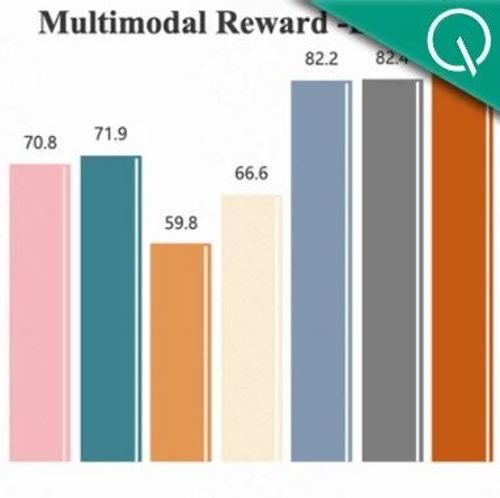
RL训练总崩溃?R1-Reward稳定解锁奖励模型Long-Cot推理能力 2025年5月9日16时 作者 PaperWeekly 可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evalua
突破多模态奖励瓶颈!中科院清华快手联合提出R1-Reward,用强化学习赋予模型长期推理能力 2025年5月8日16时 作者 量子位 态大语言模型(MLLMs)的表现中起着至关重要的作用: 在训练阶段,它可以提供稳定的reward;