
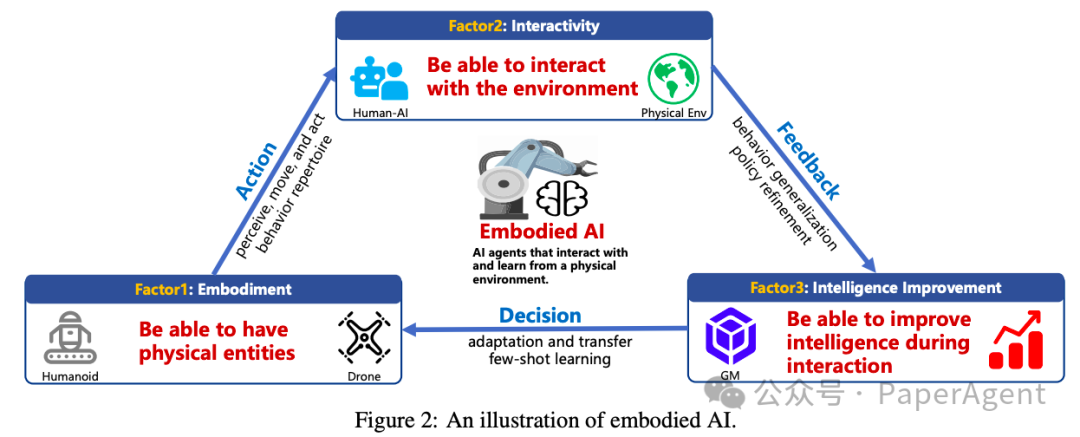

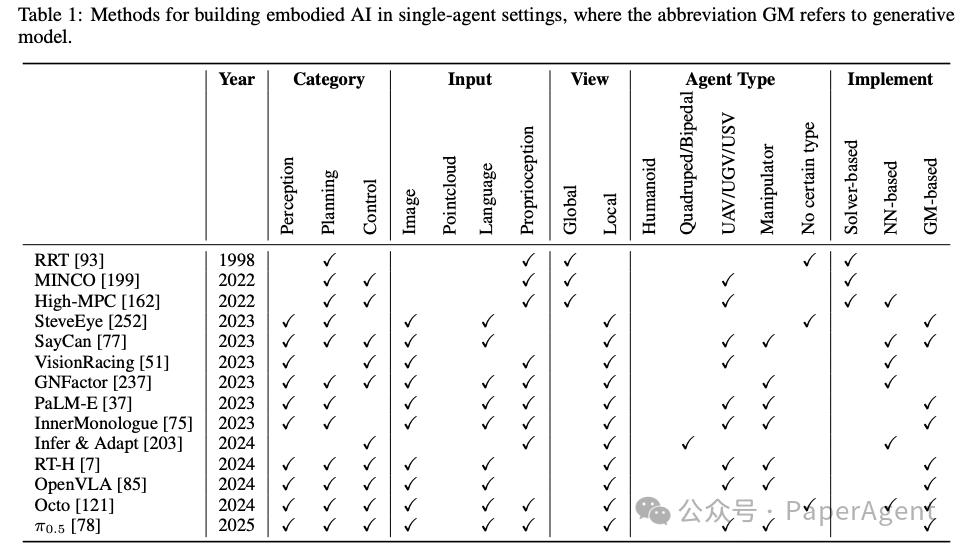
详细介绍了单智能体具身人工智能(Embodied AI)的研究现状、方法和进展:
1.1 经典控制与规划方法
单智能体具身AI在经典控制和规划方面主要依赖于以下几种方法:
-
基于约束的方法:通过将任务目标和环境条件编码为逻辑约束,将规划问题转化为符号表示,并使用约束求解技术(如符号搜索)来找到可行解。这种方法更注重解的可行性而非最优性,且在处理高维感知输入时复杂度较高。
-
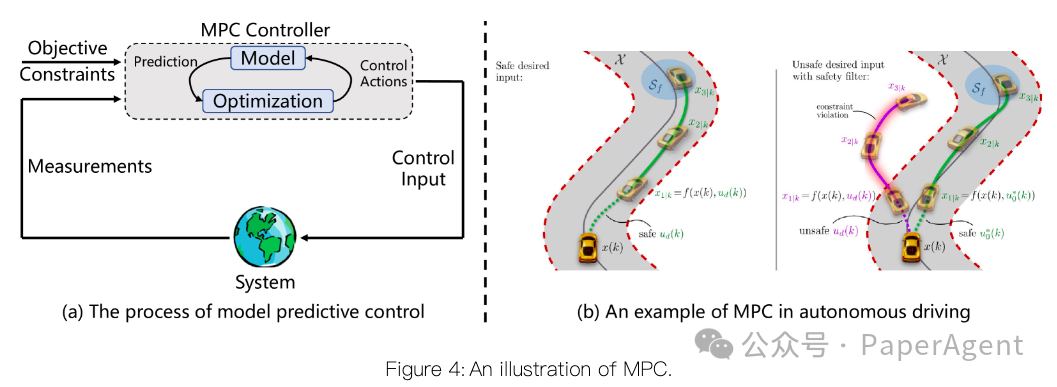
基于采样的方法:通过随机采样技术(如快速探索随机树RRT)逐步构建树或图结构,以探索可行的运动轨迹。这种方法适用于高维空间,能够有效处理复杂的环境。
-
基于优化的方法:将任务目标和性能指标建模为优化目标函数,同时将可行性条件表示为约束条件,利用优化技术在约束解空间中搜索最优解。例如,多项式轨迹规划、模型预测控制(MPC)和最优控制(OC)等方法在需要时间最优操作的场景中表现出色。
1.2 基于学习的方法
随着环境动态性和任务复杂性的增加,基于学习的方法逐渐成为主流:

-
端到端强化学习(End-to-end RL):通过直接从环境中学习策略,将感知信息映射到行动决策。这种方法能够直接优化策略,但面临样本效率低和训练时间长的问题。
-
层次化学习(Hierarchical Learning):将复杂任务分解为更简单的子任务,通过层次化的策略提高学习效率和可扩展性。例如,使用强化学习进行高级规划,结合模型预测控制(MPC)等经典控制方法执行低级动作。
-
模仿学习(Imitation Learning, IL):通过模仿专家行为来学习任务解决能力,避免了手动设计奖励函数的复杂性。常见的方法包括行为克隆(BC)、逆强化学习(IRL)和生成对抗模仿学习(GAIL)。这些方法在样本效率和泛化能力上各有优势。

1.3 基于生成模型的方法
生成模型通过捕捉数据的底层分布来生成新的样本,为具身AI提供了更强大的表示能力和灵活性:

-
端到端控制(End-to-end Control):使用生成模型(如大型视觉-语言模型VLM)直接作为决策控制器,将先验知识和预训练能力融入具身系统。例如,通过格式化输入并直接从预训练模型中推断行动。
-
任务规划(Task Planning):利用生成模型的推理能力,将任务分解为可操作的步骤序列。例如,给定一个高级任务(如“倒一杯水并放在桌子上”),生成模型可以将其分解为一系列具体动作。
-
感知(Perception):生成模型(如Transformer架构)可以用于融合多模态感知数据,提供更有效的环境表示。
-
奖励设计(Reward Design):利用生成模型生成奖励信号或奖励函数,以简化复杂环境中的奖励设计过程。
-
数据高效学习(Data-efficient Learning):通过生成模型生成数据,提高样本效率,减少与物理环境的交互成本。


深入探讨了多智能体具身人工智能(Embodied AI)的研究进展、面临的挑战以及未来的发展方向:
2.1 多智能体控制与规划
多智能体系统(MAS)中的控制和规划方法是实现高精度、实时决策的基础:

-
集中式控制:早期方法将多智能体系统建模为单个智能体,进行集中控制和规划。然而,这种方法在大规模系统中面临可扩展性挑战。
-
分布式控制:为了解决集中式控制的可扩展性问题,分布式控制方法被提出,每个智能体独立进行控制。但这种方法在解决智能体间的冲突方面存在困难。
-
分组多智能体控制框架(EMAPF):通过动态聚类智能体,将智能体分为多个小组,每个小组内部进行集中控制,而小组之间保持独立控制。这种方法在大规模空中机器人团队中表现出色。
2.2 多智能体学习
多智能体学习需要解决异步决策、异构智能体和开放环境中的学习挑战:
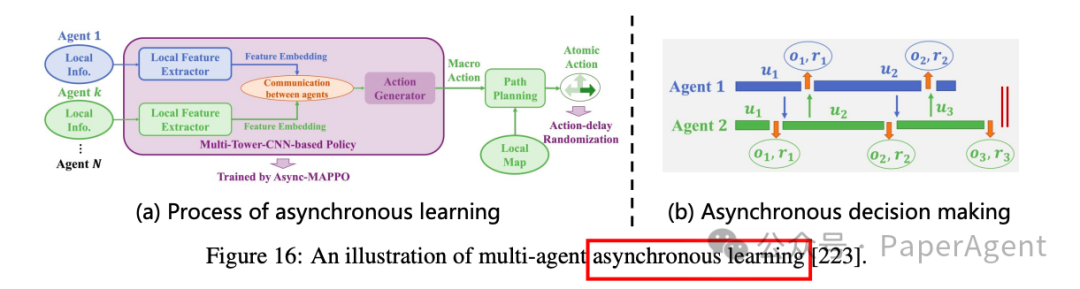
-
异步协作:由于通信延迟和硬件异构性,智能体之间的交互和反馈往往是异步的。文章介绍了ACE算法,通过引入宏动作(macro-actions)来解决这一问题。宏动作作为整个MAS的集中目标,智能体基于此目标进行多次异步决策。
-
异构协作:智能体在感知能力、动作空间、任务目标等方面存在差异。HetGPPO和COMAT等方法通过为不同类型的智能体设计独立的观察和策略网络,并通过图神经网络进行信息交换,从而有效处理异构性。
-
开放环境中的自适应学习:开放环境中的任务目标、环境因素和协作模式是动态变化的。研究人员提出了鲁棒训练和持续协调等方法,以应对这些挑战。


2.3 基于生成模型的多智能体交互
生成模型在多智能体具身AI中具有重要作用,能够引入先验知识、促进智能体间的通信和观察补全,并提高数据效率:
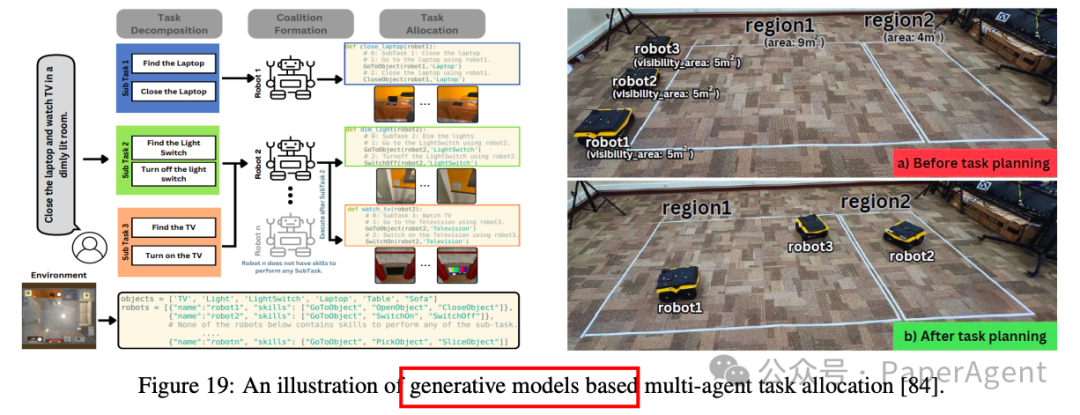
-
多智能体任务分配:利用预训练的生成模型(如大型语言模型)进行任务分解和分配,显著减少了每个智能体的探索空间。例如,SMART-LLM通过分解任务并根据智能体能力进行分组,实现高效的任务分配。
-
分布式决策:生成模型可以用于分布式决策,每个智能体独立进行决策和策略评估。通过引入中心化的生成模型来评估分布式生成模型的决策,进一步提高了决策能力。
-
人机协作:生成模型能够通过语言理解和生成能力,显著改善人机交互和协作。例如,通过主动查询人类以获取缺失信息或推断人类意图,智能体可以更有效地与人类协作。
-
数据高效学习:在多智能体设置中,样本效率问题更加突出。通过使用生成模型进行数据增强,可以提高数据效率,支持更有效的学习。


https://arxiv.org/pdf/2505.05108Multi-agent Embodied AI: Advances and Future Directions
(文:PaperAgent)