
AI硬件的“DeepSeek时刻”,小智AI为何突然火爆?

过去两个月内,小智AI凭借其低门槛和开源特性迅速爆火,吸引了大量用户参与并开发各种应用场景。目前其日活跃用户数约在1.5-2万之间,预计将继续保持免费策略以吸引更多开发者和用户。
过去两个月内,小智AI凭借其低门槛和开源特性迅速爆火,吸引了大量用户参与并开发各种应用场景。目前其日活跃用户数约在1.5-2万之间,预计将继续保持免费策略以吸引更多开发者和用户。
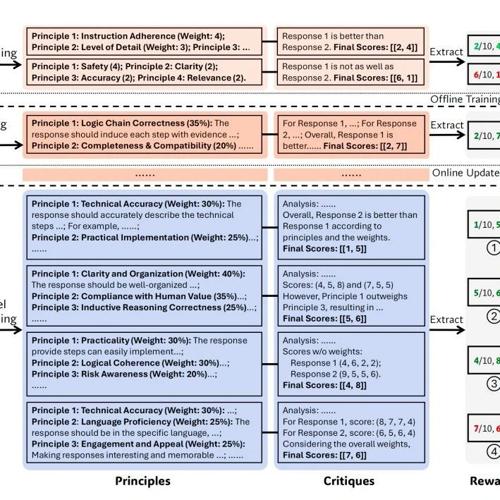
近日,DeepSeek和清华大学提出了一种新的训练方法SPCT(Self-Principled Critique Tuning),用于提升点式生成式奖励建模(GRM)的质量和可扩展性。该方法通过让模型学会先定原则、再写点评来改进通用RM的准确性,并实现了推理阶段的可扩展性提升。

OpenAI 推出的 GPT-4o 是一个原生多模态模型,能够直接从文本提示生成精确、逼真的图像。它在准确渲染文本、精确遵循提示以及利用固有知识库和聊天上下文方面表现出色。

埃隆·马斯克在白宫接受采访时预测,未来10年内人工智能的认知能力可能会超过人类,并预计会有大量人形机器人出现。他强调需要重视国内人工智能芯片制造能力的建设。

百度发布文心大模型4.5和X1,价格分别为0.004/0.016元/千tokens和0.002/0.008元/千tokens。文心4.5在多模态任务上表现优异,而文心X1能自主运用工具并具备更强的理解、规划、反思能力。

阶跃星辰在上海举办首届Step UP生态开放日,透露多模态推理和Agent智能体技术作为未来重点关注方向,并发布全新升级的‘繁星计划’2.0。

芜湖!机器人开始走出实验室,走进家庭,能做家务了。Figure的最新研究成果——视觉-语言-动作(VLA)模型Helix,让两台搭载该模型的机器人共享同一智能大脑,通过自然语言指令进行分工合作。


