多模态推理新基准!最强Gemini 2.5 Pro仅得60分,复旦港中文上海AILab等出品
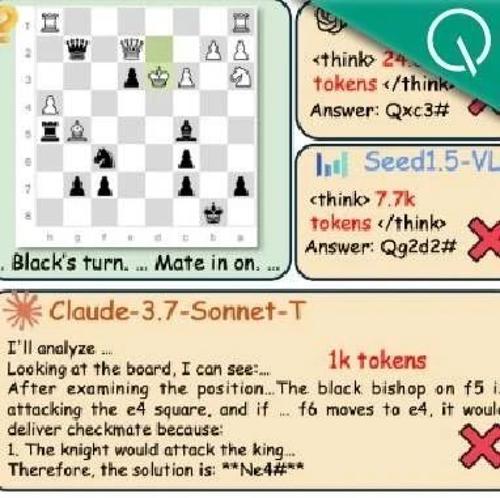
复旦大学及香港中文大学MMLab联合上海人工智能实验室等多家单位提出了MME-Reasoning,全面评估多模态大模型的推理能力。该基准分为三类推理:演绎、归纳和溯因,并涵盖三种问题类型。评测结果显示当前最优模型得分仅60%左右,显示了对逻辑推理能力的要求极高。
复旦大学及香港中文大学MMLab联合上海人工智能实验室等多家单位提出了MME-Reasoning,全面评估多模态大模型的推理能力。该基准分为三类推理:演绎、归纳和溯因,并涵盖三种问题类型。评测结果显示当前最优模型得分仅60%左右,显示了对逻辑推理能力的要求极高。

一项新研究表明,大模型在在线辩论中比人类更具说服力。该研究指出,在了解对手个人信息的情况下,使用GPT-4的参与者有更高的概率改变观点。研究还显示,大模型写作风格具有显著特征,易被察觉。专家呼吁加强监管,防止大模型用于操纵舆论。

研究团队提出VL-Rethinker模型,通过优势样本回放和强制反思技术解决多模态推理中的优势消失和反思惰性问题。该模型在多个数学和科学任务上超过GPT-o1,并显著提升Qwen2.5-VL-72B在MathVista和MathVerse上的性能。

ElevenLabs发布的新版TTS模型Eleven v3支持70多种语言,还能进行多人对话聊天。它通过引入音频标签控制情绪表达,并且已进入内部测试阶段。

谷歌今日突袭推出Gemini 2.5 pro的重磅更新版本Gemini 2.5 Pro Previe

SophiaVL-R1 是一项基于类 R1 强化学习训练框架的新模型,它不仅奖励结果的准确性,还考虑了推理过程的质量。通过引入思考奖励机制和 Trust-GRPO 训练算法,SophiaVL-R1 提升了模型的推理质量和泛化能力,在多模态数学和通用测试数据集上表现优于大型模型。