
Understand-R1-Zero:深入剖析R1-Zero类训练方法
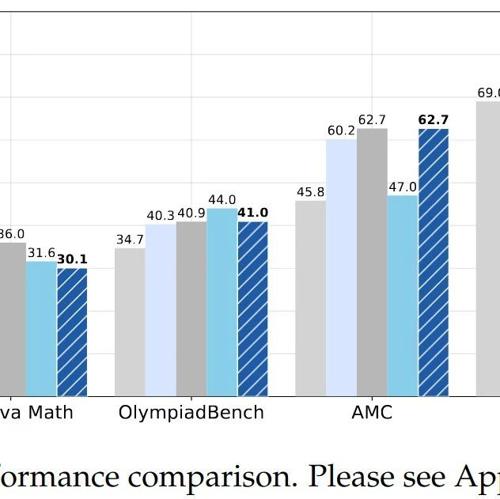
深入剖析R1-Zero训练方法,发现其已展现‘灵光一现’现象,并提出Dr. GRPO算法优化强化学习过程。仅用8×A100 GPU在27小时内实现SOTA性能。
深入剖析R1-Zero训练方法,发现其已展现‘灵光一现’现象,并提出Dr. GRPO算法优化强化学习过程。仅用8×A100 GPU在27小时内实现SOTA性能。

新加坡国立大学与海航人工智能实验室团队提出了一篇关于R1-Zero-like训练的新论文。文章详细分析了基座模型和强化学习(RL)两大基石,并指出现有方法可能存在偏见问题,提出了改进方案。