

编辑:张倩
LoRA 中到底存在多少参数冗余?这篇创新研究介绍了 LoRI 技术,它证明即使大幅减少 LoRA 的可训练参数,模型性能依然保持强劲。研究团队在数学推理、代码生成、安全对齐以及 8 项自然语言理解任务上测试了 LoRI。发现仅训练 LoRA 参数的 5%(相当于全量微调参数的约 0.05%),LoRI 就能匹配或超越全量微调、标准 LoRA 和 DoRA 等方法的性能。

大型语言模型的部署仍然需要大量计算资源,特别是当需要微调来适应下游任务或与人类偏好保持一致时。
为了降低高昂的资源成本,研究人员开发了一系列参数高效微调(PEFT)技术。在这些技术中,LoRA 已被广泛采用。
不过,LoRA 仍然会带来显著的内存开销,尤其是在大规模模型中。因此,近期研究聚焦于通过减少可训练参数数量进一步优化 LoRA。
最近的研究表明,增量参数(微调后的参数减去预训练模型参数)存在显著冗余。受随机投影有效性和增量参数冗余性的启发,来自马里兰大学和清华大学的研究者提出了带有降低后的干扰的 LoRA 方法——LoRI(LoRA with Reduced Interference)。
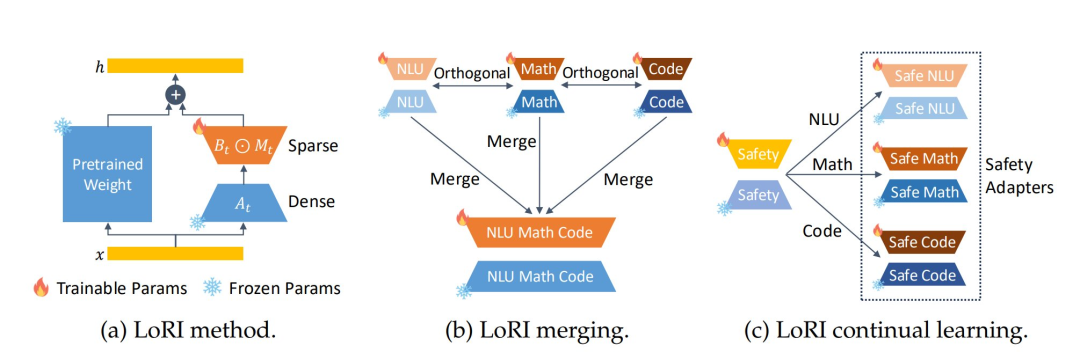
LoRI 保持低秩矩阵 A 作为固定的随机投影,同时使用任务特定的稀疏掩码训练矩阵 B。为了保留 B 中最关键的元素,LoRI 通过选择所有层和投影中具有最高幅度的元素来执行校准过程,从而提取稀疏掩码。
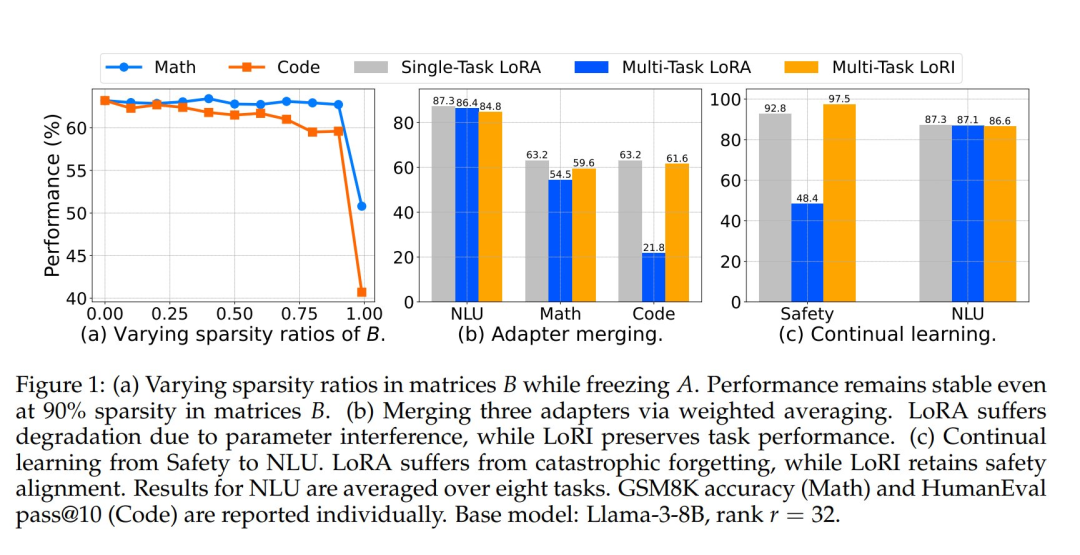
如图 1(a) 所示,即使 B 具有 90% 的稀疏性且 A 保持冻结状态,LoRI 仍能保持良好性能。这表明适应过程不需要更新 A,且 B 存在相当大的冗余。通过应用比 LoRA 更受约束的更新,LoRI 显著减少了可训练参数的数量,同时在适应过程中更好地保留了预训练模型的知识。
多任务学习对于实现具有多任务能力的通用模型至关重要,传统上通过在任务特定数据集的组合上进行联合训练来实现。然而,在这种数据混合上训练大型模型在时间和计算资源上成本过高。模型合并是一种无需训练的替代方案,通过组合现有模型来构建强大的模型。这种方法非常适合合并 LoRA 适配器,使单个 LoRA 具备多任务能力。
然而,如图 1(b) 所示,直接合并异构 LoRA 通常会导致参数干扰,使合并后的 LoRA 性能低于单任务 LoRA。此外,许多现有的合并方法需要反复试验才能确定特定任务组合的最佳方法。
LoRI 通过实现适配器合并而无需手动选择合并方法来解决这些挑战。通过使用固定的、随机初始化的投影 A,LoRI 将任务特定的适配器映射到近似正交的子空间,从而减少合并多个 LoRI 时的干扰。
除了多任务处理外,安全关键场景要求每个新引入的适配器在增强模型能力的同时保持预训练基础模型的安全对齐。LoRI 提供了一种轻量级的持续学习方法,用于调整模型同时保持安全性,其中训练是在任务间顺序进行的。该策略首先在安全数据上微调适配器以建立对齐,然后分别适应每个下游任务。
然而,如图 1(c) 所示,持续学习常常导致灾难性遗忘,即对新任务的适应会严重损害先前获得的知识。LoRI 通过特定任务掩码利用矩阵 B 的稀疏性来减轻遗忘。这种跨任务参数更新的隔离促进了干扰最小化的持续学习,同时保持了安全性和任务有效性。
为评估 LoRI 的有效性,作者在涵盖自然语言理解、数学推理、代码生成和安全对齐任务的多种基准上进行了大量实验。
以 Llama-3-8B 和 Mistral-7B 作为基础模型,他们的结果表明,LoRI 达到或超过了全量微调(FFT)、LoRA 和其他 PEFT 方法的性能,同时使用的可训练参数比 LoRA 少 95%。值得注意的是,在使用 Llama-3 的 HumanEval 上,B 中具有 90% 稀疏度的 LoRI 比 LoRA 高出 17.3%。
除单任务适应外,他们还评估了 LoRI 在多任务环境中的表现,包括适配器合并和持续学习场景。LoRI 适配器的串联合并总体上始终优于 LoRA 适配器,与单任务 LoRA 基线的性能非常接近。在持续学习方面,LoRI 在减轻安全对齐的灾难性遗忘方面显著优于 LoRA,同时在下游任务上保持强劲表现。

-
论文标题:LoRI: Reducing Cross-Task Interference in Multi-Task LowRank Adaptation
-
论文链接:https://arxiv.org/pdf/2504.07448
-
代码链接:https://github.com/juzhengz/LoRI
-
HuggingFace:https://huggingface.co/collections/tomg-group-umd/lori-adapters-67f795549d792613e1290011
方法概览
如下图所示,论文中提出的 LoRI 方法主要有以下要点:
-
LoRI 冻结投影矩阵 A_t,并使用特定任务的掩码稀疏更新 B_t;
-
LoRI 支持多个特定于任务的适配器合并,减少了参数干扰;
-
LoRI 通过不断学习和减少灾难性遗忘来建立安全适配器。
在作者推文评论区,有人问这个方法和之前的方法(如 IA3)有何不同。作者回复称,「IA3 和 LoRI 在调整模型参数的方式上有所不同:IA3 学习键/值/FFN 激活的 scaling 向量。可训练参数就是 scaling 向量。LoRI(基于 LoRA)将权重更新分解为低秩矩阵。它将 A 保持冻结,并对 B 应用固定的稀疏性掩码。所以只有 B 的未掩蔽部分被训练。」
实验结果
作者采用 Llama-3-8B 和 Mistral7B 作为基准模型,所有实验均在 8 块 NVIDIA A5000 GPU 上完成。如图 1(a) 所示,LoRI 在矩阵 B 达到 90% 稀疏度时仍能保持强劲性能。为探究稀疏度影响,作者提供了两个 LoRI 变体:使用稠密矩阵 B 的 LoRI-D,以及对矩阵 B 施加 90% 稀疏度的 LoRI-S。
单任务性能
表 1 展示了不同方法在 8 个自然语言理解(NLU)基准测试中的单任务结果,表 2 则报告了不同方法在数学、编程和安全基准上的表现。
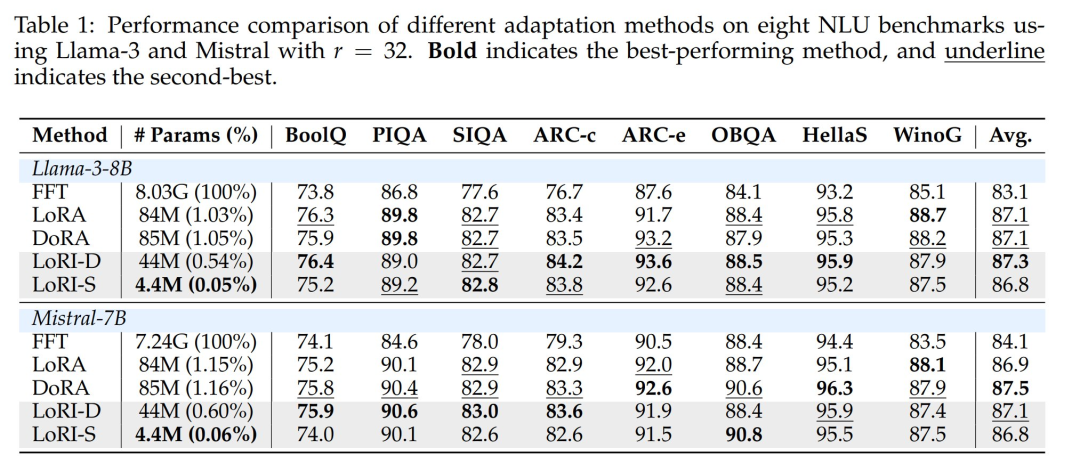
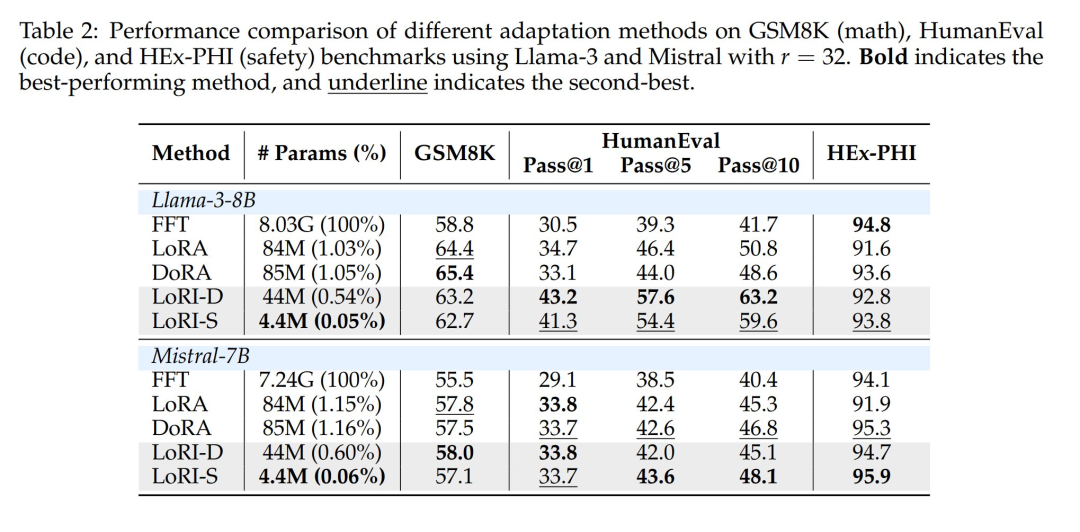
全参数微调(FFT)会更新所有模型参数,而 LoRA 和 DoRA 将可训练参数量降至约 1%。LoRI-D 通过冻结矩阵 A 进一步将参数量压缩至 0.5%,LoRI-S 则通过对矩阵 B 施加 90% 稀疏度实现 0.05% 的极致压缩——相比 LoRA 减少 95% 可训练参数。尽管调参量大幅减少,LoRI-D 和 LoRI-S 在 NLU、数学、编程及安全任务上的表现均与 LoRA、DoRA 相当甚至更优。
适配器融合
作者选取 NLU、数学、编程和安全四类异构任务进行 LoRA 与 LoRI 融合研究,该设定比融合同类适配器(如多个 NLU 适配器)更具挑战性。
表 3 呈现了四类任务的融合结果。作者对 LoRI-D 和 LoRI-S 变体分别采用串联融合与线性融合。由于 LoRI 已对矩阵 B 进行稀疏化,基于剪枝的方法(如幅度剪枝、TIES、DARE)不再适用——这些方法会剪枝矩阵 A,导致 AB 矩阵剪枝策略不一致。
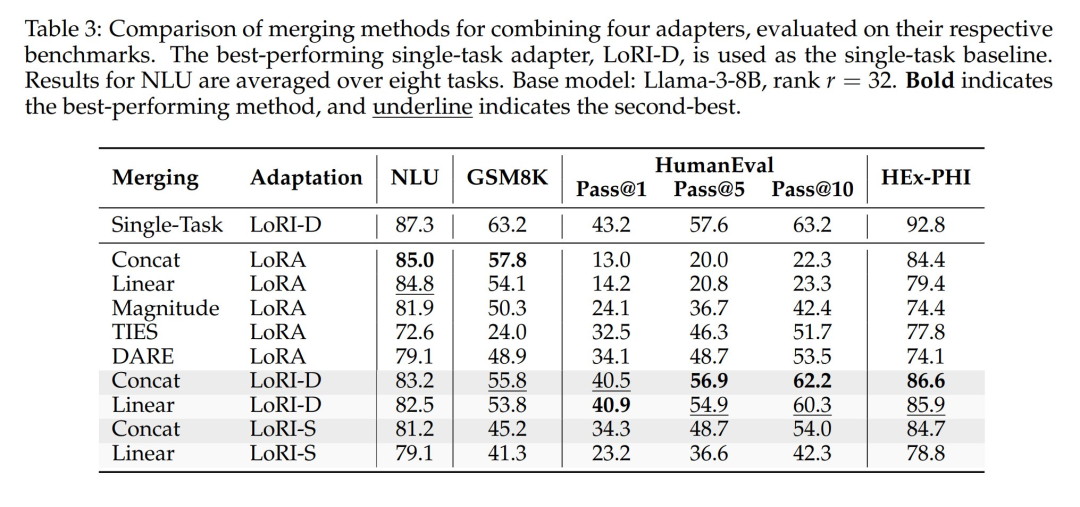
如表 3 所示,直接融合 LoRA 会导致性能显著下降(特别是代码生成与安全对齐任务)。虽然剪枝方法(如 DARE、TIES)能提升代码性能,但往往以牺牲其他任务精度为代价。相比之下,LoRI 在所有任务上均表现稳健,其中 LoRI-D 的串联融合方案整体表现最佳,几乎与单任务基线持平,这表明 LoRI 适配器间存在最小干扰。
持续学习
虽然合并适配器能够实现多任务能力,但在需要强大安全保障的场景中,它无法提供稳健的安全对齐。如表 3 所示,通过 LoRA 或 LoRI 合并所能达到的最高安全得分为 86.6。
为了解决这一问题,作者采用了两阶段训练过程:首先,在 Saferpaca 安全对齐数据集上训练安全适配器;然后,将其分别适应到各个下游任务,包括自然语言理解(NLU)、数学和代码。
图 3 展示了这些持续学习实验的结果。LoRA 在安全对齐上表现出严重的灾难性遗忘——尤其是在安全→NLU 实验中——这可能是由于 NLU 训练集较大(约 17 万个样本)所致。在所有方法中,LoRI-S 实现了对安全对齐的最佳保留,甚至优于单任务 LoRI-D。这是因为其 B 矩阵具有 90% 的稀疏性,能够在安全对齐和任务适应之间实现参数更新的隔离。LoRI-D 也表现出一定的抗遗忘能力,得益于其冻结的 A 矩阵。对于任务适应,LoRI-D 通常优于 LoRI-S,因为后者激进的稀疏性限制了其适应能力。
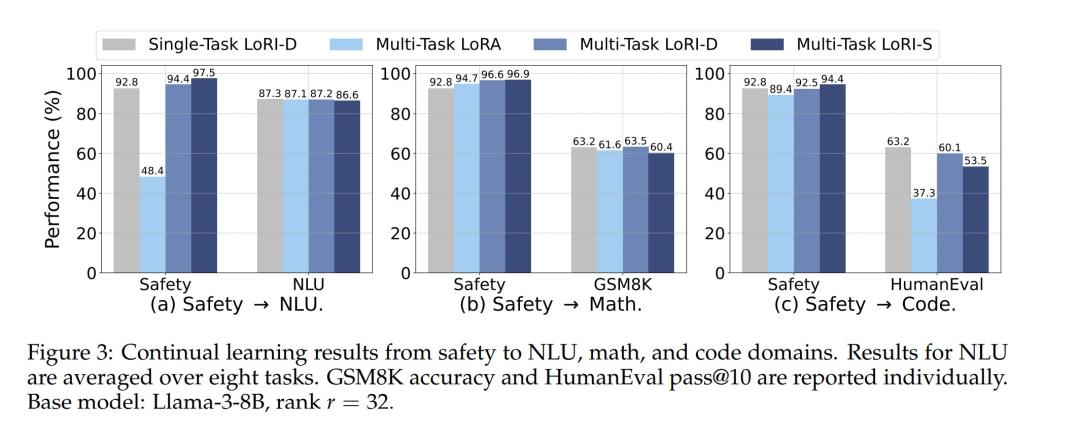
总体而言,LoRI 提供了一种轻量级且有效的方法来构建安全适配器,在支持下游任务适应的同时保持对齐。
详细内容请参见原论文。
©
(文:机器之心)