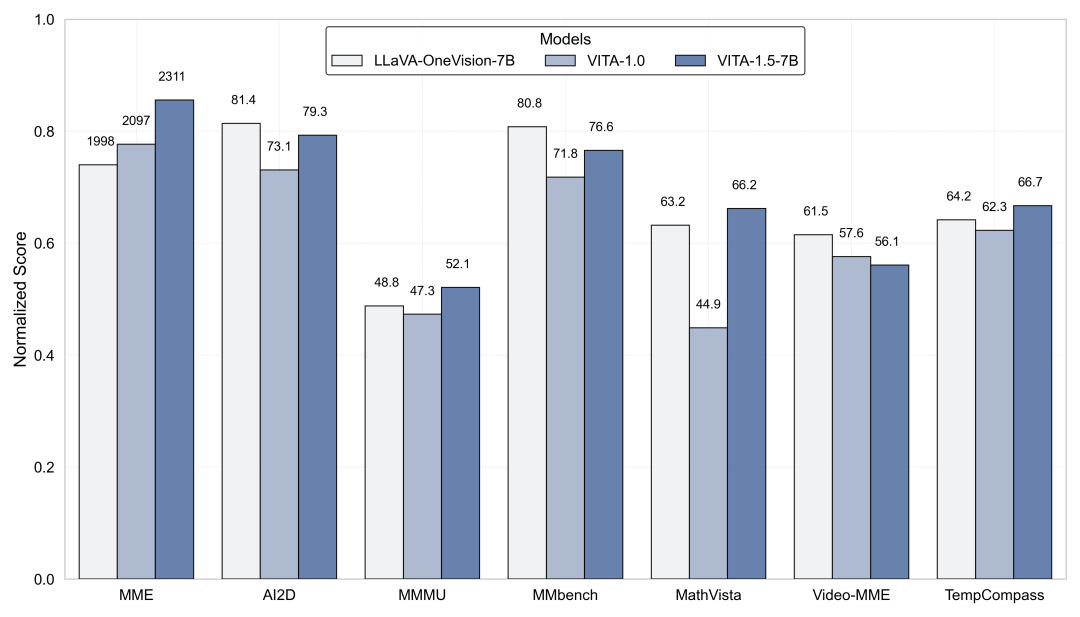
-
VITA-1.5在ASR基准测试中超越了专业的语音模型。
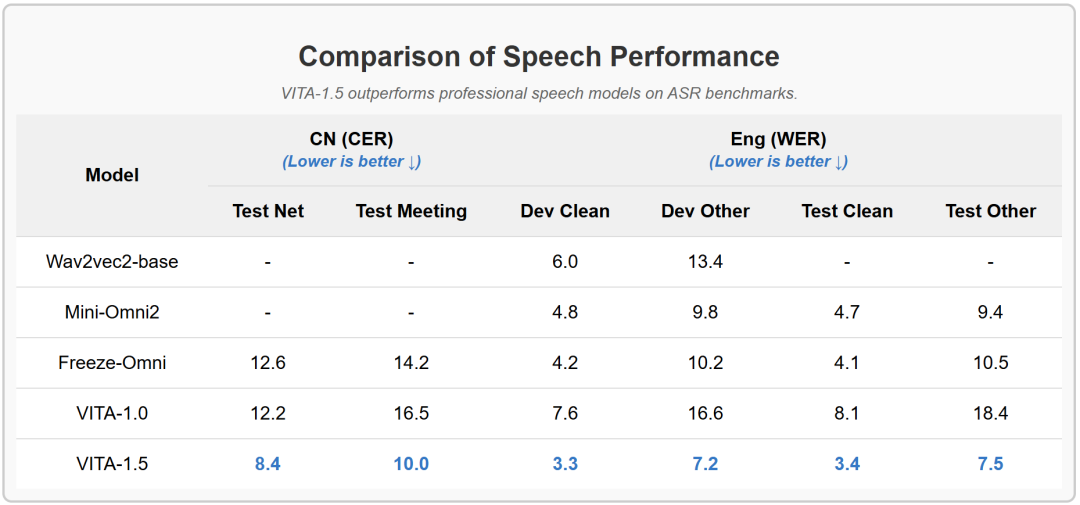
-
添加音频模态对图像和视频理解能力的影响很小。
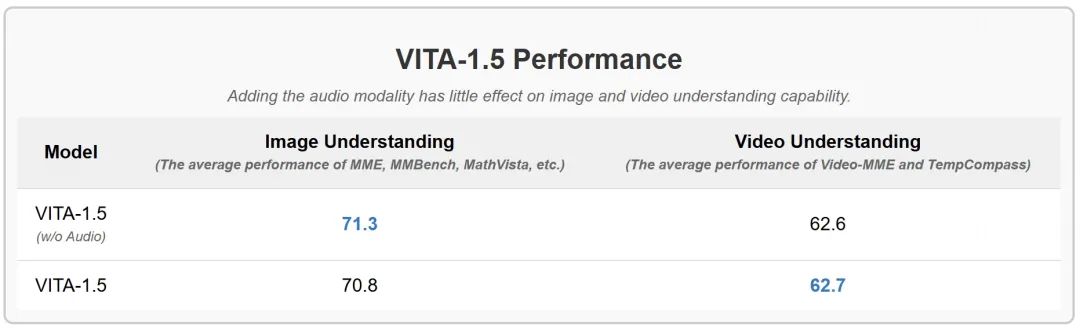
项目链接
https://github.com/VITA-MLLM/VITA
关注「开源AI项目落地」公众号
(文:开源AI项目落地)