


大型语言模型(LLMs)在上下文知识理解方面取得了令人瞩目的成功。
近日,一项来自 ICML 2025 的新研究《Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding》揭示了大型语言模型中一个重要现象:在注意力机制的查询 (Q) 和键 (K) 表示中存在非常集中的极大值,而在值 (V) 表示中却没有这种模式。这一现象在使用旋转位置编码 (RoPE) 的现代 Transformer 模型中普遍存在,对我们理解 LLM 内部工作机制具有重要意义。
本研究由罗格斯大学张永锋教授的团队完成,一作为金明宇,罗格斯大学博士生,在 ACL、ICML、AAAI、NAACL、COLM、ICLR、EMNLP、COLING 等顶级会议上发表过论文。

-
论文标题:Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding
-
arXiv 链接:https://arxiv.org/pdf/2502.01563
-
代码链接:https://github.com/MingyuJ666/Rope_with_LLM
研究亮点
极大值如何影响模型性能
当我们谈论大型语言模型的理解能力时,通常将其知识分为两类:参数知识(存储在模型权重中的事实和信息)和上下文知识(从当前输入文本中获取的信息)。本研究通过一系列精心设计的实验,揭示了自注意力模块中极大值的存在与上下文知识理解之间的关键联系。
四大核心发现
1. 极大值在 Q 和 K 中高度集中分布
研究发现,这些极大值在每个注意力头的特定区域高度集中。这一现象非常反常识,因为 LLM 内部每个注意力头的运算理论上应该是独立的,但这些极大值的分布却显示出惊人的一致性。研究团队通过可视化方法清晰地展示了这一分布特征,横跨多个层和头,这种规律性模式与传统认知形成鲜明对比。
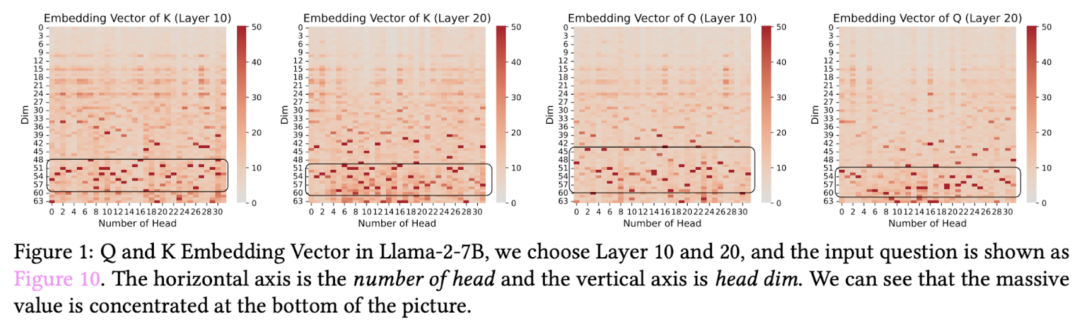
更引人注目的是,这一极大值现象仅存在于使用 RoPE(旋转位置编码)的模型中,如 LLaMA、Qwen 和 Gemma 等主流模型。而在未使用 RoPE 的模型(如 GPT-2 和 OPT)中不存在这种模式。这一发现将极大值现象直接与位置编码机制建立了联系。
2. Q 和 K 中的极大值对理解上下文知识至关重要
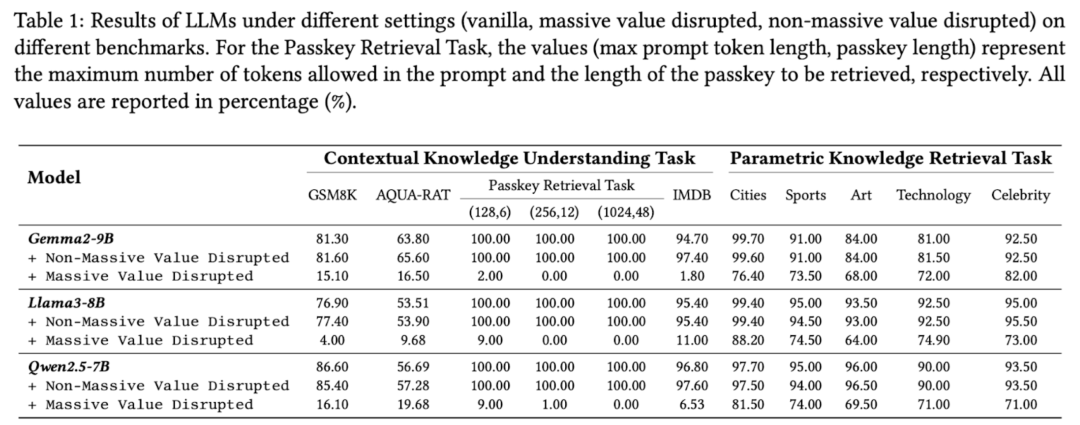
通过设计「破坏性实验」,研究团队将极大值重置为平均值,观察模型性能变化。结果表明,这些极大值主要影响模型处理当前上下文窗口中的信息的能力,而非影响从参数中提取的知识。在需要上下文理解的任务上,破坏极大值会导致性能的灾难性下降。
例如,在「大海捞针」类型的任务中,模型需要从大量文本中检索特定信息。当极大值被破坏时,模型在此类任务上的表现几乎完全崩溃。这直接说明了极大值对上下文理解的关键作用。
相比之下,对于只需要参数知识的任务(如「中国首都是哪里」),破坏极大值对性能影响有限。这种对比鲜明的结果表明,极大值特别与上下文信息处理相关,而非参数知识检索。
3. 特定量化技术能更好地保存上下文知识理解能力
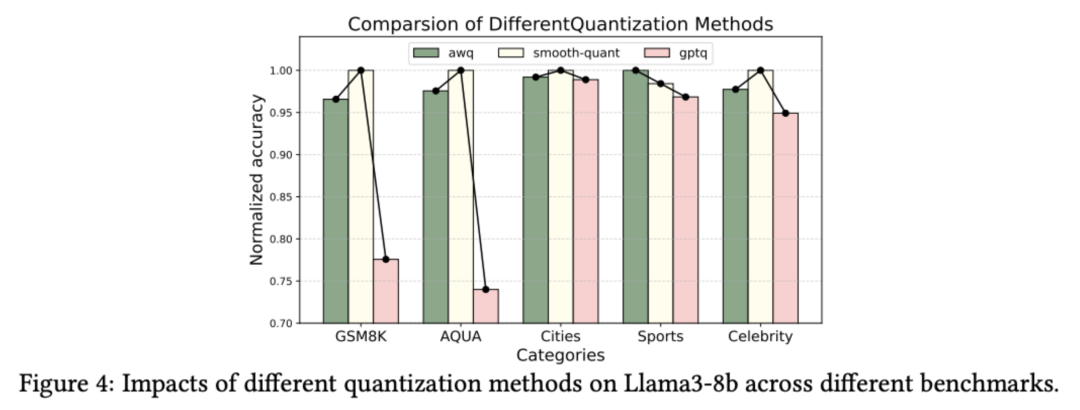
随着大型语言模型的普及,量化技术成为降低计算和存储需求的关键手段。然而,不同的量化方法对模型性能的影响各异。研究发现,专门处理极大值的量化方法(如 AWQ 和 SmoothQuant)能有效维持模型的上下文理解能力,而未特别处理极大值的方法则会导致性能明显下降(GMS8K 和 AQUA 数据集)。
这一发现为量化技术的设计和选择提供了重要指导,特别是对保留模型的上下文理解能力至关重要的应用场景。设计新的量化方法时应重点考虑保护 Q 和 K 中的大值,对于优先保持上下文理解能力的应用场景,AWQ 和 SmoothQuant 等方法更为合适。
4. 极大值集中现象由 RoPE 引起,并在早期层就已出现
研究通过深入分析发现,RoPE 位置编码使 Q 和 K 中的低频区域受位置信息影响较小,从而导致极大值集中现象。这种现象从模型的最初层就开始显现,并随着层数增加而变得更加明显。
由于 RoPE 只作用于 QK,而不作用于 V,这也解释了为什么只有 QK 存在极大值集中现象。这一发现不仅解释了极大值的来源,也揭示了 RoPE 在大型语言模型中的工作机制。并且我们检查了有 rope 的模型和没有 rope 的模型,结果如图所示,llama,qwen 都有集中的极大值;相反 gpt-2,jamba,opt 就没有。

实验结果
极大值对不同知识任务的差异化影响
研究团队设计了一系列实验,系统评估极大值对不同类型知识任务的影响。结果显示出明显的差异化效应:
A. 参数知识检索任务的韧性
当大值被破坏时:
-
城市类任务仍然保持 76%-88% 的准确率,仅下降 15-20%
-
体育、艺术和技术类别任务保持在 65%-75% 的表现
-
名人类别表现尤其稳定,各模型均保持 70% 以上的准确率
这些结果表明,参数知识检索主要依赖于模型权重中存储的知识,受极大值破坏的影响相对较小。
B. 上下文知识理解任务的灾难性下降
相比之下,依赖上下文理解的任务在极大值被破坏后表现灾难性下降:
1. 数学推理任务出现严重退化
-
GSM8K: 从 81.30% 降至 15.10%
-
Llama3-8B: 从 76.90% 降至 4.00%
-
Qwen2.5-7B: 从 86.60% 降至 16.10%
2. 密钥检索任务 (Passkey Retrieval) 准确率从 100% 直接崩溃至接近 0%
3. IMDB 情感分析从 94% 以上下降至个位数
这些对比鲜明的结果强有力地证明了极大值在上下文知识理解中的关键作用。
C. 非大值破坏的对照实验
为验证研究发现的可靠性,研究团队还设计了对照实验:当仅破坏非极大值部分时,所有任务的表现保持稳定,变化通常小于 ±1%。这进一步确认了极大值在上下文知识理解中的特殊重要性。
研究意义与影响
这项研究首次揭示了大型语言模型内部自注意力机制中极大值的存在及其功能,为理解模型如何处理上下文信息提供了新视角。研究结果对 LLM 的设计、优化和量化都具有重要启示:
-
模型设计方面:突显了位置编码机制(尤其是 RoPE)对模型理解上下文能力的影响,为未来模型架构设计提供了新思路。
-
模型优化方面:识别出极大值是上下文理解的关键组件,为针对性地提升模型上下文理解能力提供了可能路径。
-
模型量化方面:强调了保护极大值在模型压缩过程中的重要性,为开发更高效的量化方法提供了方向。
未来方向
该研究打开了多个值得进一步探索的方向:
-
探索是否可以通过特殊设计增强或调整极大值分布,从而提升模型的上下文理解能力。
-
研究极大值现象在不同架构、不同规模模型中的普遍性和特异性。
-
设计更有针对性的量化方法,专门保护与上下文理解相关的极大值。
-
探索极大值与模型其他特性(如对抗稳健性、推理能力等)之间的潜在联系。
这项研究不仅加深了我们对大型语言模型内部工作机制的理解,也为未来更高效、更强大的模型开发铺平了道路。通过揭示极大值的关键作用,研究者们为我们提供了解锁大语言模型上下文理解能力的一把新钥匙。
©
(文:机器之心)