


“三个臭皮匠,顶个诸葛亮”——这句古老的谚语似乎在大模型领域遇到了挑战。
“三个臭皮匠,顶个诸葛亮”——这句古老的谚语似乎在大模型领域遇到了挑战。
在大模型领域,多智能体辩论(Multi-Agent Debate, MAD)方法持续引发学界关注,并频繁亮相于顶级学术会议。该方法认为,通过让多个智能体在大模型推理时展开多轮辩论,可提升生成内容的事实准确性和推理质量。
然而,当前 MAD 的评估标准需要被重新审视——由上海人工智能实验室 OpenAGCI Team 联合宾夕法尼亚州立大学、西北工业大学及新加坡管理大学的最新研究表明:多智能体辩论在大多数情况下不敌简单的单智能体方法 Chain-Of-Thought。
在 36 种实验配置(覆盖 9 个常见数据集与 4 种大模型)中,MAD 的胜率不足 20%。即使增加辩论轮次或扩展智能体规模,仍无法改变其竞争劣势。这一发现是否意味着多智能体系统引以为傲的”群体智能”优势仅为美好的幻想?抑或是当前研究尚未找到打开其潜力的正确钥匙?

论文地址:
亮点速览
-
系统性评估:覆盖 5 种主流 MAD 框架、9 大基准测试、4 种 LLM,揭示 MAD 研究的局限性;
-
关键性结论:MAD 并非“万能解药”,现有方法在答案正确性、推理效率、鲁棒性上落后于单智能体推理策略 Chain-Of-Thought 和 Self-Consistency;
-
简单有效的改进:提出 Heter-MAD,通过简单引入异构模型智能体,无需修改现有 MAD 框架即可稳定提升性能(最高达 30%);
-
未来研究思路:模型异构性优化、细粒度交互机制、适配 MAD 的复杂场景

近年来,随着大型语言模型(LLM)在推理和生成任务中的广泛应用,如何进一步提升其性能成为研究热点。
多智能体辩论(Multi-Agent Debate, MAD)方法应运而生,其核心思想是通过多个 LLM 智能体在推理过程中进行多轮讨论,以期提升答案的事实准确性和推理质量。由于大部分MAD框架无需额外训练,仅在推理阶段引入协作机制,因此受到了广泛关注,并在顶级学术会议上频繁亮相。
然而,该研究对 MAD 现有的评估方法准提出了质疑。当前 MAD 的评估存在以下显著问题:
1. 大多数 MAD 方法的评测数据集覆盖范围与交集有限,例如仅聚焦于通用知识、数学推理或者医疗问答等个别领域,缺乏在相同评测数据集上的比较;
2. 对比的基线方法考虑不全面,例如不少 MAD 方法未曾与简单单智能体方法进行对比;
3. 现有评测较少考虑推理效率和鲁棒性。这些问题可能导致对 MAD 的乐观高估,而其局限性或潜力仍有待进一步探索和揭示。

系统评估 MAD
针对上述问题,该研究首先构建了一个全面且系统的评测框架:作者选取了 5 种具有代表性的 MAD 框架(包括 SoM、MP、EoT、ChatEval 和 AgentVerse),在 9 个涵盖通用知识、数学推理和编程能力的基准数据集上,使用 4 个基础模型(GPT-4o-mini、Claude-3.5-haiku、Llama3.1-8b/70b)进行实验。
对比基线包括单智能体方法 如 Chain-of-Thought(CoT)和 Self-Consistency(SC)。评估从性能、效率和鲁棒性三个维度展开。
MAD未达预期
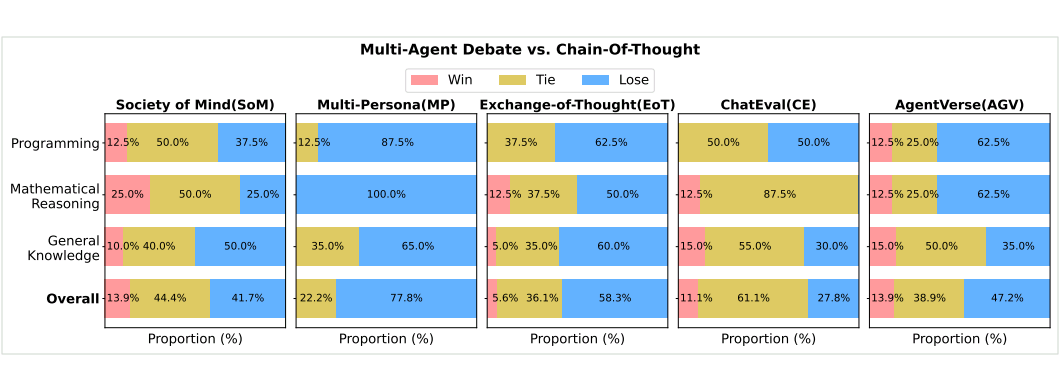
实验表明,MAD 方法的整体表现未能达到预期效果。
性能不足:在 36 个测试场景(4 种模型 × 9 个数据集)中,MAD 方法仅在不到 20% 的情况下优于Chain-of-Thought(CoT),在大多数场景中表现不及 CoT。与 Self-Consistency(SC)相比,MAD 的劣势更为显著,SC 在相同推理预算下表现更为出色。
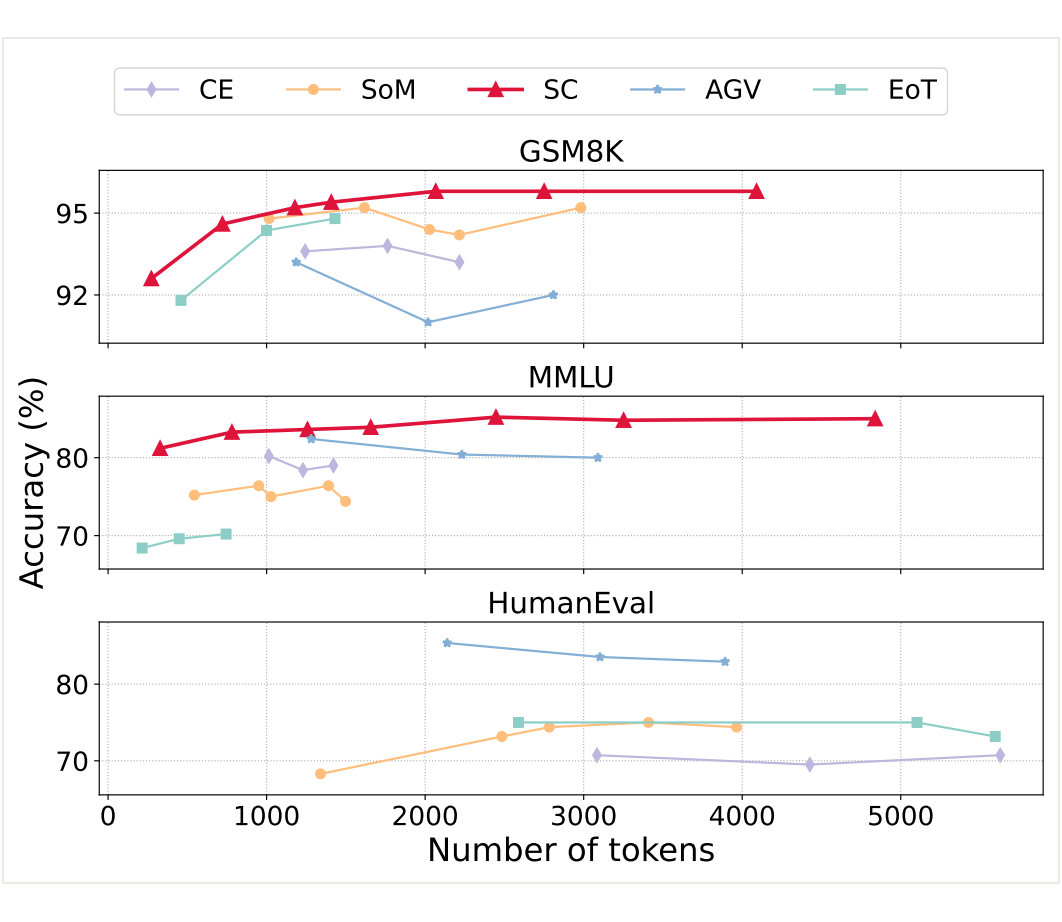
效率低下:MAD 方法消耗了更多的 token,但未能带来稳定的性能提升。例如,SoM 在 MMLU 数据集上,随着 token 数量的增加,性能并未显著改善;而 EoT 虽然有所提升,但仍无法超越 SC 的表现。
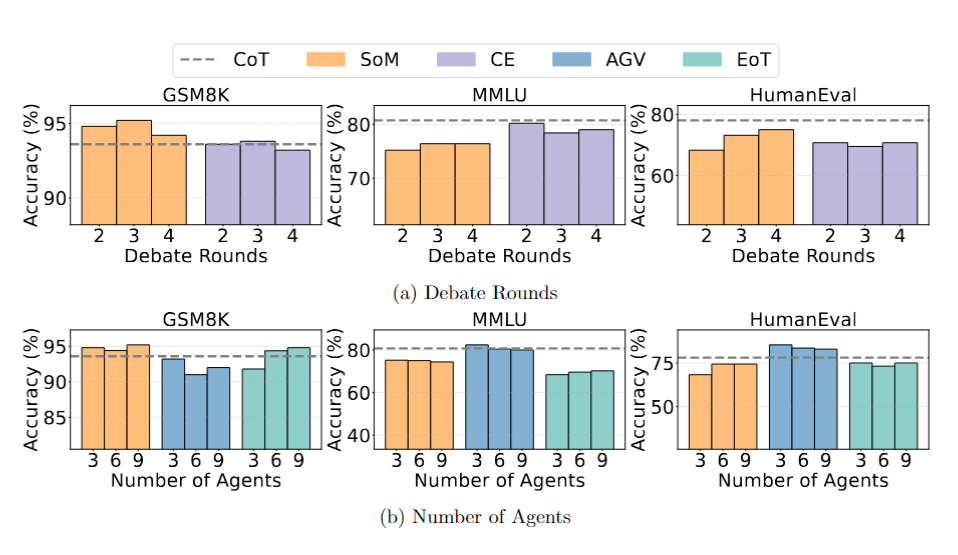
超参数调整效果有限:通过增加智能体数量或辩论轮次(例如将 SoM 的智能体数量从 3 个增加到 9 个)并未显著改善 MAD 的表现,表明其性能不足的问题并非源于参数配置,而是方法本身存在局限性。

引入模型异构性:Heter-MAD
作者指出,人类协作成功的关键在于个体多样性,而缺乏多样性的团队协作往往难以取得突破。然而,现有 MAD 方法大多使用同一模型的多个实例进行评测,忽视了模型多样性可能带来的性能提升。
为此,作者提出了 Heter-MAD 方法:在MAD 框架中,每个 LLM 智能体随机从异构模型池(如 GPT 和 Llama)中选择模型生成答案。这种简单调整无需改变现有 MAD 框架结构,却能显著且稳定地提升性能。
实验表明,Heter-MAD 在绝大多数数据集和 MAD 方法上均实现了稳定提升,最高提升幅度达到 30%。Heter-MAD 显著改善了所有 MAD 框架的表现。例如,Heter-SoM 的平均性能较单独使用单一模型的 SoM 提升了 6.4%,Heter-EoT 则提升了8.2%。
有趣的是,作者在评测中发现,通过结合 GPT-4o-mini 和 Llama-3-70b,Heter-MAD 在更小的计算开销下取得了更好的表现。
此外,更简单的 MAD 方法(如 SoM 和 EoT)在引入模型异构性后,性能提升幅度明显高于复杂 MAD 方法(如 ChatEval 和 AgentVerse),这表明当前的 MAD 方法并未充分兼容模型多样性。
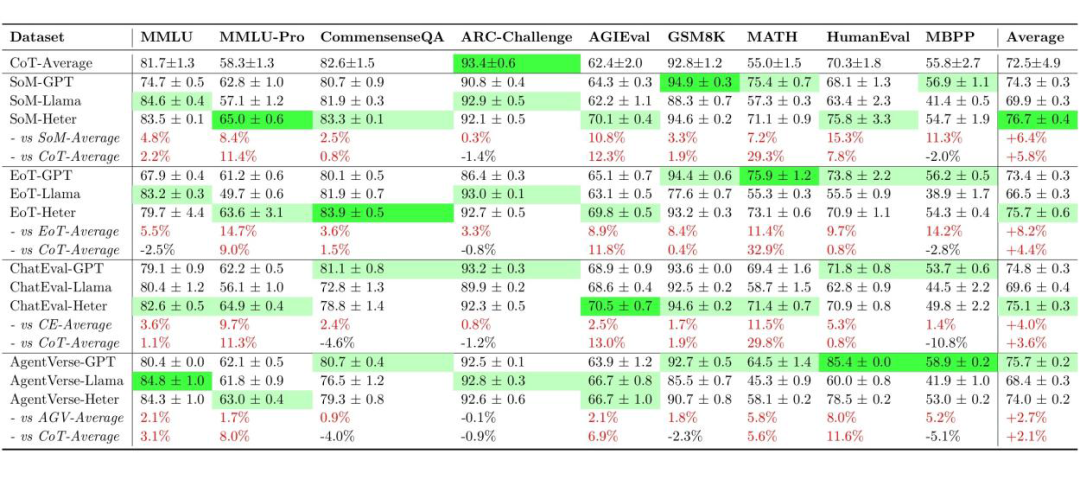
Heter-MAD 的评测结果验证了协作多样性对于 MAD 的重要性,同时也表明现有方法尚未充分挖掘 MAD 的潜力。

该研究通过系统评估揭示了:当前的多智能体辩论(MAD)方法不仅在性能上未能超越简单的单智能体基线方法(如 Chain-of-Thought, CoT 和 Self-Consistency, SC),并且在效率和鲁棒性方面表现欠佳。
然而,作者认为这并非 MAD 的终点,而是反映了 MAD 研究仍处于早期阶段,当前的设计尚未充分挖掘其潜力。在本文的结尾,作者提出了四个未来研究方向:
如何在 MAD 中充分利用模型异构性?尽管本文提出了 Heter-MAD 方法,但这仅是一个初步尝试,远未达到成熟。
实验表明,现有 MAD 方法并未充分利用模型多样性——简单的 MAD 方法反而能从模型异构性中获得更大的性能提升,而复杂的 MAD 方法则对异构模型的兼容性较差。这表明,为异构模型特别设计 MAD 方法是一个极具潜力的研究方向。
如何结合单智能体推理进一步提升 MAD?综合利用多智能体推理并不意味着我们可以忽视单智能体推理带来的提升。相反,未来的研究应更注重如何在多智能体框架中有效整合单智能体方法的优势,以实现更显著的性能提升。
如何实现细粒度的协作机制?现有的多智能体协作框架往往缺乏对细粒度协作的关注。例如,在 MAD 中,智能体通常仅通过对比彼此的答案来构建讨论内容,这限制了 MAD 的灵活性和协作粒度。未来的研究可以探索更精细的协作机制,以提升 MAD 的表现。
哪些应用场景更能凸显 MAD 的优势?当前的 MAD 评测大多依赖于为单智能体设计的基准测试,这些测试无法充分体现 MAD 综合利用多智能体知识的能力。未来可能需要开发更复杂、更综合性的评测基准,以更好地评估 MAD 在特定场景下的潜力。
对于人工智能研究者,这篇论文不仅是一次对 MAD 的深度反思,更是一次启发:协作的力量值得探索,但关键在于找到适合的机制和应用场景。欢迎大家阅读原论文,共同参与这场关于“智能体协作”的讨论!
(文:PaperWeekly)