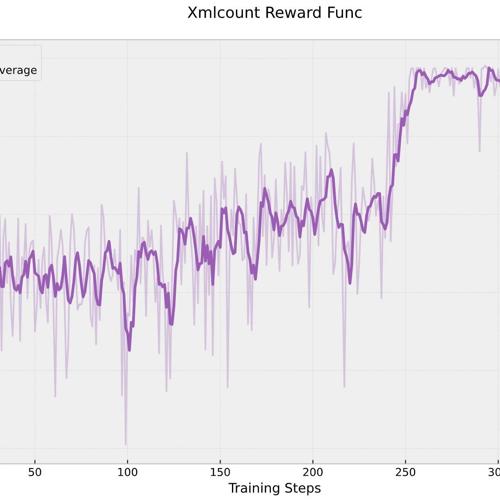
DeepSeekRL-Extended:从零实现DeepSeek R1的强化学习项目 2025年2月18日8时 作者 NLP工程化 从零实现DeepSeek R1的强化学习项目,探索GRPO算法的应用,仅用单个H100 GPU400步训练提升模型性能,完全自研且提供多脚本结构。