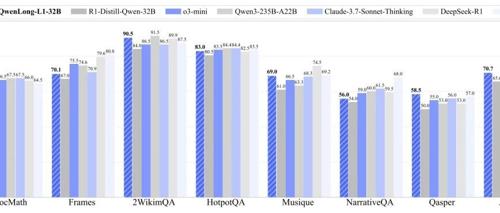
阿里开源QwenLong-L1:首个以强化学习训练的长上下文推理大模型 2025年5月28日14时 作者 PaperAgent 阿里开源的QwenLong-L1框架通过强化学习训练提升了长文本情境推理能力,优于OpenAI-o3-mini等旗舰LRMs,在七个长上下文DocQA基准上表现优异。