

鹏城实验室研发的“鹏城·脑海”大模型多语言版PengCheng.Mind-m1正式对外开源测试。该模型以实验室“鹏城·云脑II”超大规模国产智能算力集群为计算平台,以“鹏城·脑海”中文通用大语言模型为内核,使用高质量多语言数据增强训练而成,是一款以中文为中心、支持53种语言的多语言大模型。PengCheng.Mind-m1的多语言翻译和理解能力已达到或超过业界主流产品,在面向“一带一路”的低资源语言上表现优异。另外,大模型兼容性较好,可同时支持英伟达GPU与华为昇腾NPU计算,实现融合异构算力资源的跨平台持续迭代。
一、数据质量过关,滋养模型成长沃土
开发团队通过半自动和全自动相结合的方式收集了网络新闻、百科知识、学科知识、社区问答、多语言文本、多语言平行句对等文本数据,并研制出一套完整的数据预处理工具链来实现针对多语言大模型训练的数据去重、内容过滤、语言分类、数据采样、数据质检等多重数据评审链路,构建了超过200B用于增量训练的高质量多语言数据。
二、训练科学合理,保障模型稳定扩展
在当前开源的版本中,团队使用参数规模为7B的“鹏城·脑海”通用大语言模型作为增强训练的基座。为使模型具备更强大的多语言迁移能力和扩展能力,团队深入探索了多阶段课程式学习时的各种数据组合和优化策略。例如,在持续增强训练过程中,多语言数据在每个阶段的规模逐渐从10%提升至45%(图1),这可以让模型在获得新语言能力的同时降低遗忘已有语言能力的概率,确保模型多语言能力的稳定扩展。
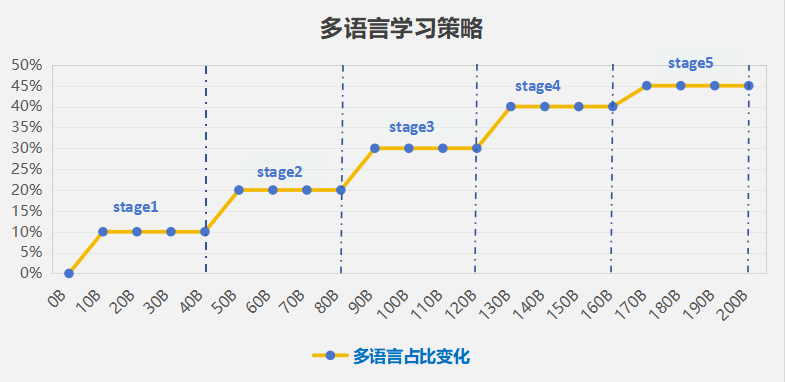
图1 多阶段课程式学习策略示意
三、能力表现优异,助力语言智能互译
通过多语言增强训练,鹏城·脑海多语言大模型PengCheng.Mind-m1覆盖的语言提升至53种,m1的机器翻译平均能力在国际权威的多语言机器翻译数据集Flores上超过了支持多语言能力的业内主流大模型(表1)。
|
模型 |
模型规模 |
外->中 |
中->外 |
|
Qwen2.5 |
7B |
26.96 |
7.63 |
|
Llama3.1 |
8B |
28.45 |
11.08 |
|
Baichuan2 |
7B |
21.22 |
6.12 |
|
GLM4 |
9B |
32.21 |
11.55 |
|
Mind-m1 |
7B |
32.57 |
13.85 |
表1 PengCheng.Mind-m1多语言基础机器翻译平均能力
与其他业界模型相比,模型在低资源语言的互译方面表现尤为突出,特别是在中文到外文的翻译上(表2)。
|
语言 |
Qwen2.5 |
Llama3.1 |
Baichuan2 |
GLM4 |
Mind-m1 |
|
外->中/中->外(Bleu) |
|||||
|
丹麦语 |
34.81/10.31 |
33.57/16.88 |
35.41/13.64 |
39.06/19.15 |
39.31/21.06 |
|
冰岛语 |
16.79/1.72 |
24.56/5.85 |
11.98/1.33 |
27.66/5.67 |
28.84/6.73 |
|
瑞典语 |
34.92/11.56 |
33.60/17.24 |
35.35/13.34 |
38.43/18.34 |
38.26/20.66 |
|
芬兰语 |
26.61/3.61 |
30.87/8.78 |
21.64/1.46 |
35.12/10.28 |
35.16/14.86 |
|
捷克语 |
33.92/7.92 |
32.90/13.62 |
34.38/9.98 |
36.96/14.47 |
37.01/16.49 |
|
斯洛伐克语 |
31.94/5.98 |
31.74/10.81 |
29.59/4.76 |
35.81/11.53 |
36.06/16.50 |
|
克罗地亚语 |
30.52/5.65 |
31.61/11.78 |
32.66/9.39 |
35.16/12.28 |
35.63/14.96 |
|
塞尔维亚语 |
32.59/3.70 |
31.92/12.51 |
33.84/9.88 |
37.01/10.61 |
36.69/15.67 |
|
平均 |
30.26/6.30 |
31.34/12.18 |
29.35/7.97 |
35.65/12.79 |
35.87/15.38 |
表2 PengCheng.Mind-m1中文与低资源语言的互译能力
以塞尔维亚语为例(图2),PengCheng.Mind-m1的能力随着训练稳步提升。
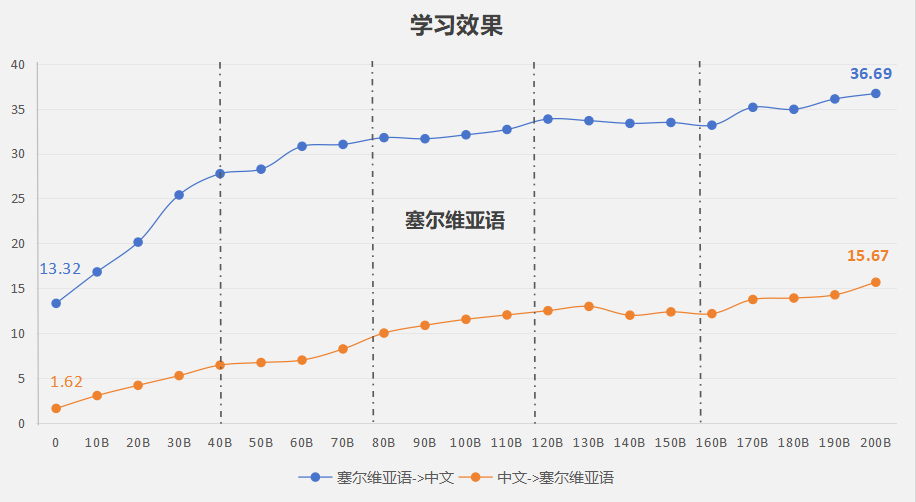
图2 PengCheng.Mind-m1塞尔维亚语的能力演变
四、潜力可圈可点,推动多语行业落地
基于PengCheng.Mind-m1模型,开发团队与中国外文局等合作者共同在时政新闻领域的出版翻译任务上进行了优化,在英语、法语、俄语等几个高资源语言上表现同样优异(表3)。
|
对外传播方向 |
中文->英语 |
中文->法语 |
中文->俄语 |
|
百度翻译 |
21.54 |
14.24 |
14.16 |
|
讯飞翻译 |
25.71 |
20.09 |
15.01 |
|
ChatGLM4 |
22.46 |
16.66 |
10.76 |
|
Qwen2.5-chat |
21.33 |
14.36 |
8.53 |
|
Mind-m1 |
29.07 |
29.15 |
21.98 |
表3 时政新闻领域中翻外效果
除了机器翻译能力,多语言模型的一大特点是支持多种语言的语言理解、语言生成和能力扩展,团队在MLQA数据集上对模型在跨语言问答能力上进行了测试,模型同样表现出色(表4)。
|
MLQA |
Qwen2.5-chat(F1%) |
Mind-m1(F1%) |
||||
|
Context |
Q:英语 |
Q:中文 |
Q:阿拉伯语 |
Q:英语 |
Q:中文 |
Q:阿拉伯语 |
|
英语 |
70.59 |
64.23 |
58.12 |
70.71 |
63.81 |
56.42 |
|
西班牙语 |
60.78 |
58.10 |
51.80 |
61.68 |
56.75 |
52.59 |
|
德语 |
54.18 |
50.95 |
46.27 |
56.75 |
52.23 |
50.70 |
|
阿拉伯语 |
44.64 |
40.68 |
44.65 |
49.36 |
45.4 |
46.05 |
|
印地语 |
47.50 |
43.53 |
38.32 |
48.66 |
44.91 |
41.21 |
|
越南语 |
56.29 |
54.16 |
48.59 |
57.33 |
53.11 |
49.03 |
|
中文 |
40.79 |
61.39 |
35.58 |
41.28 |
63.11 |
35.58 |
|
平均 |
53.53 |
53.29 |
46.19 |
55.11 |
54.18 |
47.36 |
表4 跨语言问答效果对比
在这里,要特别致谢参与数据优化,以及模型设计、研发和提升的粤港澳大湾区数字经济研究院(IDEA)、中国外文局、哈尔滨工业大学、新疆大学、澳门大学等单位的团队做出的重要贡献。以下为大模型的开源地址,欢迎试用体验并提出宝贵意见!
代码:
https://openi.pcl.ac.cn/pclmt/mPengC.mind
https://github.com/PCLNLP-group/mPengC.mind/
GPU 模型:https://huggingface.co/PCLNLP/mPengC.mind_gpu/tree/main
NPU 模型:https://huggingface.co/PCLNLP/mPengC.mind_npu/tree/main
(文:机器学习算法与自然语言处理)