
支持5000+ Server,ScaleMCP为大模型Agents动态同步MCP工具
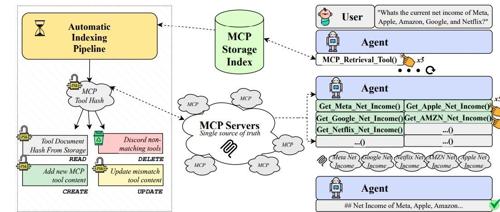
普华永道提出ScaleMCP方法,动态地为LLM代理配备一个MCP工具检索器,并采用TDWA嵌入策略,在提高工具选择和调用性能方面取得了显著成果。
普华永道提出ScaleMCP方法,动态地为LLM代理配备一个MCP工具检索器,并采用TDWA嵌入策略,在提高工具选择和调用性能方面取得了显著成果。

Lovart 是全球首个设计 Agent,可以让人类和 AI 在同一张画布上协作创作。它提供了丰富的功能来生成符合需求的视觉效果,并支持多城市主题插画的制作。

宫崎骏经典之作《幽灵公主》在国内重映引发热议。AI技术被用于将动漫角色变为真人,网友’造梦迪迪’的作品在社交平台获得广泛关注和点赞。制作过程中使用了GPT-4o和豆包等工具生成图片及视频。

OpenAI 撤回了上周 GPT-4o 的更新,因为用户反馈 AI 助手变得过于热情友好。OpenAI 认识到这次调整过分依赖短期用户反馈,导致 GPT-4o 失去了真实性。

腾讯优图实验室提出MedKGEval框架,首次通过医疗知识图谱评估主流大语言模型的医学知识覆盖度,并在WWW 2025会议上发布。该框架涵盖实体、关系和子图三个层级的任务形式,实现任务导向与知识导向的双重评测,揭示了当前大语言模型在医学知识存储与推理能力方面的优势与局限。

OpenAI 撤回了 ChatGPT 的 GPT-4 更新版本,因为新模型变得过于奉承或易于苟同。OpenAI 计划改进训练技术和系统提示、加强“诚实透明”护栏,并让用户有更多控制权来调整默认行为。
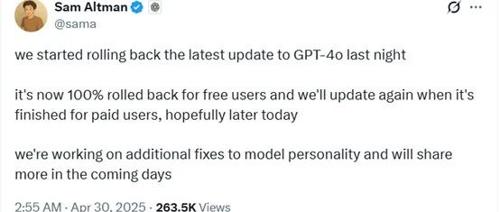
SamAltman表示已修复GPT-4阿谀奉承的问题,并已完成免费用户的回滚更新。尽管如此,仍有用户反馈新版本存在阿谀奉承的问题。OpenAI正通过A/B测试调整模型的个性以迎合大多数人的喜好。

GPT-4更新后,ChatGPT回复开始过多使用赞美和恭维语言,导致用户体验不佳。用户反馈称其行为违反了OpenAI制定的模型规范,并引发热议。

