

今天是2025年5月6日,星期二,北京,晴。
我们今天来看两个问题。
一个是继续对现有的报告生成项目进行项目代码拆解,讲讲Deepresearch变体之公司报告自动生成company-research-agent,其是一个典型的工作流workflow,看其使用如何基于langgraph来设计节点并且完整的串起来一个项目。
一个是文档智能进展,看看多模态文档大模型PP-DOCBEE的数据合成策略,尤其是看Text-rich Document QA Generation、Chart Image Generation、Chart QA Generation、Table QA Generation的实现逻辑,这种设计思路很重要。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Deepresearch变体之公司报告自动生成company-research-agent
类似的,我们继续解析相关项目,看Deepresearch进展,跟公司报告自动生成结合的工作https://github.com/pogjester/company-research-agent,在框架上使用的是langgraph,主流程在https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/graph.py
看几个点:
在数据侧,从公司网站、新闻文章、财务报告和行业分析等多个来源收集数据,并使用Tavily的相关性评分进行内容筛选,使用WebSocket连接流式传输研究进度和结果
所以在输入的时候,需要指定相关信息:

在模型侧,使用Gemini 2.0 Flash用于高上下文研究综合(擅长处理和总结大量数据,所以用于生成初始类别简报,在多个文档之间高效维护上下文);使用gpt-4.1-mini用于精确的报告格式化和编辑(处理markdown结构和一致性,在遵循精确格式说明方面表现较好,所以用于最终报告编译、内容去重、Markdown格式化以及实时报告流式传输),最终生成一份公司报告。从中可以看到选用模型要从模型的特性出发。
更进一步的,来看下实现细节,实现技术流程如下:
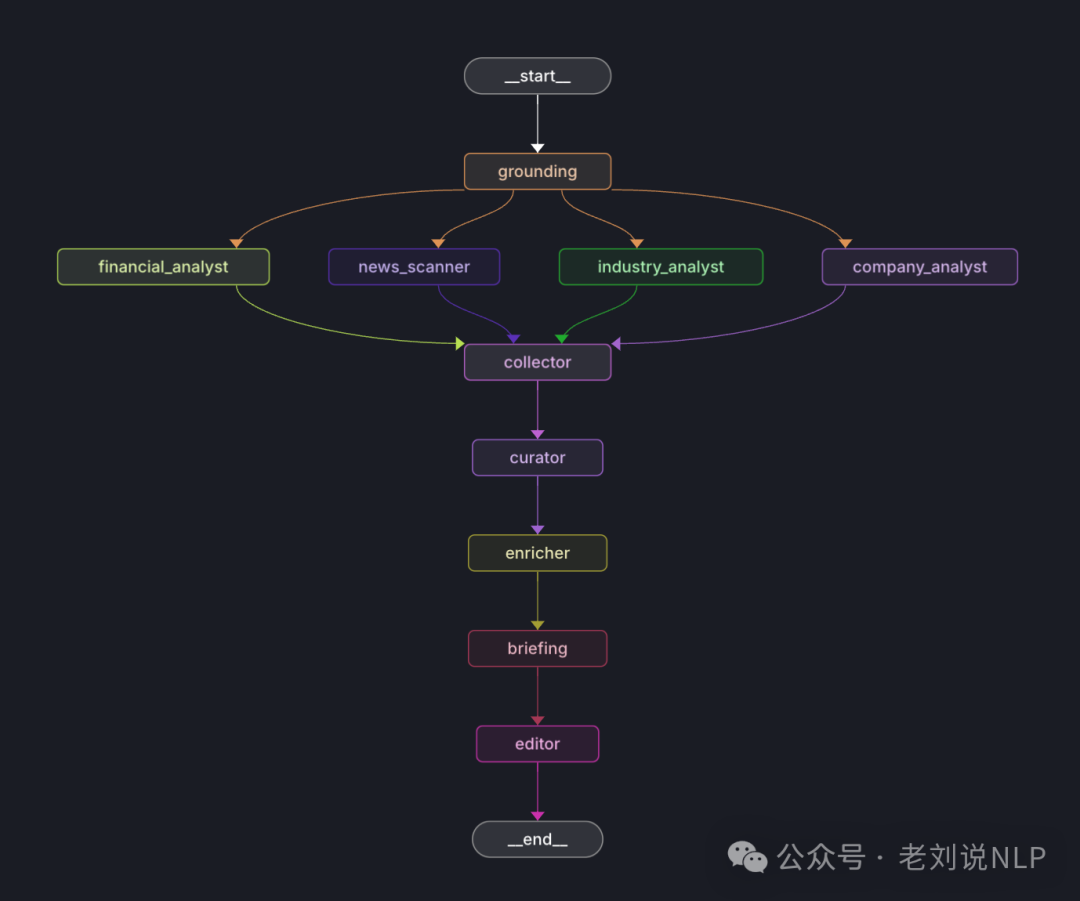
从中可以看到许多几个模块,其实在代码侧看,就是一个workflow,在https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/graph.py,如下:
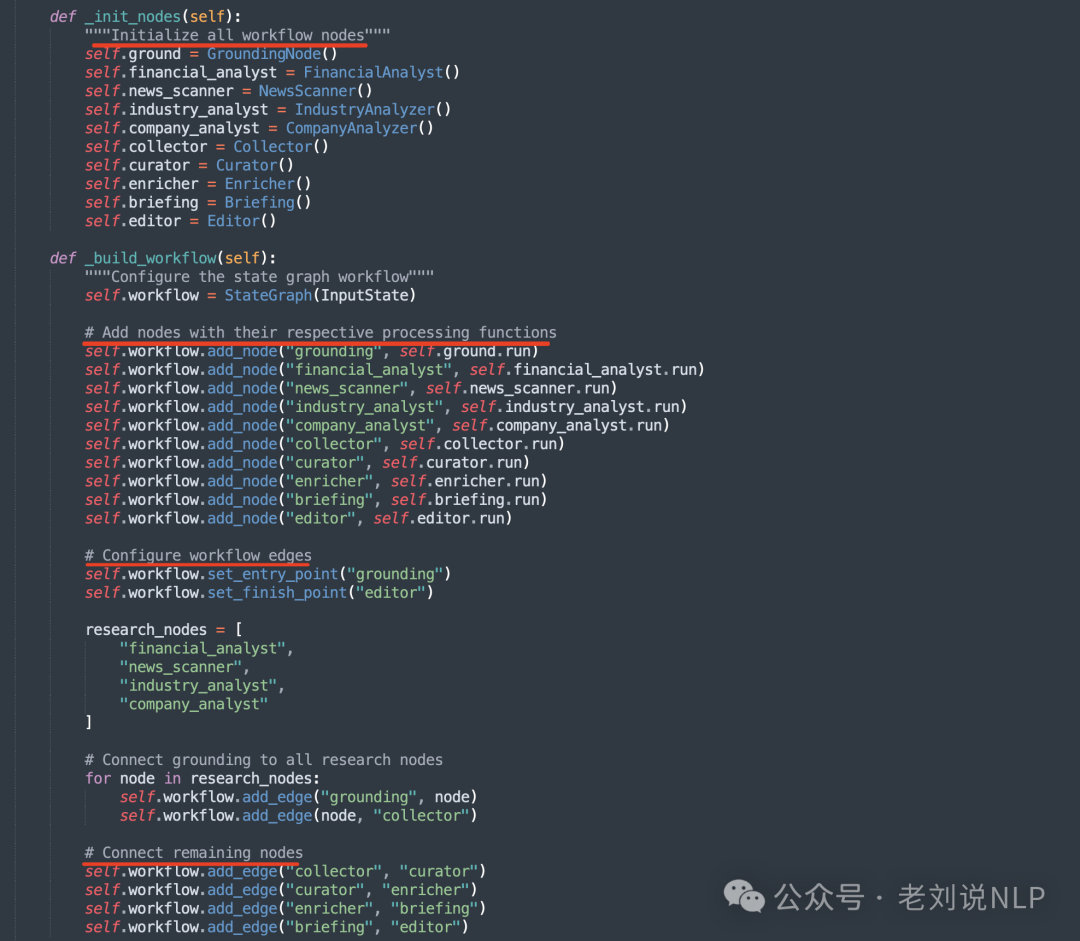
其中包括几个关键节点,如下:
CompanyAnalyzer(用于研究核心业务信息);
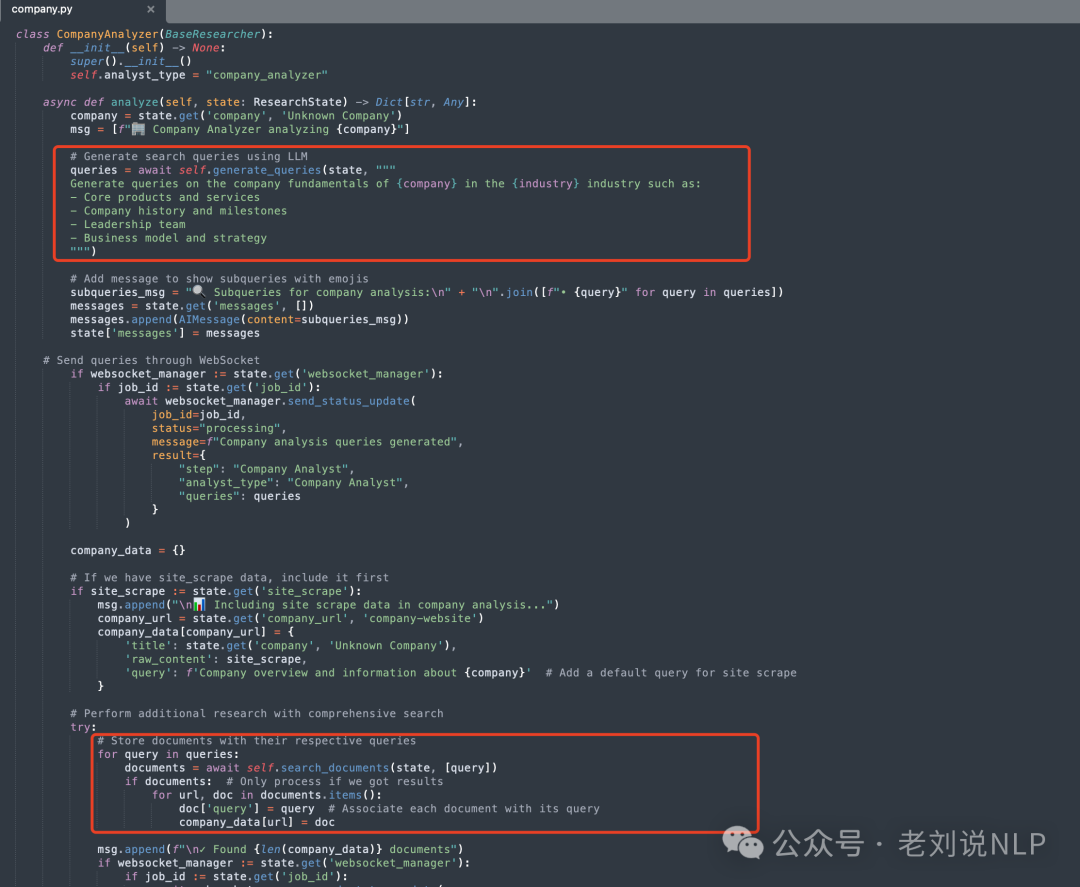
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/researchers/company.py
IndustryAnalyzer(用于分析市场定位和趋势);
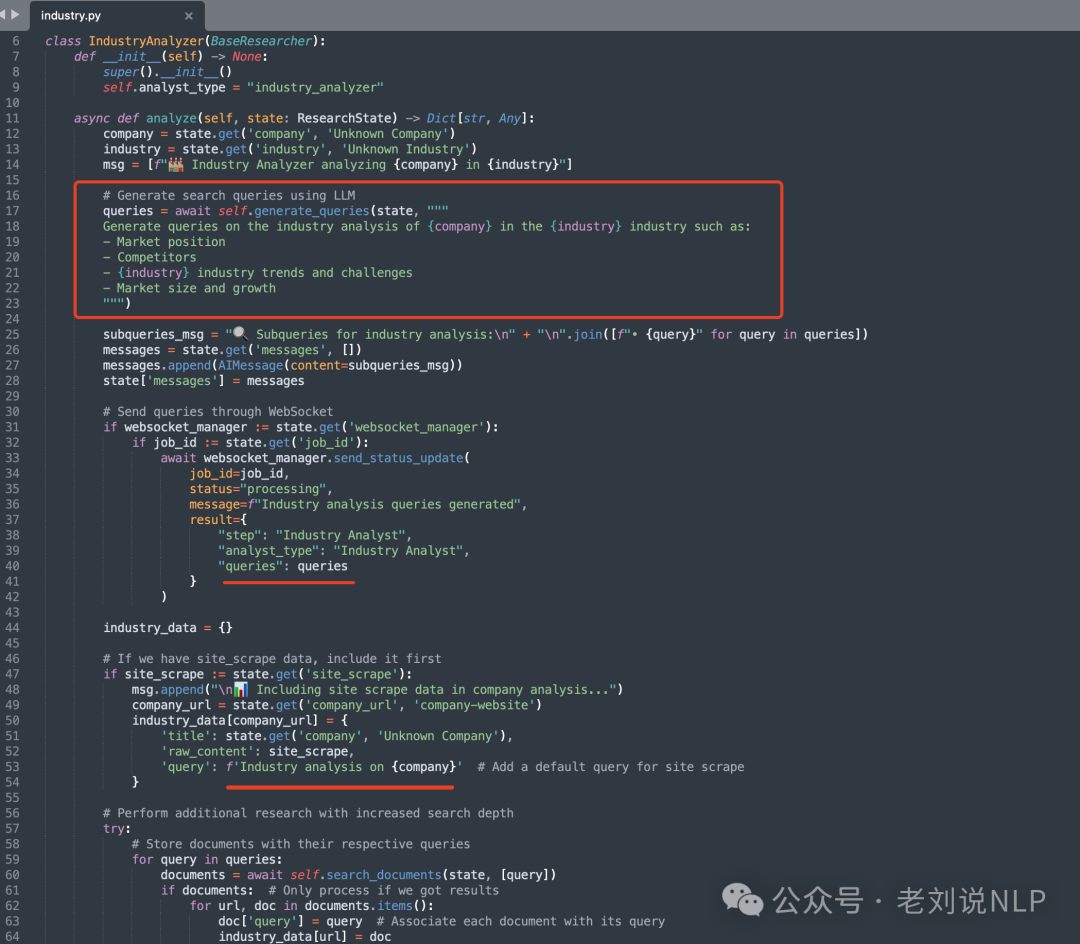
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/researchers/industry.py
FinancialAnalyst(用于收集财务指标和业绩数据);
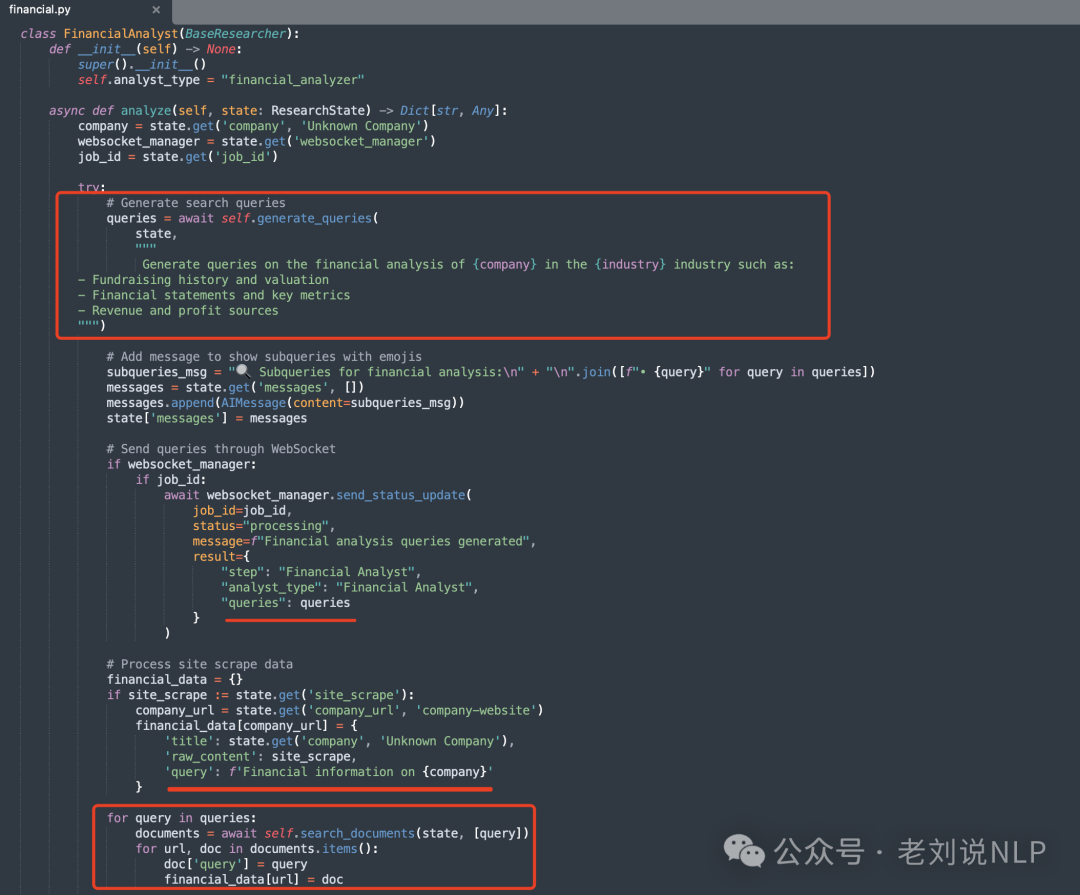
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/researchers/financial.py
NewsScanner(用于收集最新新闻和发展动态);
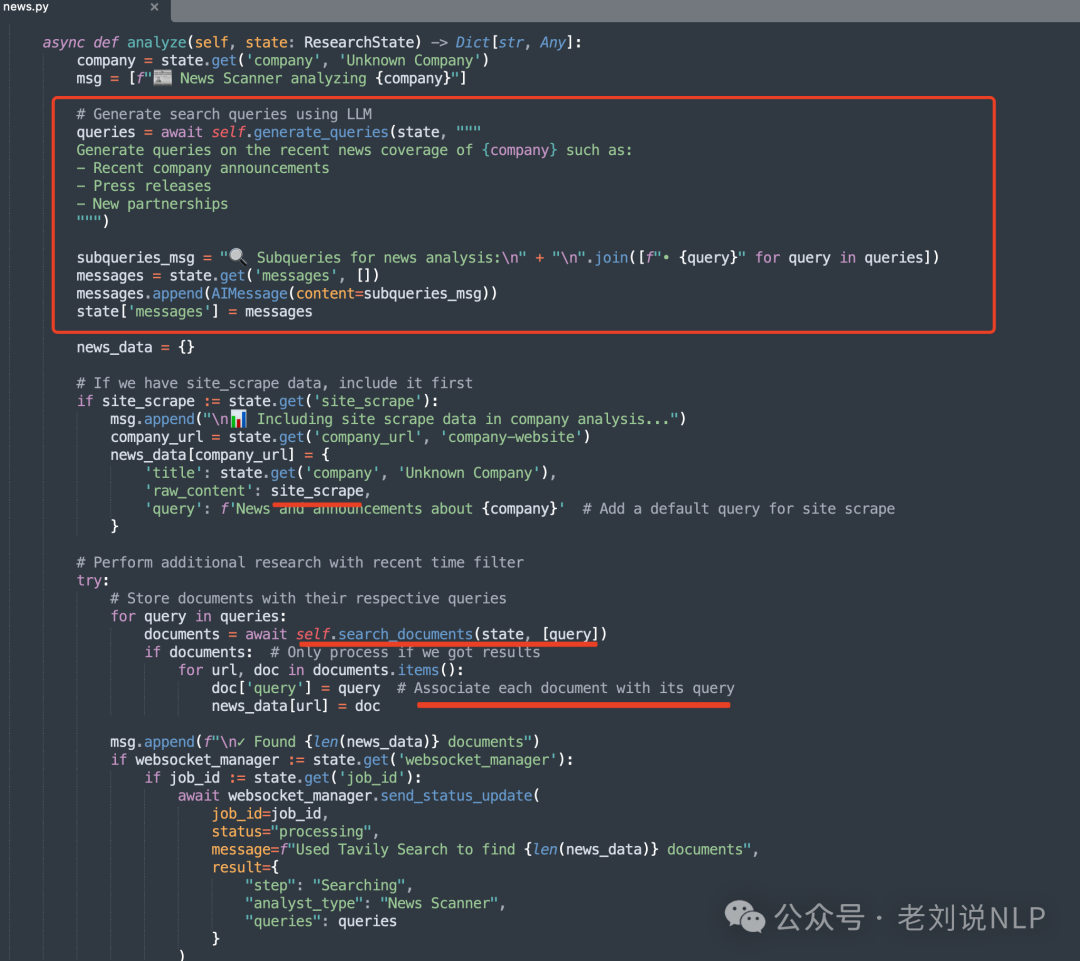
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/researchers/news.py
从上述几个源代码上,可以看到,核心逻辑都是,先进行subquery的生成过程,结果如下:
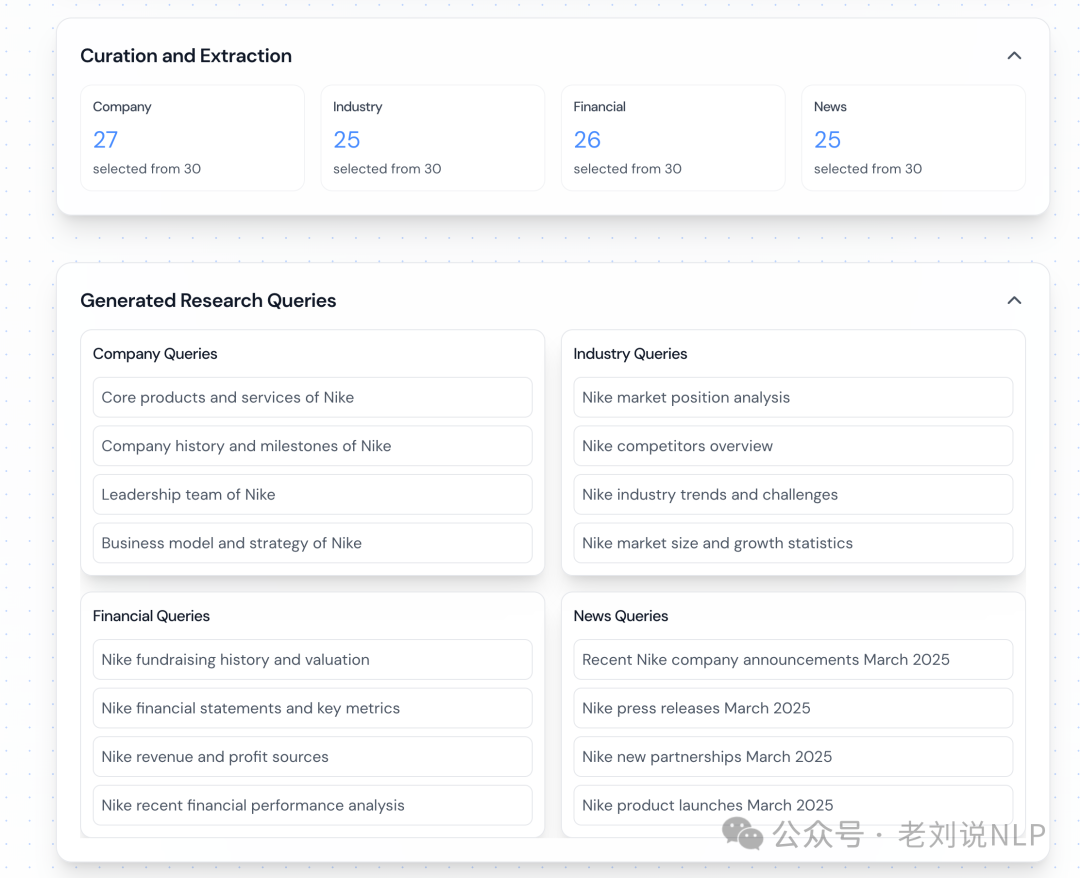
然后,会执行一个search_documents的操作,这个用的是tavily(https://tavily.com/),是一个面向AI搜索的内容搜索引擎,类似于国内的bocha,每个默认都是返回5个文档结果。

地址在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/researchers/base.py
上述几个都是并行处理的,在拿到这些数据之后,开始进行汇总分析。所以会有后续几个处理节点。
Collector(用于汇总所有分析器的研究数据);
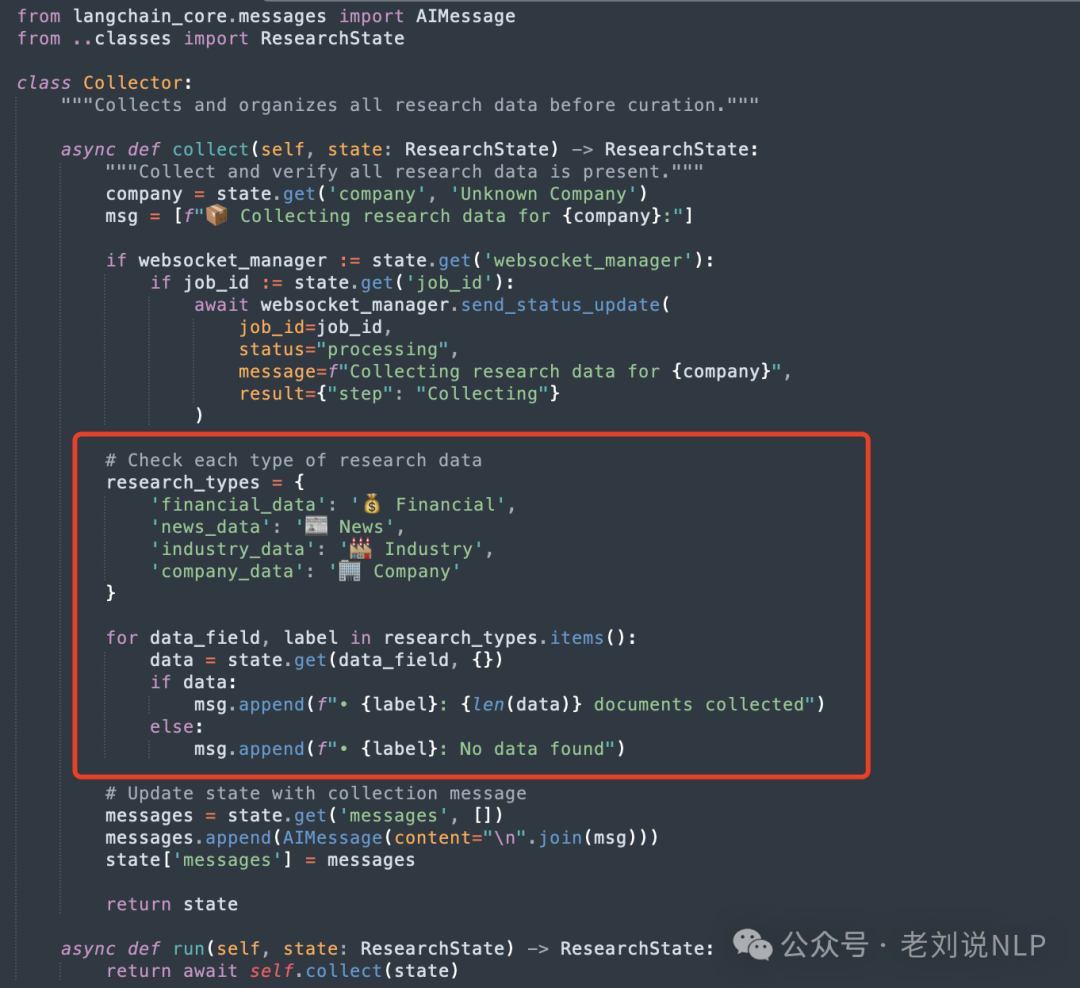
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/collector.py
Curator(用于实现内容过滤和相关性评分,文档由Tavily的AI驱动搜索进行评分,需要达到最低阈值(默认0.4)才能继续,分数反映与特定研究查询的相关性,更高的分数表示与研究意图更好的匹配,内容被标准化和清理,URL被去重和标准化,文档按相关性分数排序);
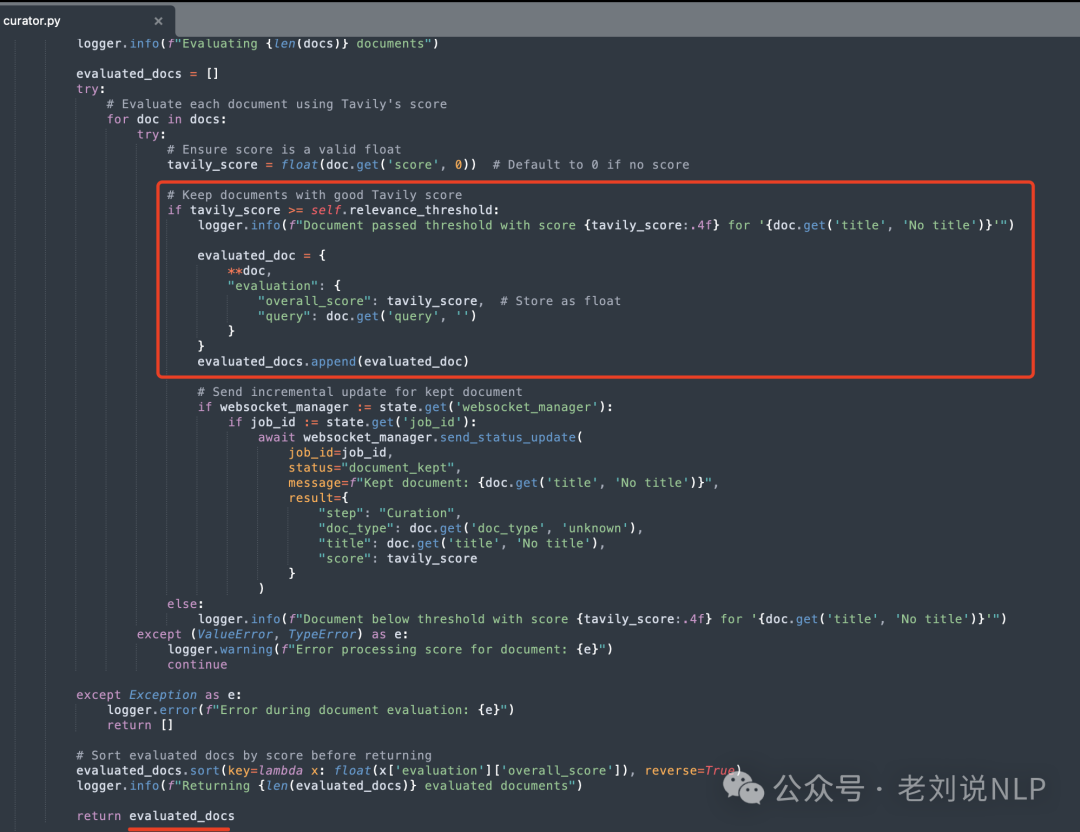
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/curator.py
Enricher(遍历不同类型的文档(如财务数据、新闻数据等),检查哪些文档需要添加原始内容。对每种类型的文档,调用fetch_raw_content 获取原始内容,相当于内容兜底)
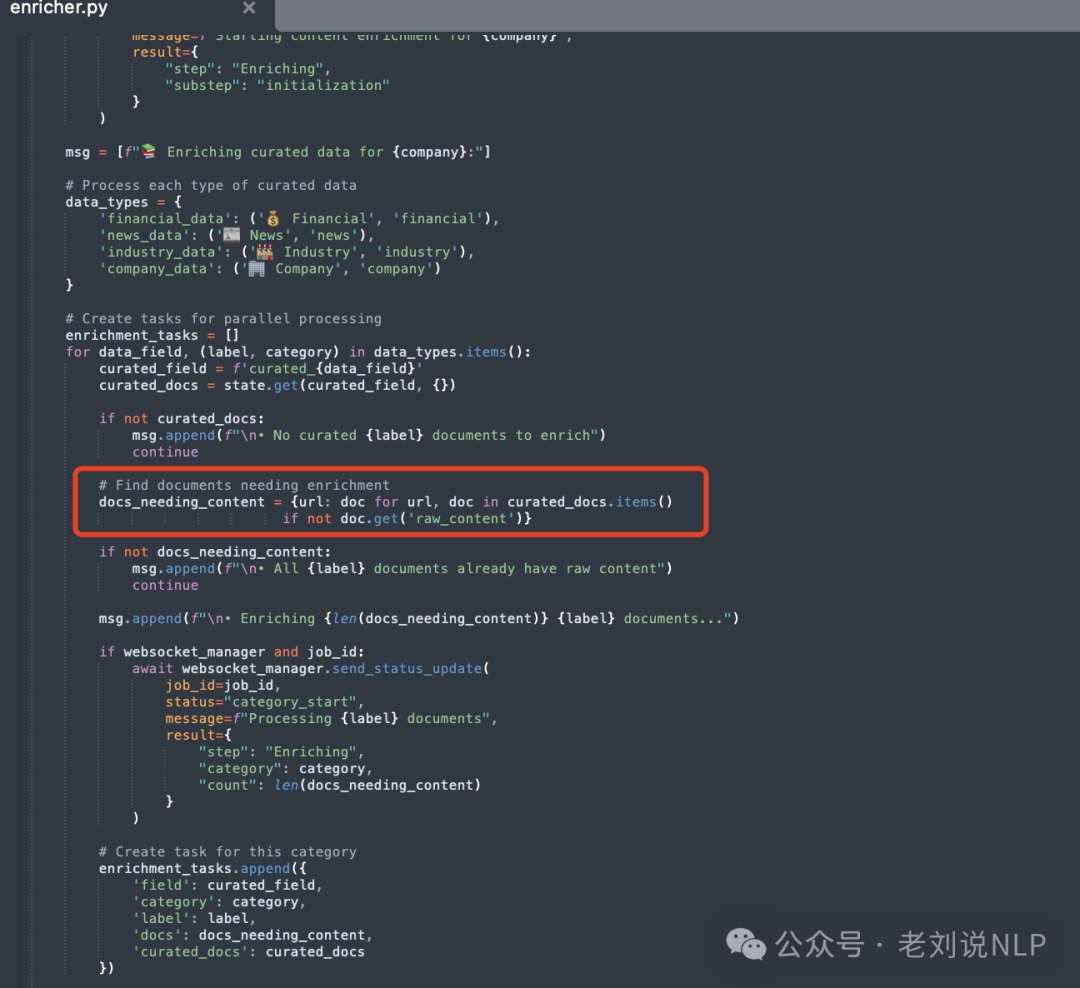
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/enricher.py
Briefing(用于使用Gemini 2.0 Flash生成特定类别的摘要,注意,这个摘要,是从不同的类别来做的,就是上面提到的news、indusrtry这些);
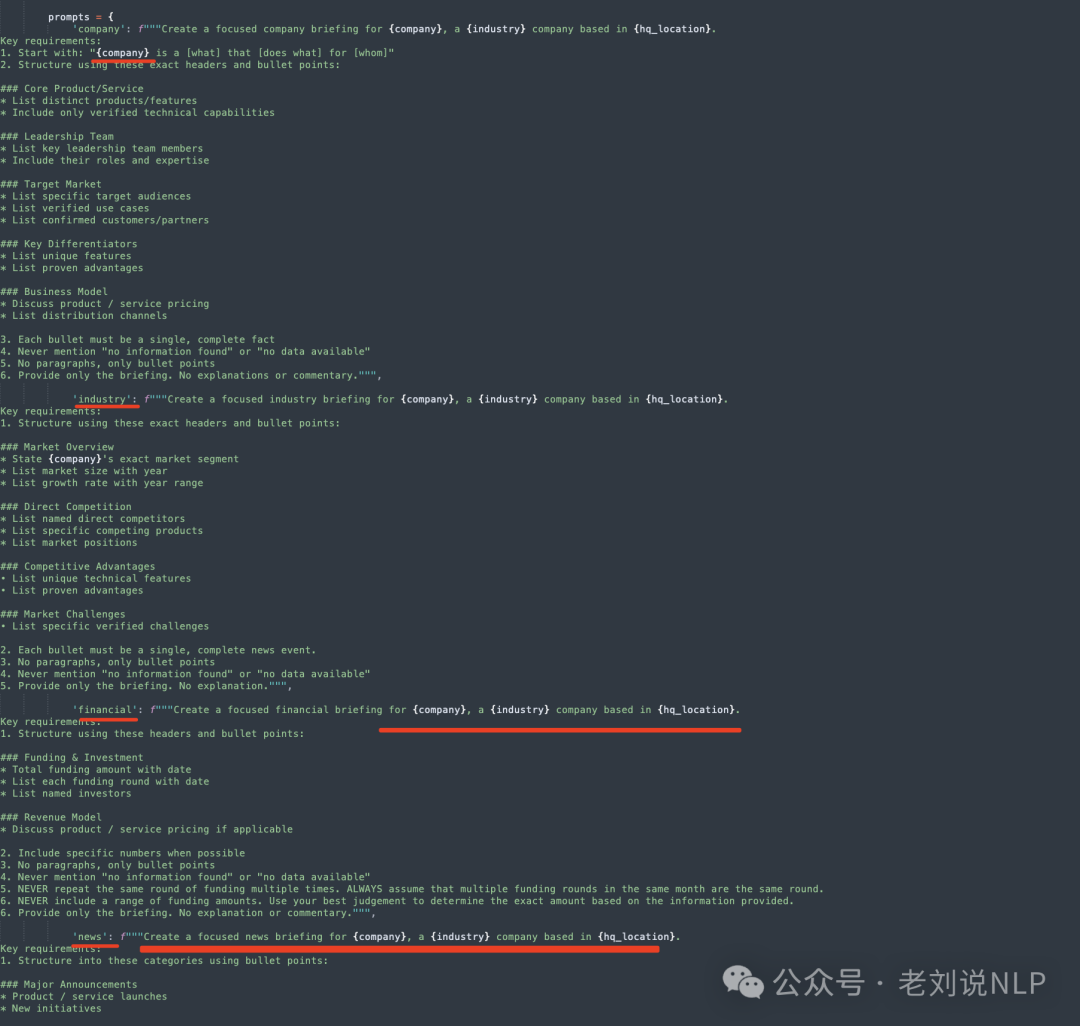
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/briefing.py
Editor(用于使用使用gpt-4.1-mini将简报编译和格式化为最终报告)
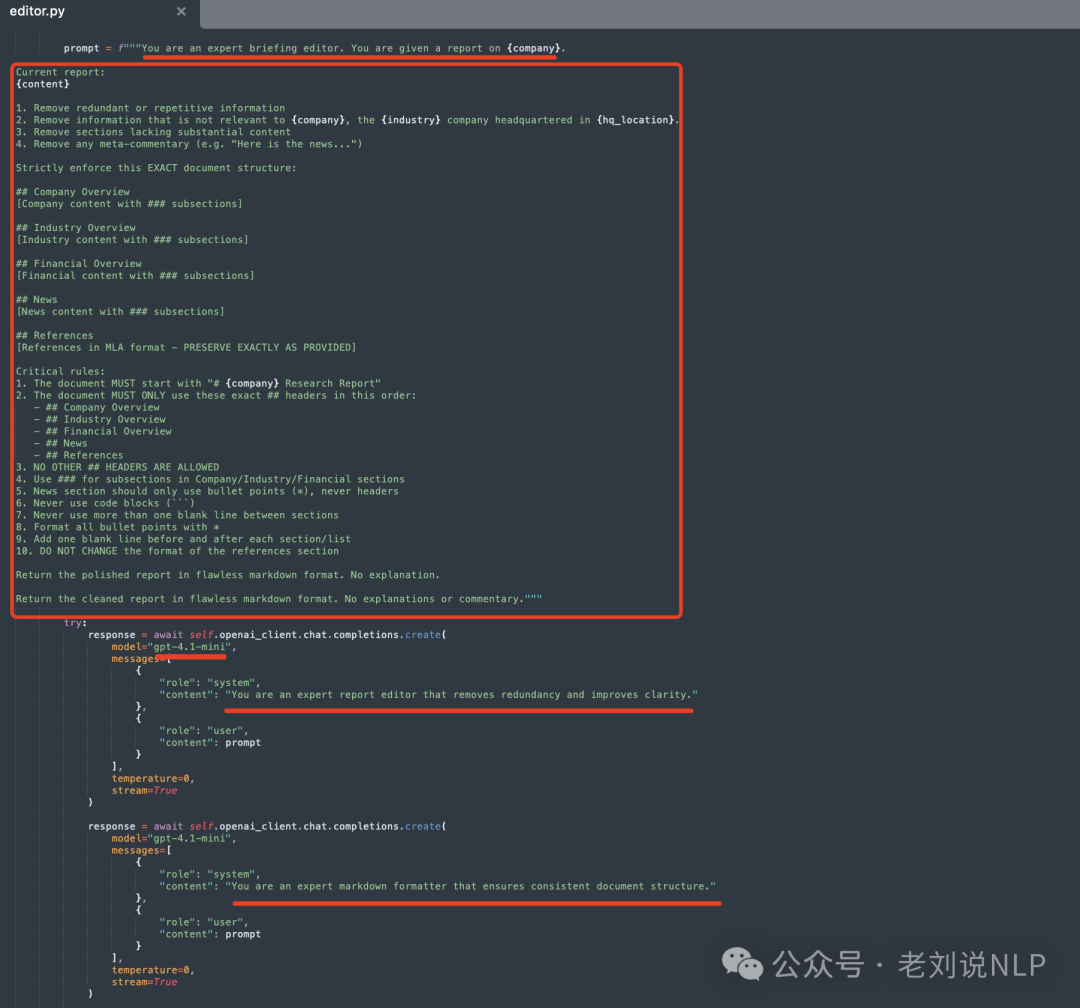
代码在:https://gitcode.com/gh_mirrors/co/company-research-agent/blob/main/backend/nodes/editor.py
所以,这么一看,这个项目就拆解完了,并不复杂,核心还是在于流程设计。
一、多模态文档大模型PP-DOCBEE的数据合成策略
文档智能进展,来看看多模态文档理解大模型的工作,《PP-DOCBEE: IMPROVING MULTIMODAL DOCUMENT UNDERSTANDING THROUGH A BAG OF TRICKS》,https://github.com/PaddlePaddle/PaddleMIX,主要是针对中文文档做的多模态大模型优化。
策略主要有如下几个:
一个是开发针对文档场景的数据合成策略,生成了一个高质量的中文文档理解数据集PPInfinityDocData,并收集了330万条来自各种文档来源的公共数据,该策略针对文本丰富文档、表格和图表三种典型文档类型。形成数据集如下:
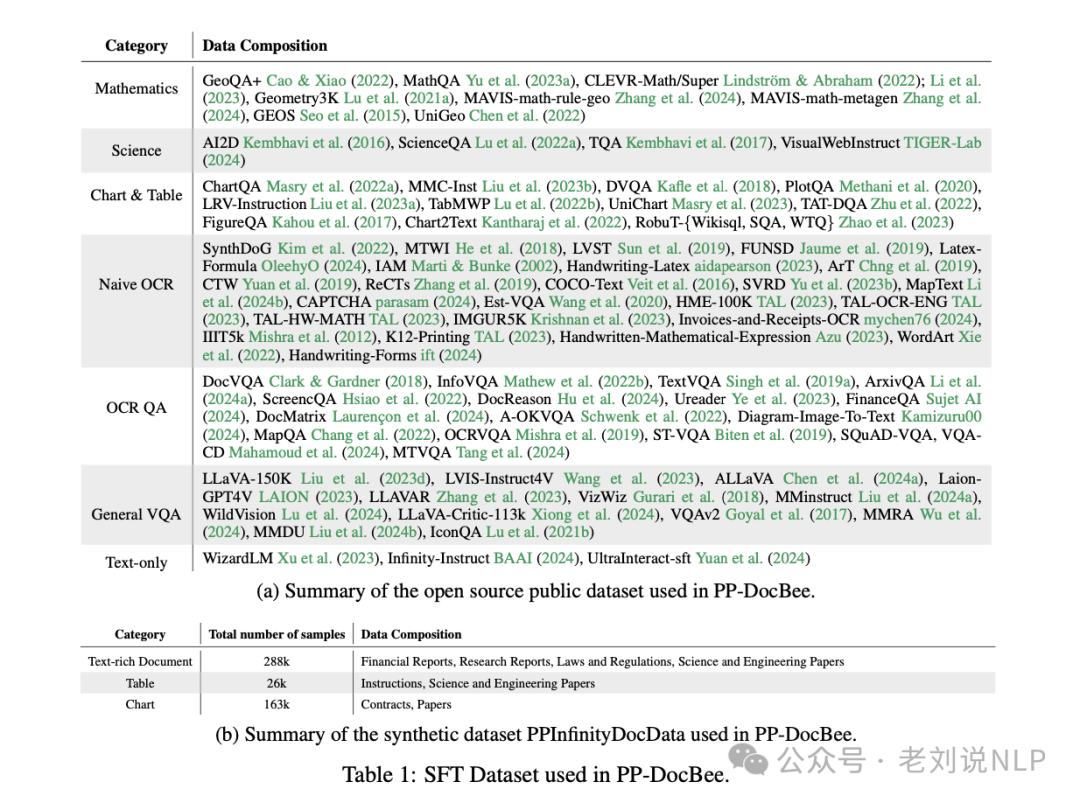
这里关于数据合成的点可以看看,整个流程图如下:
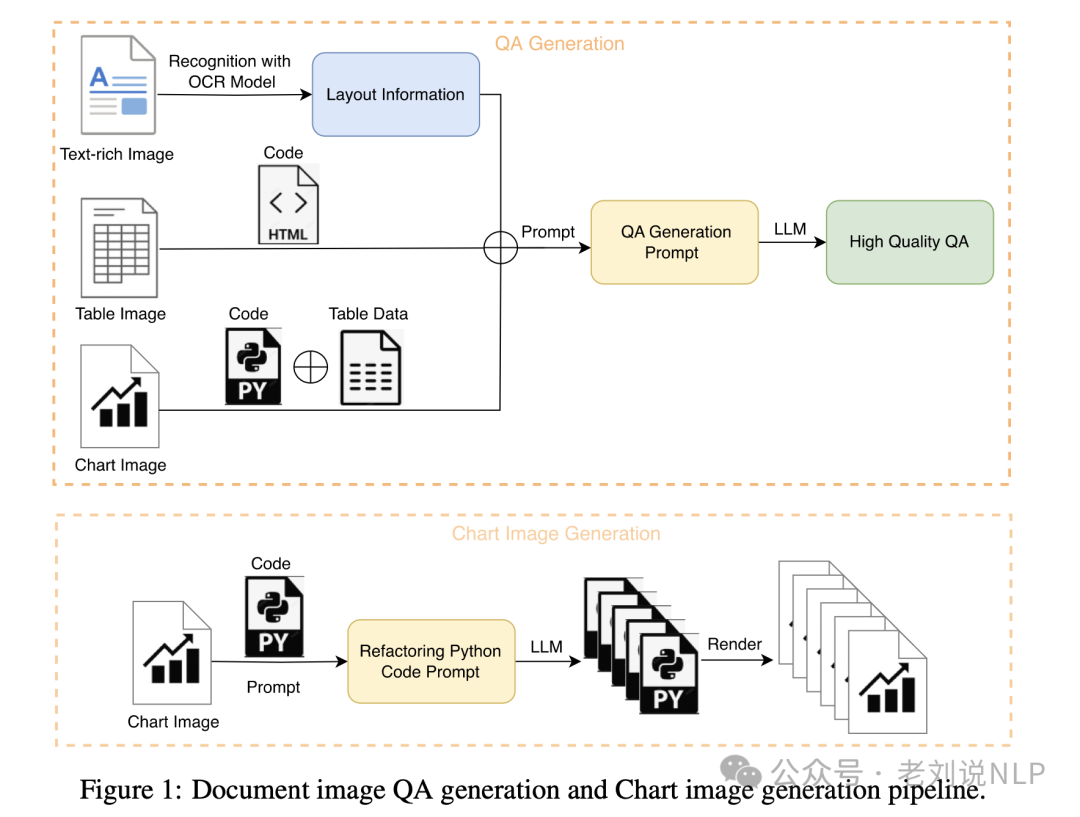
另外,分别针对不同的要素做数据合成,包括Text-rich Document QA Generation、Chart Image Generation、 Chart QA Generation、Table QA Generation,实现逻辑就是提示llm做生成。
其中:
对于Text-rich Document QA Generation,使用prompt如下:

对于Chart Image Generation,使用prompt如下:

使用的就是图像反向渲染:
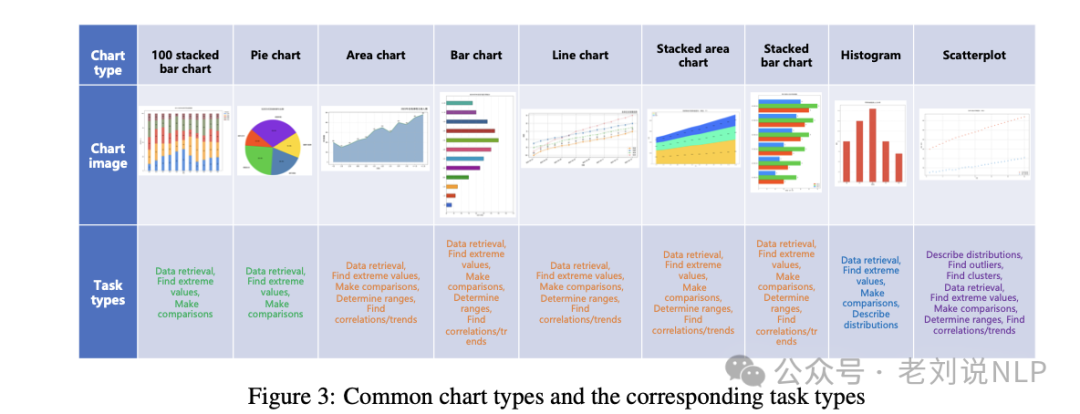
对于Chart QA Generation,使用prompt如下:

对于Table QA Generation,使用prompt如下:

实现的效果如下:

一个是在训练阶段实施动态数据比例采样机制,优化训练过程,分配不同的采样权重给不同数据和来源,提升高质量数据的训练比例,并且扩展图像resize阈值,增加数据集的分辨率分布,提升模型的视觉特征理解能力。在监督微调阶段,视觉编码器被冻结,LLM参数被更新。PP-DocBee在包含近500万样本的数据集上训练了16000次。
一个是在推理阶段对低分辨率图像进行比例放大,确保图像特征的全面性,并在推理阶段引入OCR识别文本作为辅助信息,增强模型在包含清晰有限文本的图像上的表现。具体实验上,从Qwen2-VL-2B模型初始化,使用Vision Transformer(ViT)作为视觉编码器和1.5B Qwen2大型语言模型(LLM)作为语言解码器。
在最终使用上,在应用方面,可以用于多模态文档RAG问答,召回出对应的文档页面图像,然后做qa,例如如下两个例子。

总结
本文主要介绍了Deepresearch变体之公司报告自动生成company-research-agent的实现拆解以及多模态文档大模型PP-DOCBEE的数据合成策略,两者其实都是工程策略,前者在于整体设计,后者在于数据策略,这是我们能够学习和参考的点。
参考文献
1、https://gitcode.com/gh_mirrors/co/company-research-agent
2、https://github.com/PaddlePaddle/PaddleMIX
(文:老刘说NLP)