
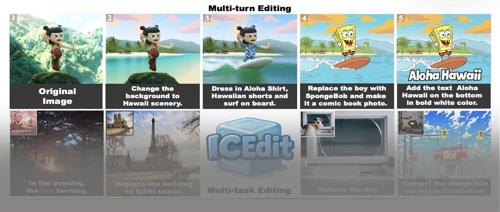

极市导读
该项目提出了一种基于上下文的零样本图像编辑框架,结合LoRA-MoE混合微调和早期噪声过滤策略,仅需极少量数据和参数即可实现高精度的指令图像编辑,解决了现有方法中精度与效率难以兼顾的难题。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

文章链接:https://arxiv.org/pdf/2504.20690
项目链接:https://river-zhang.github.io/ICEdit-gh-pages/
Git链接:https://github.com/River-Zhang/ICEdit
Demo链接:https://huggingface.co/spaces/RiverZ/ICEdit
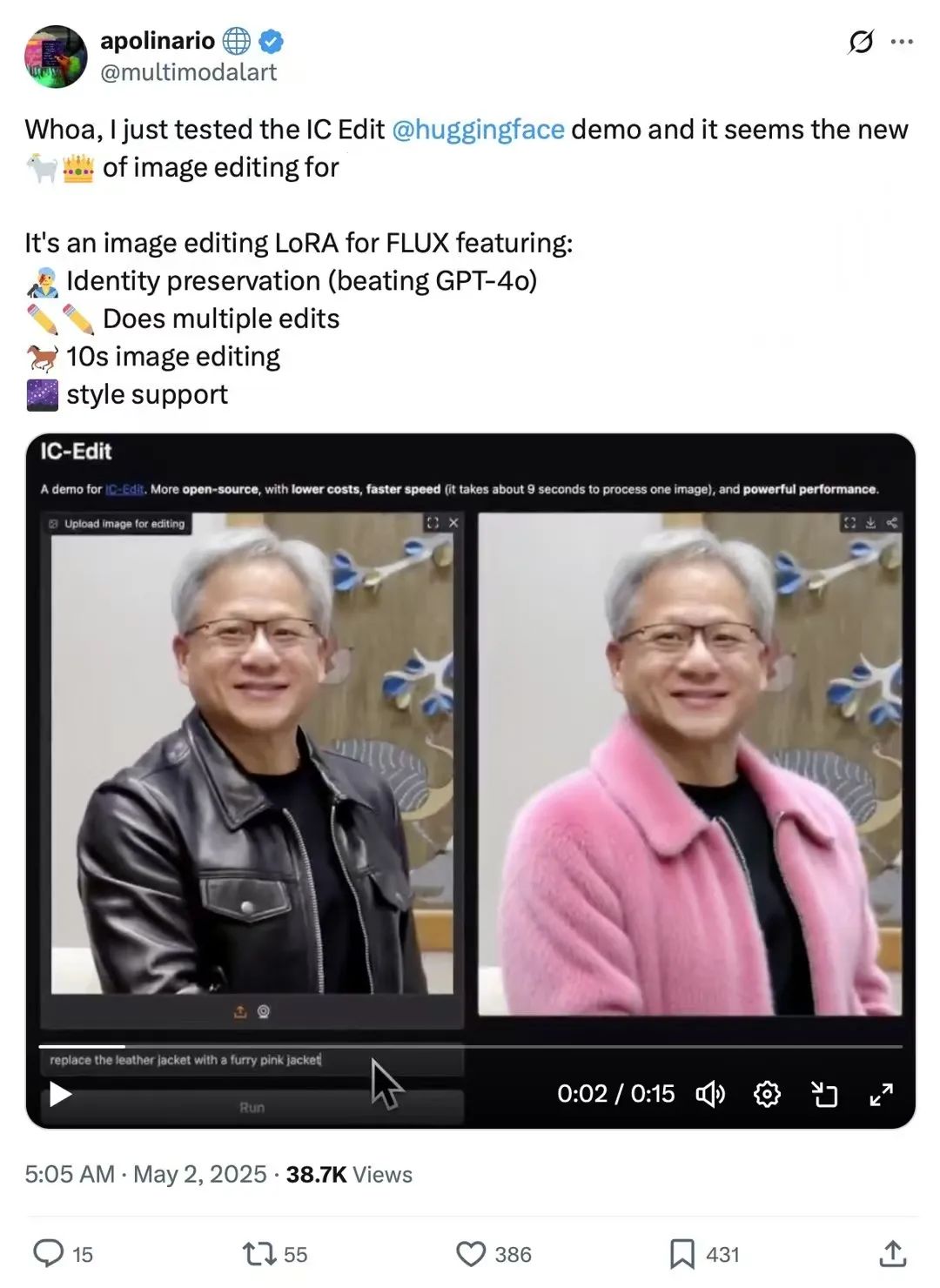
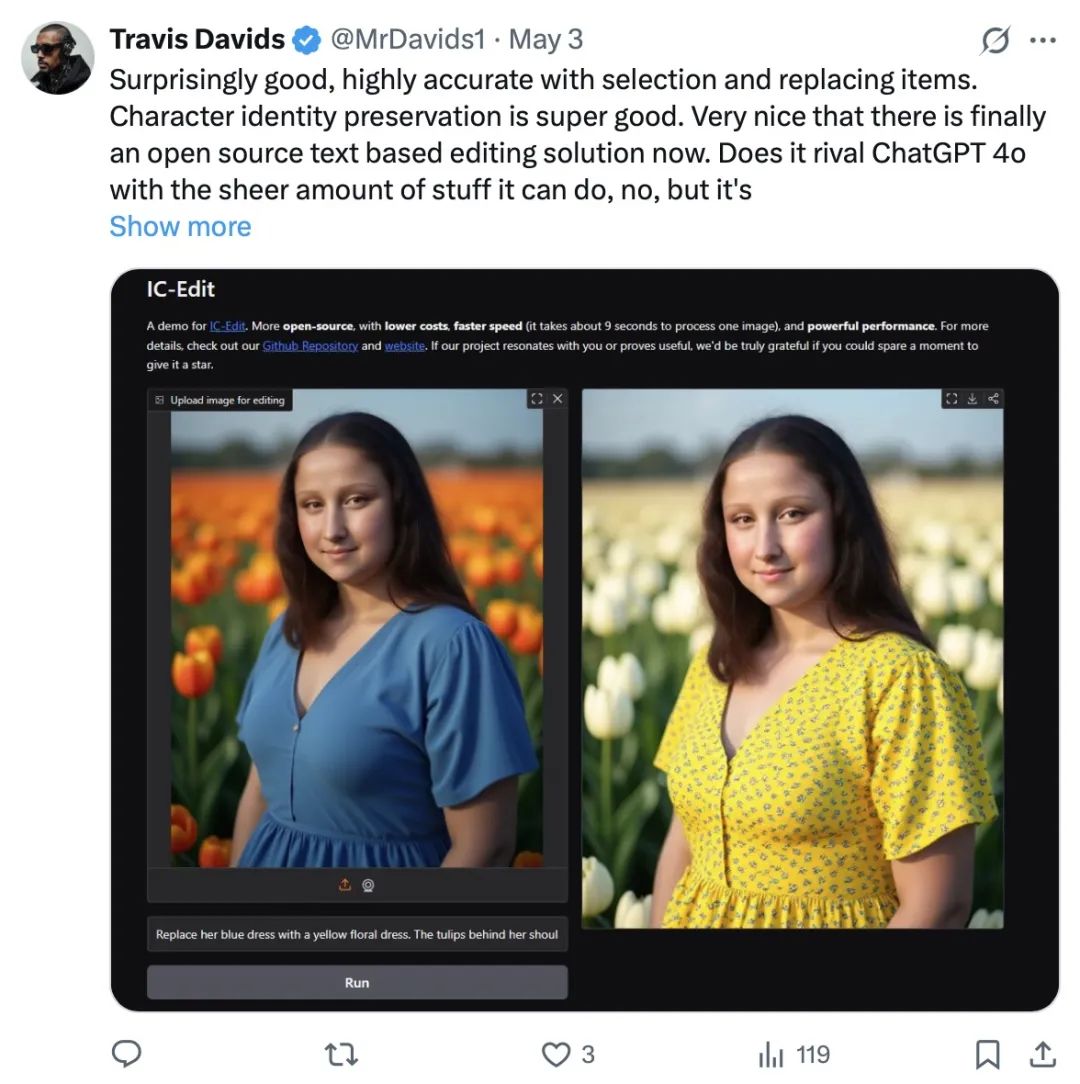
五一假期期间,ICEdit爆火🔥,登上了hugging face周榜第二,仅次于qwen3!外国网友在twitter上纷纷秀出使用效果



亮点直击
探索了大型预训练扩散Transformer(如FLUX)的编辑能力,并引入了一种新颖的上下文编辑范式,该范式能够实现有效的指令图像编辑,而无需修改模型架构或进行大量微调。 提出了LoRA-MoE混合微调方法,用于参数高效的编辑任务适应,并结合基于VLM的噪声剪枝策略——早期过滤推理时间缩放。这种协同设计在保持上下文编辑框架高效性的同时,显著提升了编辑精度。 实验表明,本文方法仅需0.5%的训练数据和1%的可训练参数(相较于现有方法),即可实现最先进的编辑性能,有效解决了长期困扰先前方法的精度-效率权衡问题。
总结速览
解决的问题
-
精度与效率的权衡问题:
-
现有基于微调的方法(Fine-tuning)需要大量计算资源和数据集,效率低。 -
免训练方法(Training-free)在指令理解和编辑质量上表现不佳,精度不足。 -
指令理解与编辑质量不足:
-
免训练方法难以准确解析复杂指令,导致编辑效果不理想。 -
微调方法依赖大规模数据训练(如 450K~10M 样本),计算成本高。 – 初始噪声选择影响编辑质量: -
不同的初始噪声会导致不同的编辑效果,如何优化噪声选择以提高输出质量是关键挑战。
提出的方案
-
基于上下文(In-Context)的零样本编辑框架:
-
利用 DiT 的上下文感知能力,通过“上下文提示”(in-context prompts)实现免训练的指令编辑,避免结构调整。 -
LoRA-MoE 混合调优策略:
-
结合 LoRA(低秩适应) 和 MoE(混合专家) 动态路由,提高模型灵活性,减少训练需求。 -
仅需少量数据微调,无需大规模重新训练。 -
早期噪声过滤推理优化(Early Filter Inference-Time Scaling):
-
利用视觉语言模型(VLMs)在去噪早期阶段筛选更优初始噪声,提升编辑质量。
应用的技术
-
扩散 Transformer(DiT):
-
利用其强大的生成能力和上下文感知特性,实现高效指令编辑。 -
LoRA + MoE(混合专家):
-
LoRA:参数高效微调,减少计算开销。 -
MoE:动态专家路由,增强模型对不同编辑任务的适应能力。 -
视觉语言模型(VLMs):
-
用于噪声筛选,优化初始噪声选择,提高生成质量。 -
上下文提示(In-Context Prompting):
-
通过双联画(diptych)形式(源图 + 编辑提示)实现零样本编辑。
达到的效果
-
数据与参数高效性:
-
仅需 0.5% 训练数据 和 1% 可训练参数,超越现有 SOTA 方法。 -
编辑质量提升:
-
在 Emu Edit 和 MagicBrush 基准测试中表现优异,VIE-score 78.2(优于 SeedEdit 的 75.7)。 -
计算效率优化:
-
避免大规模微调,减少计算资源需求,同时保持高精度。 -
通用性强:
-
适用于多样化编辑任务(如参考引导合成、身份保持编辑等),无需额外结构调整。
方法
本节首先探索原始DiT生成模型中的上下文编辑能力,并提出基于指令的图像编辑上下文编辑框架。经过全面分析后,引入LoRA-MoE混合微调到框架中,配合小型编辑数据集,显著提升编辑质量和成功率。最后,提出早期过滤推理时间缩放策略,在推理阶段选择更好的初始噪声以增强生成质量。
DiT上下文编辑能力探索
带编辑指令的上下文生成。受近期研究[16,17,41,49]表明大规模DiT模型具有强大上下文能力的启发,本文探索是否可以通过上下文生成实现图像编辑。为此,我们将编辑指令添加到专为上下文编辑设计的生成提示中。具体而言,设计如下形式的提示:“同一{主体}的并排图像:左侧描绘原始{描述},而右侧镜像左侧但应用{编辑指令}。”将此表述称为上下文编辑提示(IC提示)。借助T5文本编码器因其强大的句子级语义理解而被DiT广泛采用),该方法能有效解析此类扩展提示,实现精确且上下文连贯的编辑。
如下图3所示,上下文编辑提示(IC提示)使DiT模型能够以双联画格式生成编辑输出:左侧为与描述对齐的图像,右侧为根据编辑指令调整后的同一图像。为阐明此机制,检查了IC提示中编辑指令的注意力图,发现待修改区域的注意力值显著较高。这表明DiT模型能熟练解析并执行IC提示中的编辑指令,无需大量微调即可理解编辑指令并相应执行。

上下文编辑框架构建
基于上述观察,本文提出一种编辑框架,其中将左侧指定为参考图像可实现右侧的无缝编辑。分别基于文本到图像(T2I)DiT和修复DiT提出了两种免训练框架,如下图4所示。

对于T2I DiT框架,本文设计了一种隐式参考图像注入方法。首先对参考图像进行图像反转,保留各层和各步骤的注意力值。然后将这些值注入表示双联画左侧的标记中以重建图像,而右侧则在上下文生成期间基于预定义IC提示中的编辑指令生成。
相比之下,修复DiT框架提供了一种更直接的方法。由于它接受参考图像和掩码,预设一个并排图像,左侧为参考,右侧为掩码区域,并使用相同的IC提示引导修复过程。
前面图4展示了两种框架的操作,示例输出显示它们在编辑过程中保留参考图像身份的能力。然而,下表3的实验表明,两种框架在不同编辑任务中均无法始终提供稳定、鲁棒的结果,限制了其实用性。此外,T2I DiT方法需要额外的反转步骤,相比更简单的修复框架增加了计算需求。因此,基于修复的框架是进一步优化的更可行候选方案。
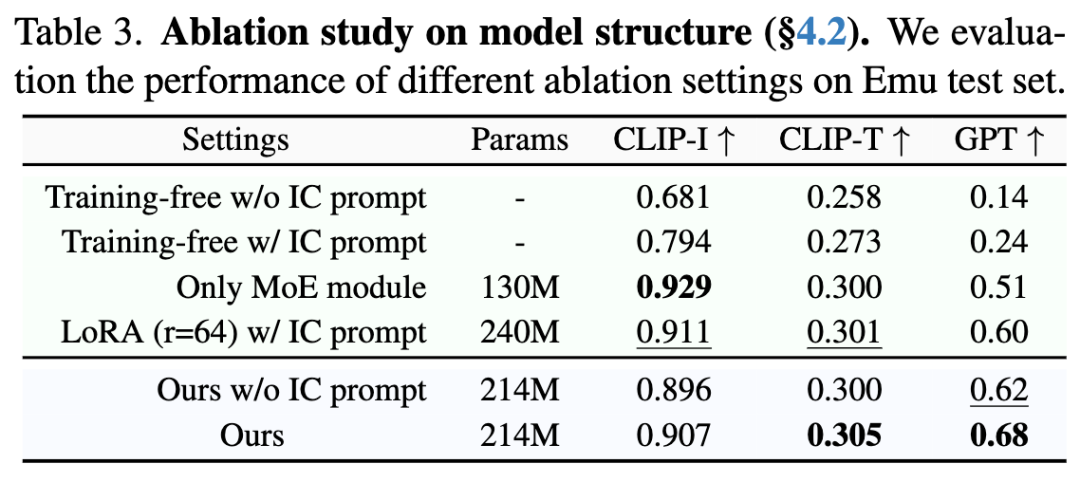
LoRA-MoE混合微调
基于上述分析,本文将方法总结为一个函数 ,它将源图像 和编辑指令 映射到目标编辑输出
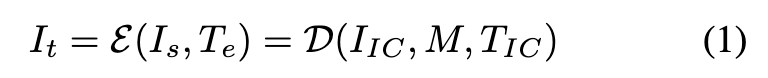
其中 为修复扩散Transformer, 表示上下文图像输入——左侧放置源图像 ,右侧由固定二值掩码 遮盖。编辑指令 被转换为上下文编辑提示 。
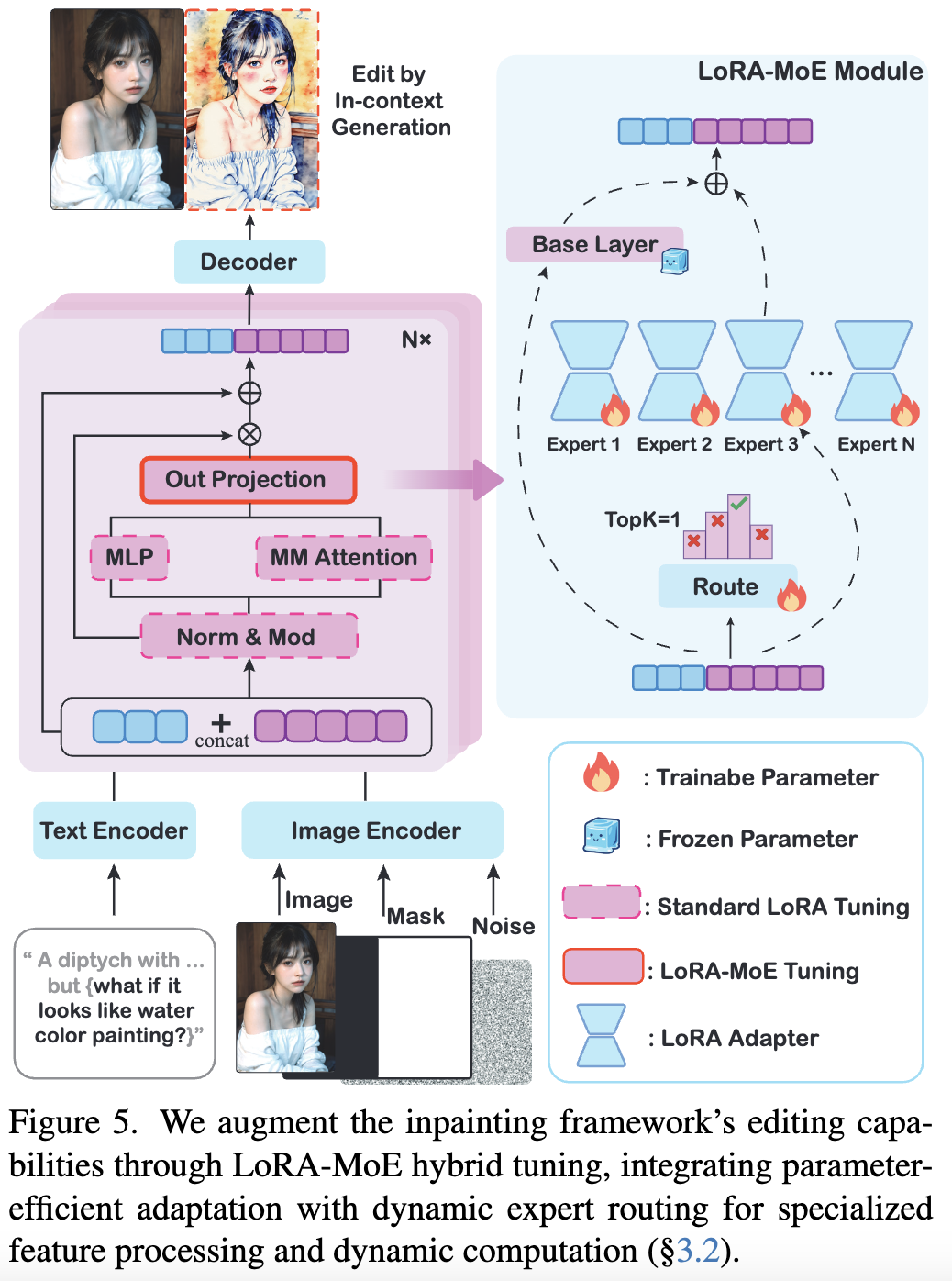
LoRA调优
为增强该框架的编辑能力,本文从公开资源中整理了一个紧凑的编辑数据集(50K样本),并在多模态DiT模块上采用LoRA微调进行参数高效适配。尽管数据集规模有限,该方法仍在编辑成功率和质量上取得显著提升。然而,某些任务(如风格变更和对象移除)仍存在挑战,降低了整体成功率。
这些发现可以认识到:单一LoRA结构的能力有限,不足以应对多样化的编辑任务。不同编辑任务需要不同的隐空间特征操作,而并行掌握这些多样化模式存在重大挑战。先前的LoRA调优通常针对特定任务,为不同目标训练独立权重,这凸显了统一LoRA模型在复杂编辑场景中的局限性。
LoRA混合专家
为解决这一限制,本文受到LLM最新进展的启发:混合专家(MoE)架构通过专用专家网络巧妙处理多样化输入模式。MoE范式为我们的任务提供两大优势:(1) 专用处理——使各专家专注于不同特征操作;(2) 动态计算——通过路由机制实现专家动态选择。这在不牺牲计算效率的前提下提升了模型容量。
利用这些优势,在DiT模块中提出混合LoRA-MoE结构:将并行LoRA专家集成到多模态(MM)注意力块的输出投影层,同时在其他层使用标准LoRA进行参数高效调优。可训练的路由分类器根据视觉标记内容和文本嵌入语义,动态选择最适合的特征变换专家。
本文设立 个专家,每个专家对应一个秩为 ,缩放因子为 的LoRA模块。对于每个输入标记,路由分类器 预测各专家的选择概率 。MoE-LoRA结构的输出计算如下:
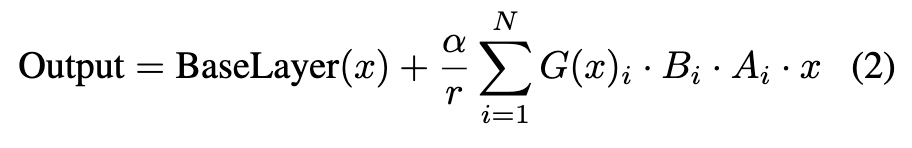
其中, 和 (满足 )表示第 个 LoRA 专家的学习权重, 为输入标记。路由分类器为每个专家分配选择概率 ,最终输出为专家输出的加权和。在我们的实现中,采用稀疏 MoE 设置,仅选择 top- 个专家参与计算:
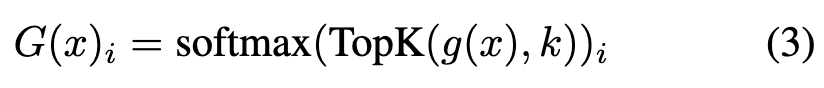
其中 函数仅保留向量中前 个条目的原始值,其余条目设为 。这确保了专家的高效使用,在保持多样化编辑任务灵活性的同时最小化计算开销。
早期过滤推理时间缩放
在推理过程中,初始噪声会显著影响编辑结果,某些输入能产生更符合人类偏好的输出(见下图10),这一现象也得到了近期研究的支持。这种变异性使研究推理时间缩放技术以提升编辑一致性和质量。在基于指令的编辑任务中,指令对齐的成功往往在少量推理步骤内就能显现(见下图6),这一特性与修正流DiT模型高度兼容。这些模型能高效遍历隐空间,仅需少量去噪步骤(有时仅需一步)即可生成高质量输出。因此,与需要更多步骤来实现细节和质量的生成任务不同,仅需少量步骤即可评估编辑成功率。

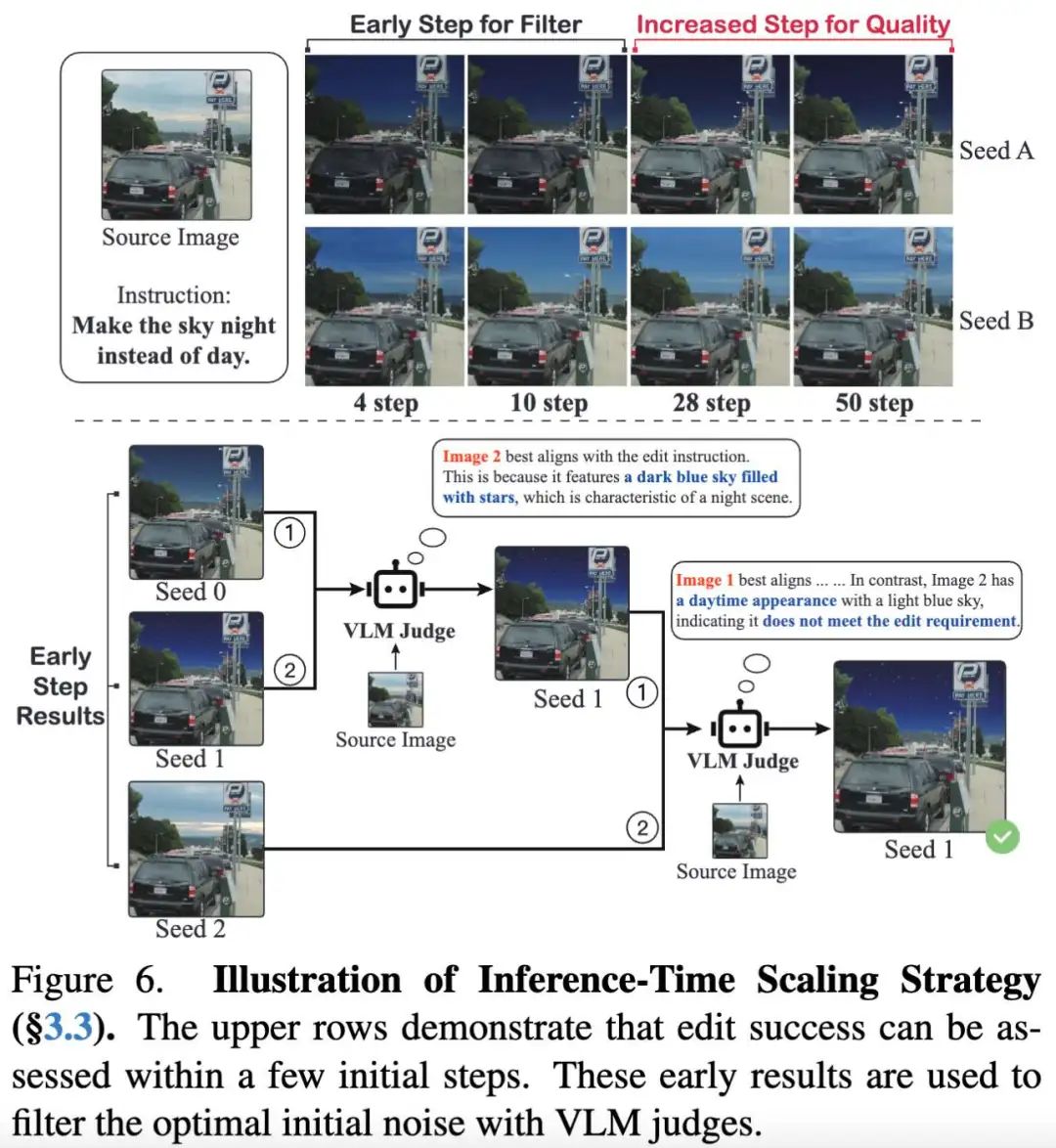
基于这一洞察,本文提出"早期过滤推理时间缩放"策略:首先生成 个初始噪声候选,对每个候选执行 步初步编辑( 为完整去噪步数);然后通过视觉大语言模型(VLM)评估这 个早期输出与指令的符合程度,采用类似冒泡排序的成对比较迭代篮选最优候选(见上图6);最终对优选种子执行完整的 步去噪生成最终图像。该方法能快速锁定优质噪声,同时通过VLM选择确保输出符合人类偏好。
实验
实现细节
本文采用领先的开源基于DiT的修复模型FLUX.1 Fill作为主干网络。为微调混合LoRA-MoE模块,从公开资源整理了一个精简编辑数据集:在初始采用MagicBrush数据集(含9K编辑样本)的基础上,发现其存在:1)编辑类型不平衡、2)缺乏风格类数据、3)领域多样性不足等问题。因此额外加入OmniEdit数据集约40K样本构成最终训练集。模型配置采用LoRA秩32、MoE模块含4个专家、TopK值为1。推理缩放策略使用Qwen-VL-72B作为输出评估器。更多数据集、参数和对比研究细节见补充材料。
评估设置
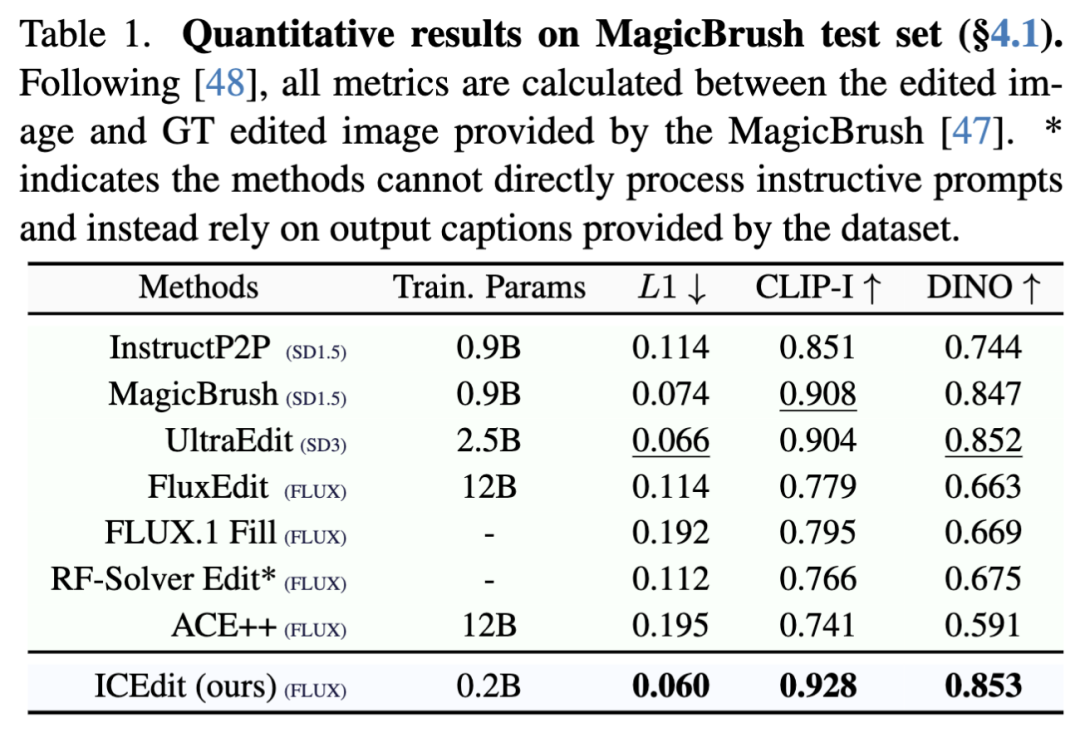
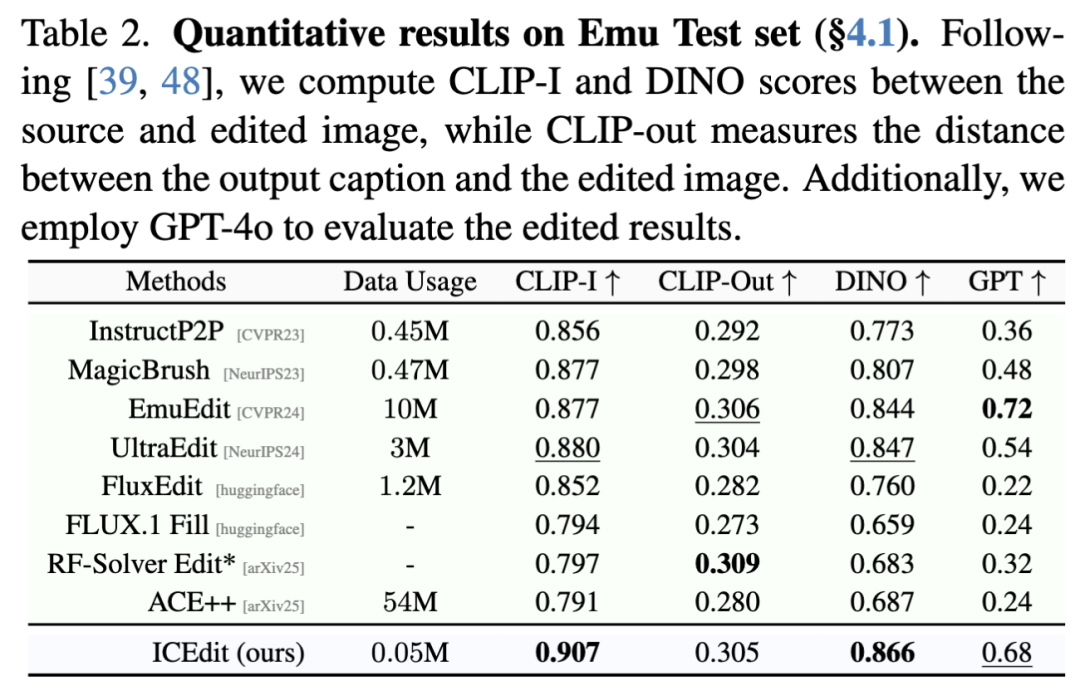
本文在Emu和MagicBrush测试集上进行了全面评估。对于含真实编辑结果(GT)的MagicBrush,严格遵循[47,48]计算CLIP、DINO和L1等指标来衡量与GT的偏差;而Emu测试集缺乏GT结果,遵照[39,48]进行基线评估,并参照[44]采用GPT-4o判断编辑成功率。为公平比较,所有模型均使用单一默认噪声输入评估,且不采用我们提出的早期过滤推理时间缩放技术。
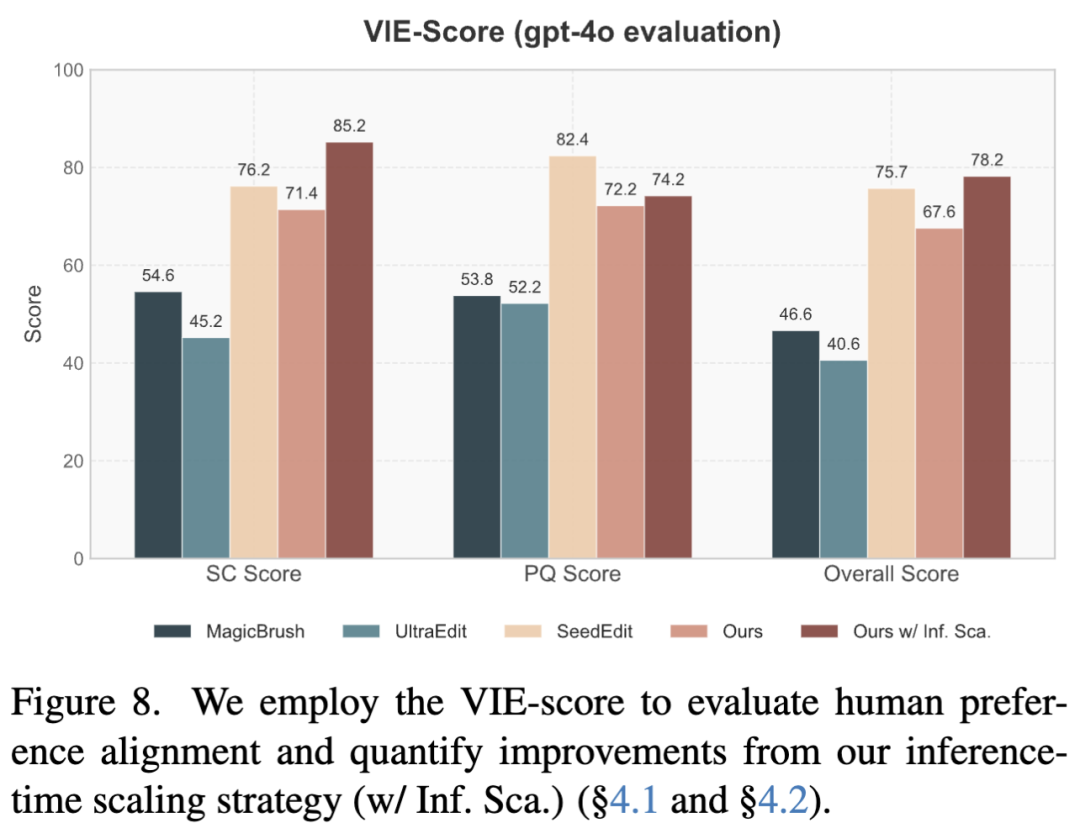
CLIP和DINO等传统指标常与人类偏好不一致。为更准确评估编辑性能和视觉质量,还计算了VIE-Score:该指标包含SC分数(评估指令遵循和未编辑区域保留)和PQ分数(独立于源图像和指令的视觉质量),总分计算为Overall 。使用该指标衡量推理时间缩放策略的增益,并与顶级闭源商业模型SeedEdit进行对比。
与前沿方法的比较
MagicBrush与Emu测试集结果
如下表1和表2所示,本文的模型在两类数据集上均达到SOTA级性能:在MagicBrush(表1)的输出与GT高度吻合,展现出强劲的编辑能力;在Emu(表2)则保持SOTA级文本对齐的同时更好地维持图像保真度。值得注意的是,基于GPT的评估分数显著优于开源模型,并逼近闭源的EmuEdit,而所需训练数据量却少得多。与同主干的DiT模型相比,本文的方法以更少的样本和参数实现了更优性能,凸显其高效性。定性结果见下图7。

VIE-Score评估
如下图8所示,本文的模型在编辑准确性和视觉质量上均显著优于开源SOTA方法。通过随机种子测试,本文的性能接近SeedEdit,而采用推理缩放策略后总分实现超越。虽然SeedEdit因商业化打磨输出获得更高PQ分数,但在未编辑区域的保真度上常有不足;相比之下,本文的方法在这些区域保持更优保真度(见图9)。

消融实验
模型结构
如前面表3所示,通过不同配置实验验证了方法的有效性。上下文编辑提示(IC提示)被证明具有关键作用:在免训练模型中显著优于直接编辑指令,而结合IC提示的微调进一步提升了编辑能力。LoRA-MoE设计以更少参数超越了标准LoRA微调,编辑质量和成功率提升13%(GPT评分),体现了其高效性。仅对输出投影层(“Only MoE”)进行适配会导致性能下降,证实了全模块微调的必要性。
推理时间缩放
如前图8和图10所示,本文推理时间缩放策略使编辑性能显著提升:SC分数提高19%,VIE总分提升16%。使用固定或随机种子时,模型能生成可行结果但并非最优。通过VLM筛选多种子早期输出并选择最佳候选,实现了更优质的编辑效果。
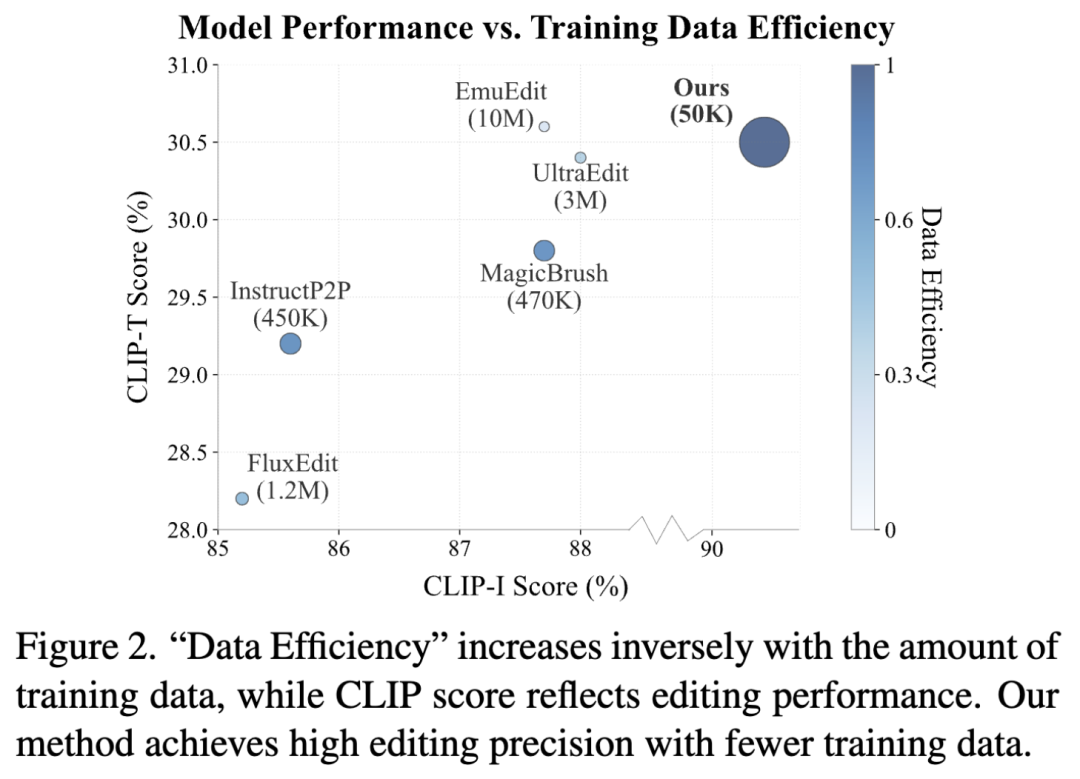
数据效率
下图2和前面表2显示,与免训练框架(FLUX.1 fill)相比,仅用0.05M训练样本就取得显著改进,远少于SOTA模型所需的10M样本,证明了框架的有效性和微调策略的高效性。
实际应用
和谐编辑
如下图1和图11所示,本文的方法能生成与原始图像无缝衔接的和谐编辑结果。模型在编辑过程中智能适应周边语境,产生更自然真实的效果——这是以往方法难以实现的能力。


多样化任务
如下图12所示,本文的方法可作为通用图到图框架,适用于手部精修、光影调整等实际任务。未来结合特定任务数据集微调,将进一步扩展其应用场景。

结论
In-Context Edit——一种基于DiT的新型指令编辑方法,通过极少量微调数据实现SOTA性能,在效率与精度间达到最佳平衡。首先探索了生成式DiT在免训练环境中的固有编辑潜力,进而提出混合LoRA-MoE微调策略提升稳定性和质量。此外,引入的推理时间缩放方法通过VLM从多种子中优选早期输出,显著改善编辑效果。大量实验证实了方法的有效性并展示了优越性能。相信这一高效精准的框架为指令式图像编辑提供了新思路,将在未来工作中持续优化。
参考文献
[1] Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer

(文:极市干货)