
在2025年,大模型从云端“下凡”已成趋势。越来越多的开发者和AI爱好者开始转向本地部署,追求更快的响应、更强的隐私保护和更自由的定制能力。不再依赖外部API,不必担心接口限流或数据泄露,构建属于自己的AI助手,正变得前所未有地简单。
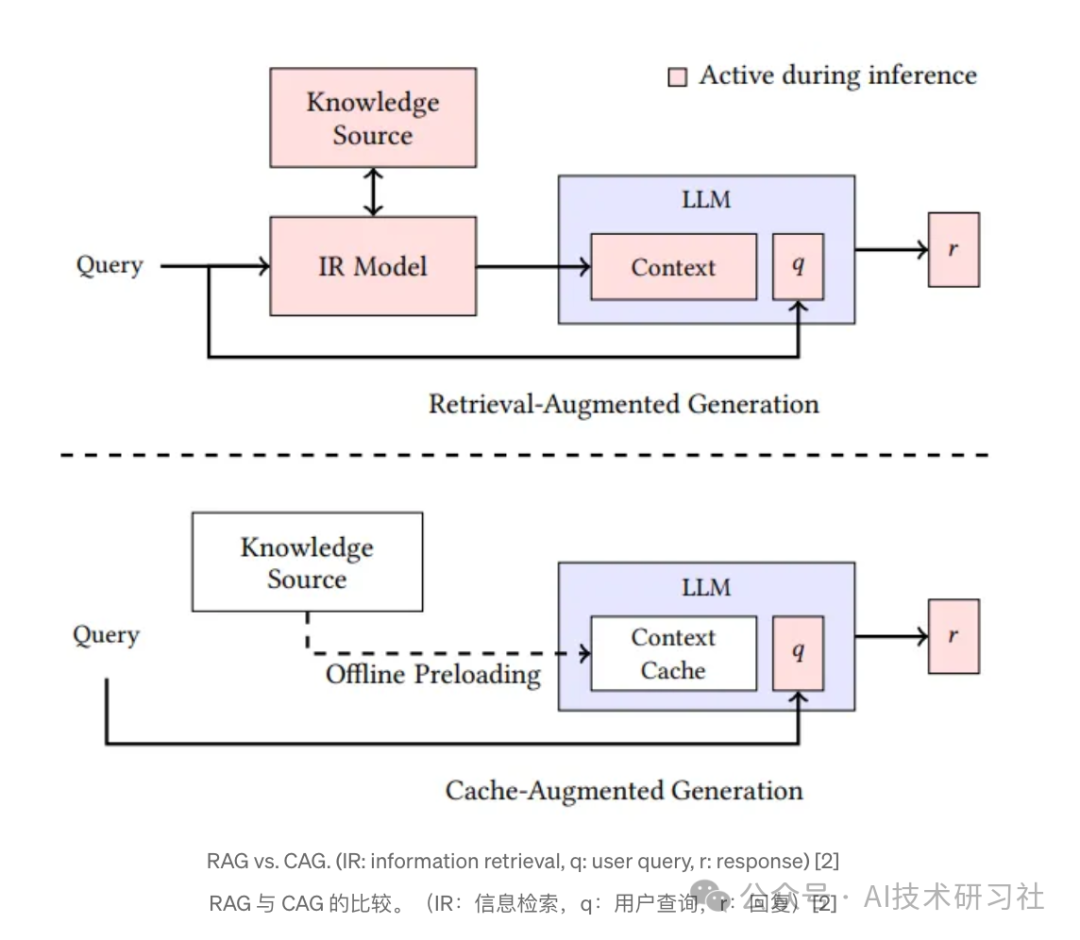
如果说RAG是AI知识问答系统的“传统王者”,那么CAG正是新一代本地智能体的“黑马新星”。
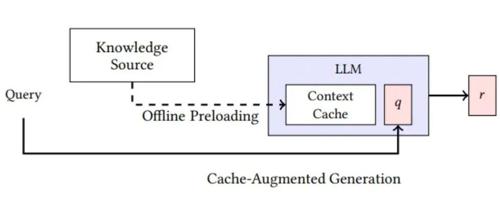
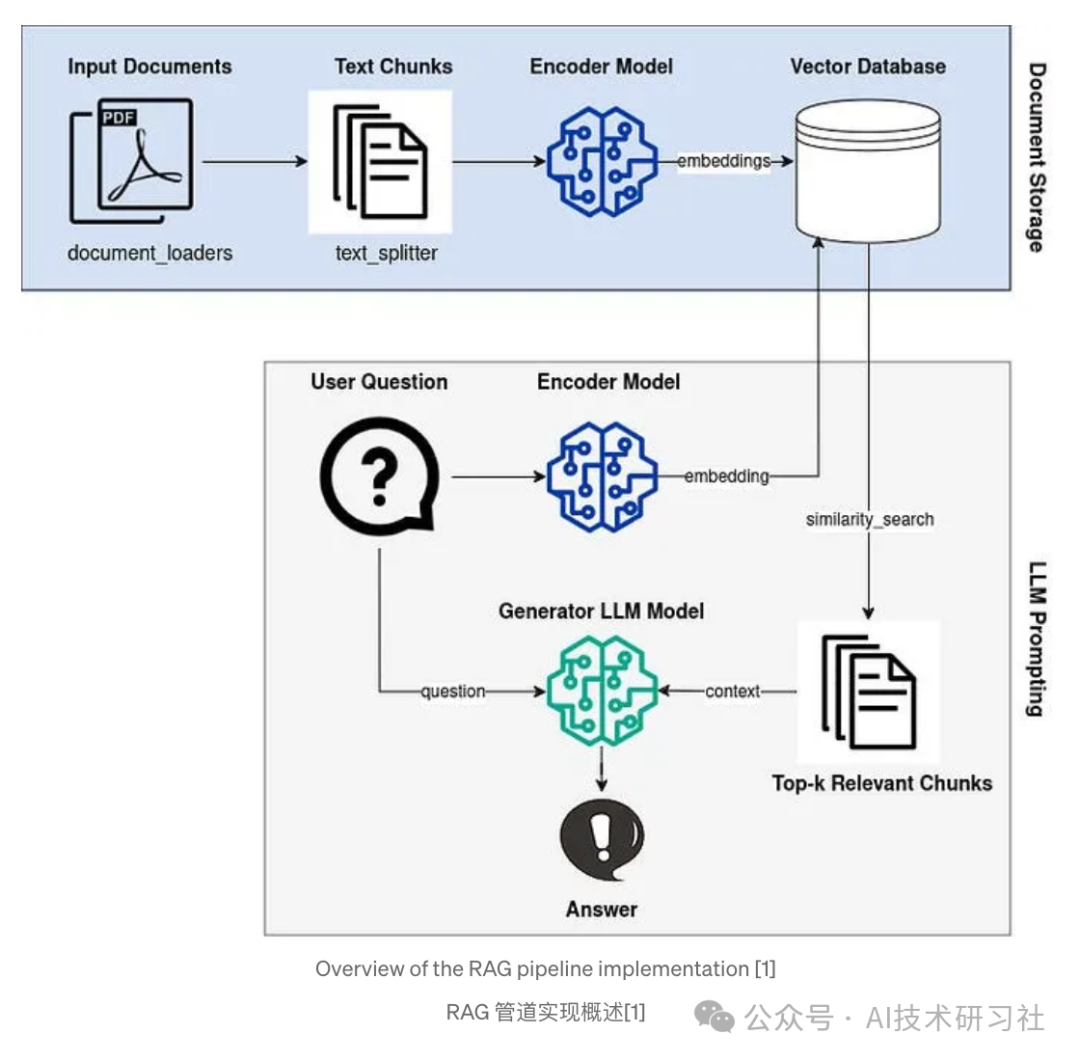
RAG(检索增强生成) 的核心逻辑是“先查再答”:用户提问后,系统先从外部知识库中检索相关文档片段,再将其拼接到提示词中,一并送入大模型生成答案。这种方式依赖检索质量,适用于知识结构明确、文本语义稳定的场景,像FAQ、文档问答等。
相比之下,CAG(上下文感知生成) 则强调“上下文记忆与智能缓存”。它通过智能上下文缓存机制,自动记录并筛选历史对话中最相关的信息片段,在每轮对话中动态构建提示词。
CAG更像是在构建一个“记性更好”的聊天伙伴,不仅能追溯长对话历史,还能做出更加连贯、个性化的回答,适合多轮对话、本地部署和低资源环境下的轻量智能体。
一句话总结:
✅ RAG 是外向型:靠检索找答案
✅ CAG 是内向型:靠记忆说人话
在本地化、隐私保护和边缘部署需求日益增长的今天,CAG展现出更强的灵活性和适配性,是下一代轻量聊天机器人的有力工具。

这套组合方案——CAG + vLLM + Streamlit,正是本地化AI聊天体验的高效三件套。它不仅解决了传统RAG方案中对外部知识检索的强依赖,还用更智能的上下文缓存机制,实现多轮对话中的信息追踪与动态生成。配合vLLM的高性能推理,以及Streamlit的轻量化界面开发,你只需一个下午,就能搭建属于自己的智能聊天机器人。
相比传统RAG那种“问一次、查一次”的架构,CAG的优势在于记忆力更强。它会在对话过程中自动提取关键信息,构建出更加连贯自然的上下文提示。无需手动设置长提示词,也不需要外接检索系统,它天生适合做本地聊天机器人,响应速度快,部署成本低。
Streamlit则为整个系统提供了一个极简但实用的界面解决方案。即使你没有前端开发经验,也能通过几行代码搭建出专业感十足的聊天界面。调试、运行、展示,一站式完成,极大降低了上手门槛。
接下来我们将拆解整个方案的核心组件,深入理解CAG背后的机制、vLLM如何实现加速推理,以及如何用Streamlit搭建完整的对话界面。如果你正在寻找一个能快速落地、运行顺畅的本地AI助手搭建方案,这篇文章或许正是你需要的答案。
CAG 原理解析:为什么它比传统的 RAG 更适合本地部署?
CAG(上下文感知生成)是一种更加注重对话上下文的生成机制。与传统的 RAG(检索增强生成)不同,RAG依赖外部的检索模块,每次生成都需要从外部知识库中找到相关信息。

而CAG通过内置的上下文缓存,能够在对话过程中自动跟踪历史上下文,在多轮对话中准确提取关键信息,使得机器人能生成更加自然和连贯的回答。
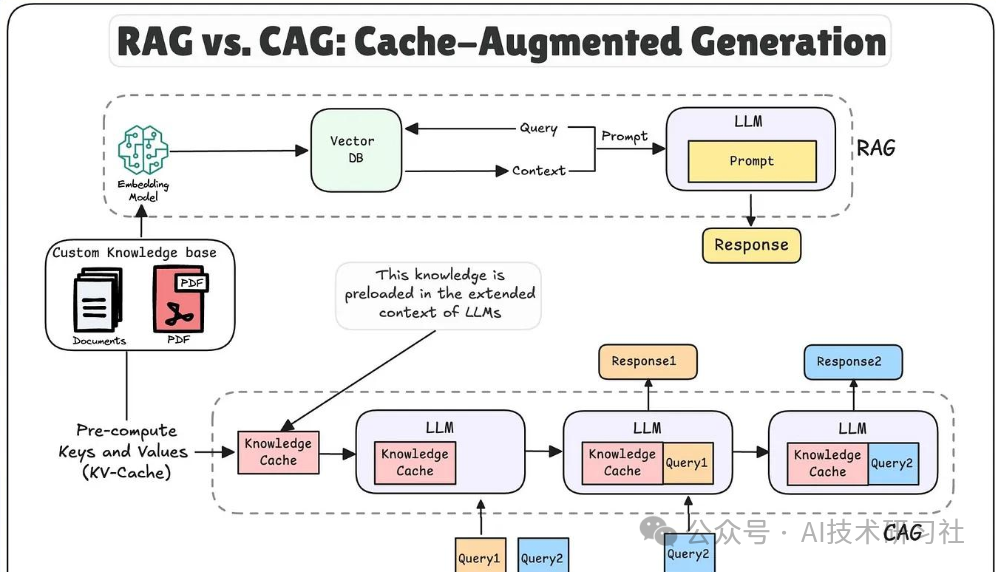
具体来说,CAG的核心原理是:每当用户输入一个新的问题或命令时,系统会在内部维护的缓存中查找是否有相关的上下文信息。如果有,它会将这些信息合并到生成的提示词中;如果没有,它会通过先前的对话历史动态生成新的上下文。这种方式使得每次对话都能与前文无缝衔接,增强了回答的准确性和流畅度。
在技术实现上,CAG使用了一个“动态上下文拼接”的机制,将多个历史对话片段与当前用户问题结合,从而提供更加智能的生成。
vLLM:提升本地推理速度的加速器
vLLM(Vectorized Large Language Model)是一个专门为提升大模型推理速度而优化的库。它通过高效的向量化运算,显著减少了多轮对话中重复计算的成本,使得每次推理都能更加高效。
通过 vLLM,我们可以将本地部署的推理速度提升几个数量级,确保即使在资源受限的设备上,也能进行流畅的对话生成。vLLM的优势在于,它能将大模型的计算图进行优化,使得同样的硬件配置能完成更高效的推理。
例如,如果你在一台普通的PC上运行,vLLM能够利用并行计算技术,最大化GPU的性能,避免了不必要的内存和计算开销。
以下是一个简单的 vLLM 推理代码示例,展示如何在本地环境中使用 vLLM 进行推理加速:
from vLLM import LLMfrom vLLM import ModelConfig# 配置模型config = ModelConfig(model="gpt-3.5-turbo", device="cuda") # 使用GPU加速model = LLM(config)# 生成回答input_text = "如何使用 CAG 构建本地聊天机器人?"response = model.generate(input_text)print(response)
在这个例子中,我们通过 vLLM 加载了一个 GPT-3.5 模型,并配置了 CUDA 来利用 GPU 加速推理。通过 generate() 函数,模型能够快速生成回答,且延迟极低。
Streamlit:快速搭建本地聊天机器人界面
在完成 CAG 和 vLLM 的后端实现后,Streamlit 则是我们用来创建前端用户界面的得力工具。它能够让你通过简单的 Python 代码,快速搭建出一个功能完善、用户友好的聊天界面。
下面是一个用 Streamlit 创建简单聊天界面的代码示例:
import streamlit as stfrom vLLM import LLMfrom vLLM import ModelConfig# 配置模型config = ModelConfig(model="gpt-3.5-turbo", device="cuda")model = LLM(config)# 设置Streamlit界面st.title("本地AI聊天机器人")# 用户输入user_input = st.text_input("请输入您的问题:")# 模型生成回答if user_input:response = model.generate(user_input)st.write("AI回答:", response)
这段代码将生成一个非常简单的聊天界面,用户可以在输入框中输入问题,AI则返回相应的答案。
部署流程图:
-
用户输入:用户在 Streamlit 提供的输入框中输入问题。
-
上下文缓存:CAG 系统从本地缓存中获取相关上下文信息。
-
vLLM 推理:系统将输入和上下文传给 vLLM 进行推理,加速响应时间。
-
生成答案:模型根据上下文生成答案,并返回给用户。
-
界面显示:Streamlit 将答案展示在前端界面上,用户可继续与机器人互动。
下面是部署流程图示意:
用户输入 -> CAG 缓存 -> vLLM 推理 -> 生成回答 -> Streamlit 显示通过 CAG + vLLM + Streamlit,我们能够在本地构建出一个高效、智能且具备良好用户体验的聊天机器人。这个方案的优势不仅仅在于其强大的技术背景,更在于它能够让开发者快速搭建并部署本地化的AI应用,提供前所未有的灵活性和自由度。
接下来,您可以根据这套流程进一步优化和拓展聊天机器人的功能,例如增加对外部知识库的访问、支持多种对话模式等。
希望这篇文章能帮助您快速入门本地AI聊天机器人的构建,开启智能对话的新时代。
(文:AI技术研习社)