


极市导读
DeepSeek 团队生成理解统一架构 Janus 的后续版本,借助 Rectified Flow 做生成。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
本文介绍 DeepSeek 团队的 Janus 系列模型的后续版本 JanusFlow。Janus 系列是 DeepSeek 多模态团队的作品,是一种既能做图像理解,又可以做图像生成任务的 Transformer 模型。JanusFlow 将自回归的语言模型和 Rectified Flow 相结合。
JanusFlow 的主要发现表明,Rectified Flow 可以在 LLM 框架内直接训练,从而消除了对复杂架构修改的需要。为了进一步提高我们统一模型的性能,采用了 2 个关键策略:1) 解耦理解和生成编码器。2) 在统一训练期间对齐它们的表征。 JanusFlow 在各自的域中实现了与专业模型相当或更好的性能,同时在标准基准测试中显著优于现有的 Unified Model 方法。

下面是对本文的详细介绍。
本文目录
1 JanusFlow:使用 Rectified Flow 做生成的 Janus
(来自 DeepSeek)
1 JanusFlow 论文解读
1.1 JanusFlow 模型
1.2 Rectified Flow
1.3 JanusFlow 模型架构
1.4 JanusFlow 训练策略
1.5 JanusFlow 实验设置
1.6 JanusFlow 评测
1JanusFlow:使用 Rectified Flow 做生成的 Janus
论文名称:JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
论文地址:
https://arxiv.org/pdf/2411.07975
项目主页:
https://github.com/deepseek-ai/Janus
1.1 JanusFlow 模型
Janus 是使用一个统一的 Transformer 架构来统一多模态图像理解和多模态图像生成任务的模型。JanusFlow 是 Janus 的后续版本,一个统一多模态模型,将 Rectified Flow 与 LLM 架构无缝集成。
为了让设计尽量简单,JanusFlow 只需一个轻量化的 Encoder 和 Decoder 来 adapt LLM 完成 Rectified Flow 的操作。为了优化 JanusFlow 的性能,作者实现了 2 个关键的策略:1) 维护单独的视觉编码器和解码器进行理解和生成任务,防止任务干扰,从而提高理解能力。2) 在训练期间对其生成和理解模块的中间表征,增强生成过程中的语义一致性。
与现有的 Unified Model 相比,JanusFlow 在多模态理解和文本到图像生成方面表现出最先进的性能,甚至优于几种专门的方法。具体来说,在文生图 Benchmark 上,MJHQ FID-30k、GenEval 和 DPG-Bench,JanusFlow 的得分分别为 9.51、0.63 和 80.09%,超过了现有文生图模型,包括 SDv1.5 和 SDXL。在多模态理解 Benchmark 中,JanusFlow 在 MMBench、SeedBench 和 GQA 上分别获得 74.9、70.5 和 60.3 的分数,超过 LLAVA-v1.5 和 Qwen-VL-Chat 等专门用于理解的模型。值得注意的是,这些结果来自只有 1.3B 参数的 LLM。
1.2 Rectified Flow
对于由从未知数据分布 中提取的连续恶数据点 组成的数据集 , Rectified Flow 通过学习定义在时间 上的常微分方程(ODE)来建模数据分布:
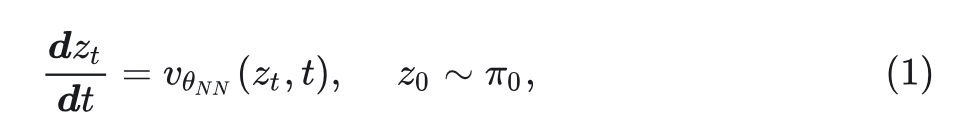
其中, 表示速度神经网络的参数, 是一个简单的分布,通常是标准的高斯噪声 。通过最小化 neural velocity 与连接 和 之间随机点的 linear path 方向之间的欧氏距离来训练网络。
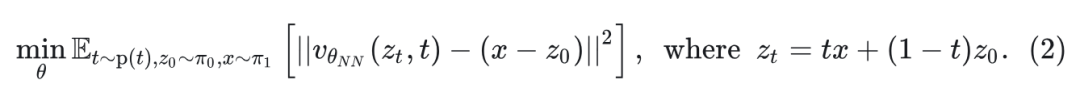
这里, 是时间 上的分布。当网络具有足够的容量并且目标被完美地最小化时,最优速度场 将基本分布 映射到真实数据分布 。
更准确地说,分布 ,遵循 。
尽管 Rectified Flow 在概念上很简单,但在各种生成建模任务中表现出了优越的性能,包括文生图[1]等等。
1.3 JanusFlow 模型架构
JanusFlow 提出了一个统一框架,旨在解决视觉理解和图像生成任务。
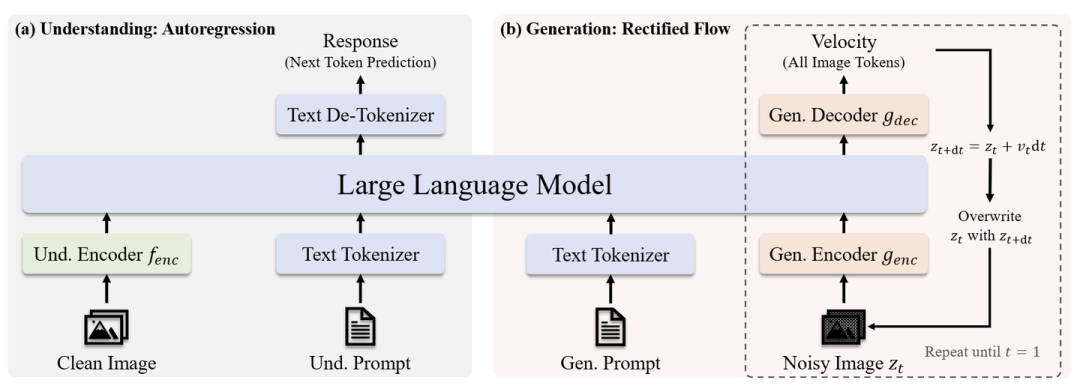
多模态理解
在多模态理解任务中,LLM 处理由交错文本和图像数据组成的输入序列。文本被标记为离散 token,每个 token 都被转换为维度 的嵌入。对于图像,图像编码器 将每个图像 编码成形状为 的特征。这个特征图被 flattened 并通过线性变换层投影到一系列形状为 的 Embedding 中。 和 由图像编码器决定。文本和图像 Embedding 被连接起来形成 LLM 的输入序列,然后根据 Embedding 的输入序列 Autoregressive 地预测下一个 token。在图像之前添加了特殊标记|BOI|和图像后的 |EOI|,以帮助模型定位序列中的 Image Embedding。
图像生成
对于图像生成,LLM 以文本序列为 condition,并使用 Rectified Flow 生成相应的图像。为了提高计算效率,使用预训练的 SDXL-VAE 在 Latent Space 中生成。
生成过程首先在潜在空间中对形状为 的高斯噪声 进行采样,然后由生成编码器 处理成一系列嵌入 。这个序列与一个 time Embedding 连接,该 Embedding 表示当前时间步 (开始时刻 ),从而产生长度为 的序列。
与之前使用各种 Attention Masking 策略不同,作者发现 Causal Attention 就足够了。LLM的输出对应于 通过生成解码器 转换回 latent 空间,产生形状为 的 velocity 向量。该状态由标准欧拉求解器更新:

其中, dt 是用户定义的步长。作者在输入上用 替换 ,并迭代该过程,直到我们得到 ,然后由 VAE 解码器将其解码为最终图像。为了提高生成质量,在计算速度时使用无分类器指导(CFG):

其中, 表示 no condition 的 velocity,并且 控制 CFG 的大小。根据经验,增加 会产生更高的语义对齐。与多模态理解类似,使用特殊标记 指示序列中的图像生成的开始。
JanusFlow 采用解耦的编码器设计。JanusFlow 使用预训练的 SigLIP-Large-Patch/16 模型作为 来提取语义连续特征以进行多模态理解,同时使用从头开始初始化的单独 ConvNeXt Block 作为 和 ,选择其有效性。解耦编码器设计显著提高了 Unified Model 的性能。JanusFlow 的完整架构如图 3 所示。
1.4 JanusFlow 训练策略
JanusFlow 的训练分为 3 个阶段,如图 4 所示。
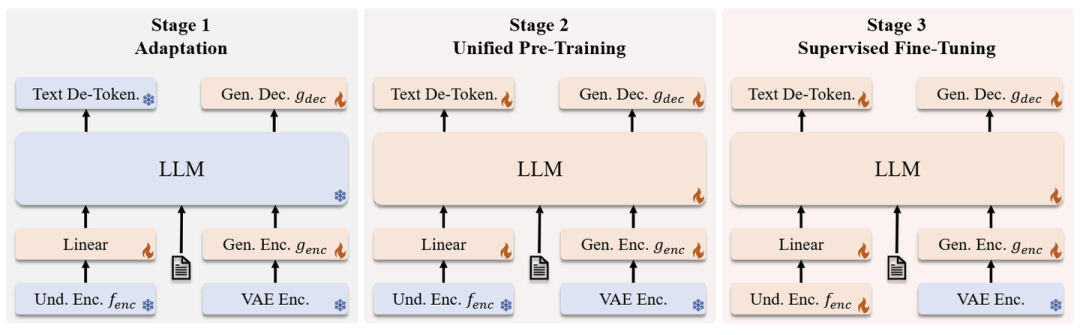
第 1 阶段:训练 Linear 层,生成编码器和生成解码器。
这一阶段的主要目标是训练 Linear 层 (之后的东西,可以理解为 Adaptor),Generation Encoder,Generation Decoder。这一阶段旨在使这些新的模块与 Pre-trained 的 LLM 和 SigLIP Encoder 有效适配。
第 2 阶段:联合预训练,除了理解编码器和 VAE Encoder 之外的所有组件都更新参数。
这个阶段训练整个模型,除了理解编码器和 VAE Encoder。训练结合了 3 种数据类型:多模态理解、图像生成和纯文本数据。作者最初分配更高比例的多模态理解数据来建立模型的理解能力。随后,增加了图像生成数据的比例,以适应基于扩散的模型的收敛要求。
第 3 阶段:有监督微调,进一步解锁理解编码器的参数。
这个阶段作者使用指令调整数据微调预训练模型,其中包括对话、特定于任务的对话和高质量的文生图示例。在这个阶段,作者还解冻了 SigLIP Encoder 参数。这种微调过程使模型能够有效地响应用户指令以进行多模态理解和图像生成任务。
1.5 JanusFlow 训练目标
训练 JanusFlow 涉及两种类型的数据、多模态理解数据和图像生成数据。
这两种类型的数据都包含两部分:"Condition"和"Response"。"Condition"是指任务的提示 (例如,多模态理解任务中的 image,图像生成任务中的 text),而"Response"是指两个任务的响应。数据可以格式化为 ,其中上标 con 表示"Condition",而 res 表示"Response"。将整个序列 的长度表示为 ,将 的长度表示为 ,将 的长度表示为 。作者使用 来表示 JanusFlow 中所有可训练参数的集合,包括 LLM, , 和 Linear 层。
Autoregressive 训练目标
对于多模态理解任务, 仅包含文本标记。JanusFlow 使用最大似然原理进行训练,
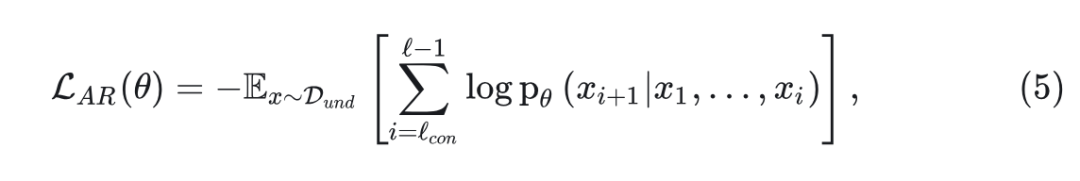
其中,期望在多模态理解数据集 中接管所有 对,计算损失仅在 中的 token 上。
Rectified Flow 训练目标
对于图像生成任务, 由文本 token 组成, 是对应的图像。JanusFlow 使用 Rectified Flow 进行训练:
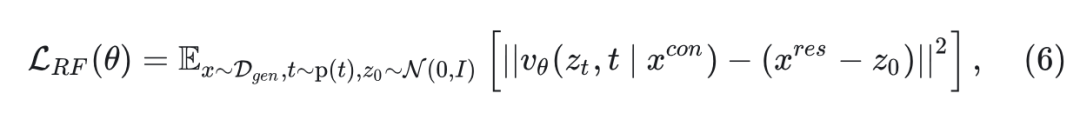
其中, 。在 Stable Diffusion 3 之后,将时间分布 设置为 Logit 正态分布。为了实现 CFG 推理,在训练期间随机丢弃 10\%的文本提示。
表征对齐正则化
对齐 Diffusion Transformer 和 Semantic Vision Encoder 之间的中间表征可以增强扩散模型的泛化能力。Janus 的解耦视觉编码器设计使这种对齐的有效实现成为一个正则化项。具体地说,对于生成任务,作者将理解编码器 的特征与 LLM 的中间特征对齐:

其中, 代表 LLM 的中间表征,给定输入 。 是一个小的可学习 MLP,把 映射到 维度。函数 计算嵌入之间的元素余弦相似度的平均值。
在计算 loss 之前,把 reshape 为 。作者确保 的梯度不会通过 Understanding Encoder 反向传播。这种对齐损失有助于 LLM 的内部特征空间(给定噪声输入 )与 Understanding Encoder 的语义特征空间对齐,从而在推理过程中从新的随机噪声和文本条件生成图像时提高生成质量。
所有 3 个目标都用于所有训练阶段。多模态理解任务使用 ,而图像生成任务使用损失 .
1.5 JanusFlow 实验设置
JanusFlow 建立在DeepSeek-LLM (1.3B) 的增强版本。LLM 由 24 个 Transformer Block 组成,支持 4,096 的序列长度。在 JanusFlow 中,理解和生成图像分辨率都为 384。
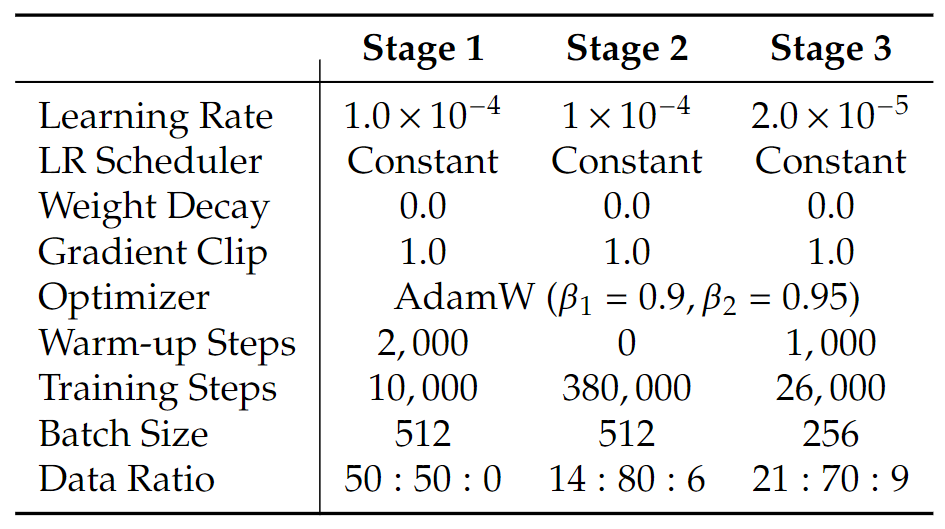
对于多模态理解,作者利用 SigLIP-Large-Patch/16 作为 。对于图像生成,作者利用预训练的 SDXL-VAE 作为其 latent space。生成编码器 包括 pathify 层,然后 2 个 ConvNeXt Block 和 Linear 层。生成解码器 结合了 2 个 ConvNeXt Block,一个 pixel- shuffle 层上采样和 Linear 层。SigLIP 编码器包含约 300M 参数。 和 是轻量级模块,总共包含约 70M 参数。图5详细说明了每个训练阶段的超参数。在 Representation Alignment 中,使用第 6 块之后的 LLM 特征作为 ,将 3 层 MLP 用作 。使用 0.99的指数移动平均(EMA)来确保训练稳定性。
JanusFlow 以不同的方式处理理解和生成数据。对于理解任务,将长边调整为目标大小并将图像填充到正方形来维护所有图像信息。对于生成任务,将短边的大小调整为目标大小,并应用随机裁剪来避免填充伪影。
在训练期间,多个序列被打包以形成长度为 4096 的单个序列以提高训练效率。JanusFlow 的实现基于使用PyTorch 的 HAI-LLM 平台。训练是在 NVIDIA A100 GPU 上进行的,每个模型需要约 1600 A100 GPU 天。
训练数据设置
第 1 阶段和第 2 阶段的数据
JanusFlow 的前 2 个阶段使用 3 种类型的数据:多模态理解数据、图像生成数据和纯文本数据。
-
多模态理解数据。 这种类型的数据包含多个子类别:(a) Image caption 数据:”Generate the caption of this picture. “。(b) 图表和表格。(c) 任务数据。ShareGPT4V 数据用于促进预训练过程中的基本问答能力:” “。(d) 文本图像交织的数据。 -
图像生成数据。所有数据点都格式化为 “ “。 -
纯文本数据。直接使用 DeepSeek-LLM 的文本语料库。
第 3 阶段的数据。 SFT 阶段还使用 3 种类型的数据:
-
多模态指令数据。 -
图像生成数据:“User: \n\n Assistant:”。 -
纯文本数据。
1.6 JanusFlow 评测
视觉生成
作者报告了 GenEval、DPG-Bench 和 MJHQ FID-30k 的性能。图 6 比较了 GenEval,包括所有子任务的分数和总分。JanusFlow 的总体得分为 0.63,超过了之前的统一框架和几个生成特定模型,包括 SDXL 和 DALL-E 2。
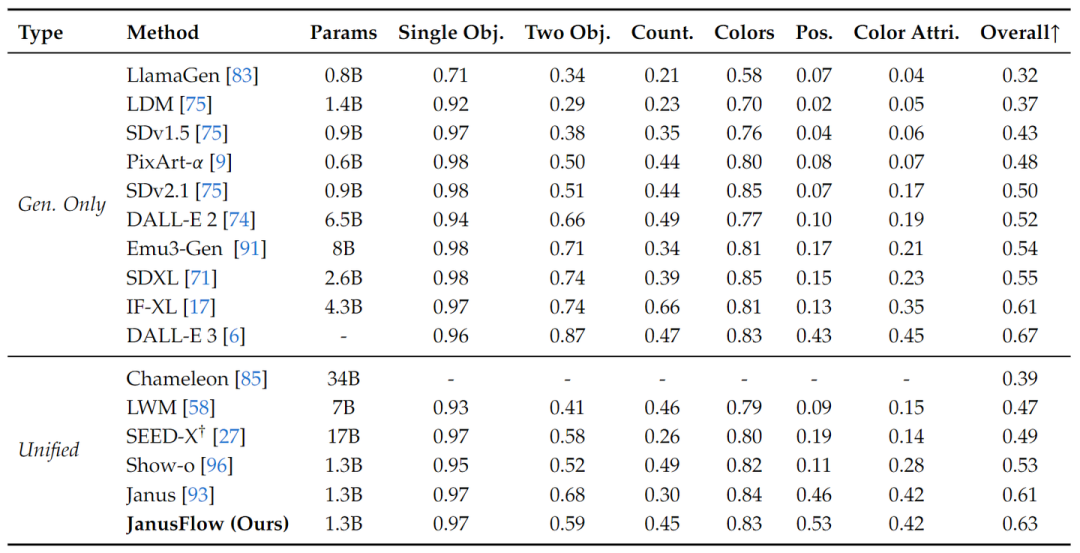
图 7 比较了 DPG-Bench 的结果。除了 JanusFlow 外,其他模型都是专门做生成的。
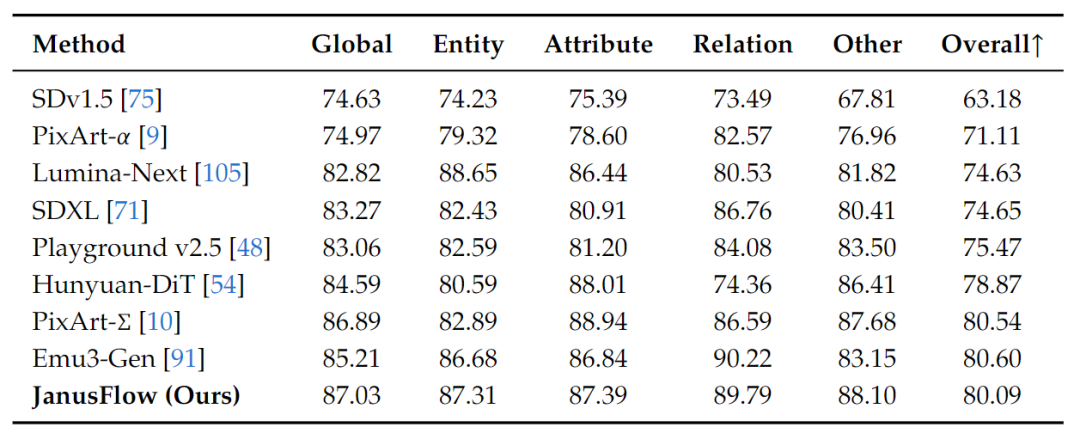
GenEval 和 DPGBench 上的结果展示了 JanusFlow 的指令跟随能力。
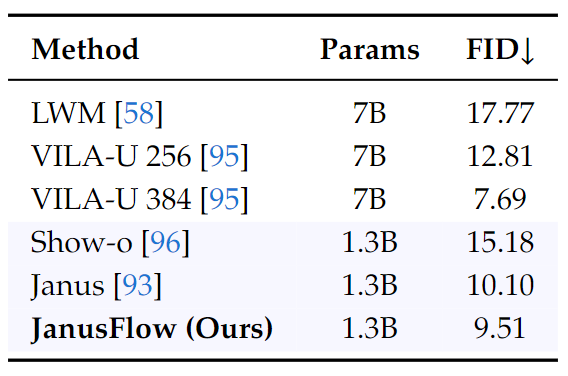
图 8 比较了 MJHQ FID-30k 的结果。采样的图片是使用 CFG factor w=2 ,sampling steps 为 30 生成的。结果表明,Rectified Flow 能够在 Janus 等自回归模型上提高生成图像的质量。
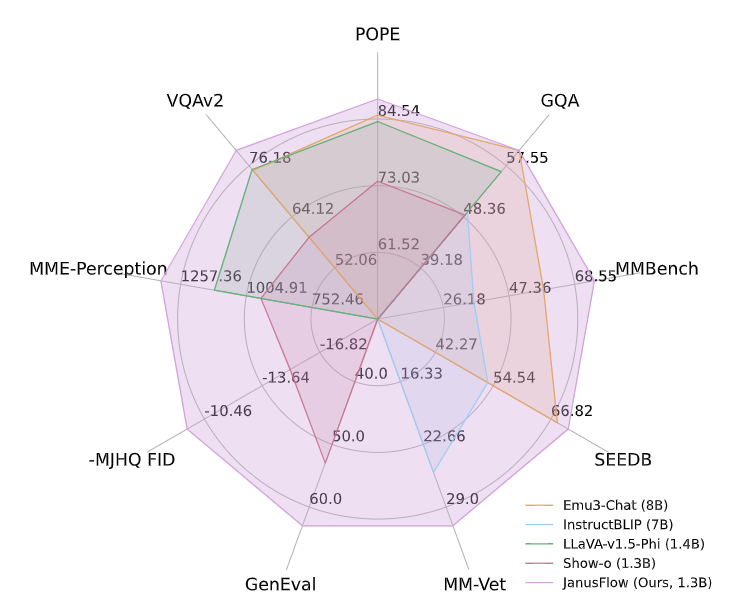
多模态理解
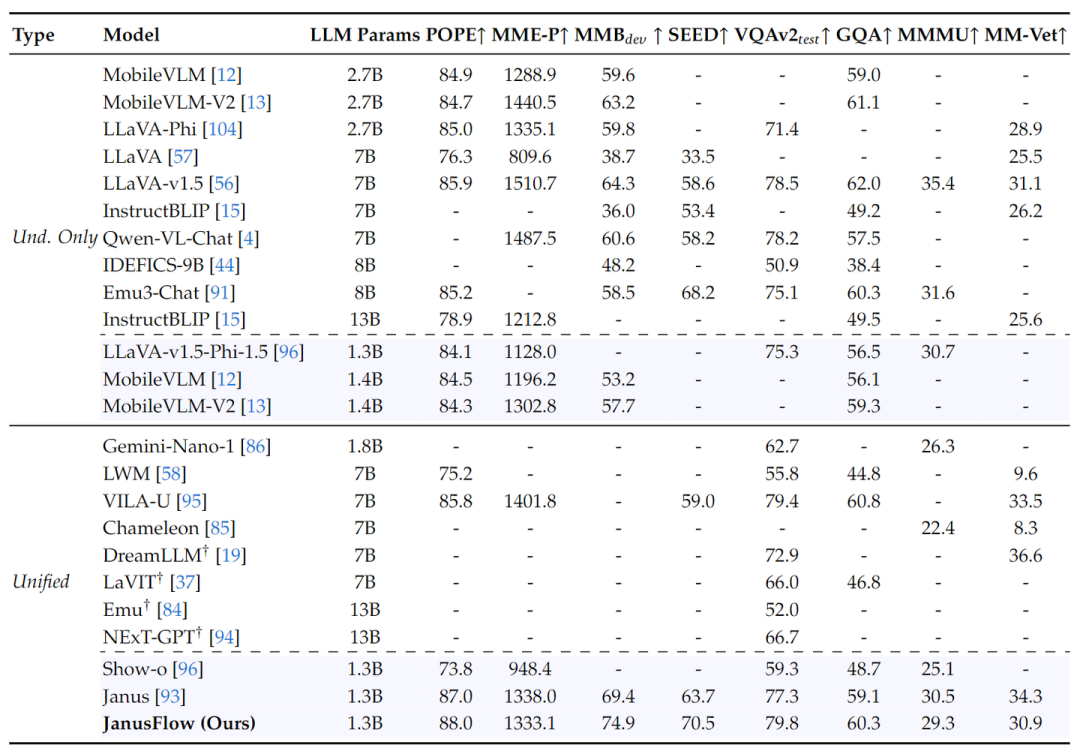
图 9 展示了 JanusFlow 与其他方法的比较,包括专门做理解的模型和 Unified Model。JanusFlow 在具有相似参数量的所有模型中达到了最佳性能,甚至超过了多个专门做理解的方法。结果表明,JanusFlow 协调了自回归 LLM 和 Rectified Flow,在理解和生成方面都取得了令人满意的性能。
参考
-
^Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
(文:极市干货)