
人大赵鑫教授团队出品,深入学习大语言模型!

Datawhale发布《大语言模型》中文书籍,系统介绍大语言模型技术。作者团队包括赵鑫、李军毅、周昆等专家,引用次数已突破4000次。该书注重为读者提供系统性的知识讲解,内容涵盖预训练、微调、对齐等多种基础内容。
Datawhale发布《大语言模型》中文书籍,系统介绍大语言模型技术。作者团队包括赵鑫、李军毅、周昆等专家,引用次数已突破4000次。该书注重为读者提供系统性的知识讲解,内容涵盖预训练、微调、对齐等多种基础内容。

蔡崇信在迪拜世界政府峰会上讨论了AI竞赛的观点,并强调AI应优先应用于解决现实问题。他提到了DeepSeek的成本节约创新以及开源AI对民主化的重要性。他还提到了阿里巴巴与中国Apple的合作,指出智能手机需要高效的小型AI模型。

论文提出原生稀疏注意力(NSA)技术,有望大幅提升大语言模型处理长文本的能力和效率。NSA结合动态分层稀疏策略与硬件优化,显著提升计算速度并在训练中支持端到端训练。实验表明使用NSA预训练的模型在多个任务上性能超越Full Attention模型,并且在64k长度序列下实现显著加速。
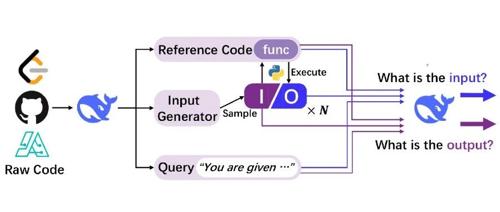
DeepSeek团队通过CODEI/O项目,利用300多万个实例将代码转换为思考过程训练大模型,提升其在多种推理任务中的性能,并证明了这种训练方法对不同规模和领域模型的有效性。





