


背景
多模态大模型在视觉问答、图像描述等传统的图文理解任务上取得较好效果,随着OpenAI-o1、Deepseek-R1的推出,业界近期更加关心多模态大模型的推理能力。本文介绍和整理近期多模态大模型推理相关研究工作。
针对多模态大模型推理的研究大致经历了两个阶段,在o1推出后,研究主要聚焦于设计基于推理数据和搜索的方法。这类方法尝试通过prompting或搜索的方式,构建符合一定规律的CoT推理数据,并使用这种数据对模型进行微调。在r1推出后,更多的研究聚焦于基于reward function的强化学习方法,倾向于不对模型的推理过程施加强限制,仅针对推理结果指导模型优化。以下将分别介绍和总结的代表性工作。
推理数据与搜索方法
Llava-cot: Let vision language models reason step-by-step[1]

针对推理类图文问题,Llava-CoT将问题解决过程拆解成固定的多个推理阶段,分别是summary、caption、reasoning和conclusion阶段。如上图所示,summary阶段主要回顾问题并思考针对问题模型应该采取的操作;caption阶段对图片进行感知,产生描述性文本,从图片中获取解决问题的信息;reasoning阶段将问题拆解成step-by-steps形式进行具体的推理操作,最终conclusion阶段总结最终的推理结果。Llava-CoT在给定特定instruction的情况下,利用更强的模型GPT-4o生成了100K的SFT数据Llava-CoT-100K用于对模型进行微调。
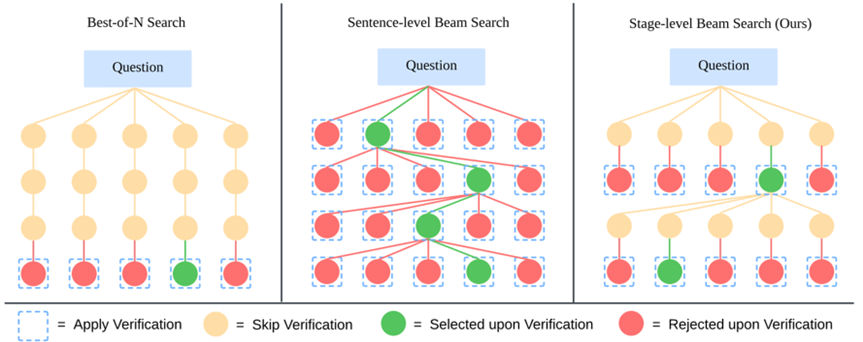
除了进行SFT外,Llava-CoT在推理阶段结合SFT结构式推理特点设计了Stage-level beam search初步探索了test-time-scaling方法。由于上述的SFT保证模型一定能够根据上述定义的四个阶段(stage)产生文本,该推理方法在每个stage保留多个不同推理路径,并由模型判断最佳路径并保留,然后重复这个过程,直到4个推理阶段全部完成。这种方法可以让模型有机会sample出比一致选top1更加的推理路径。
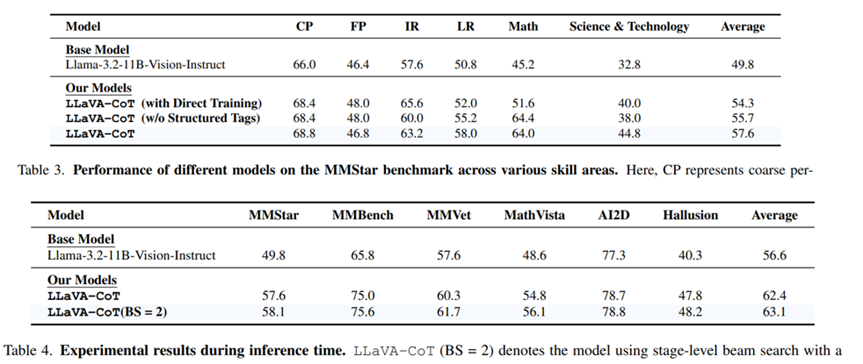
实验表明Llava-CoT提出的推理sft在MMStar等多个benchmark上有明显提升,并且在每个stage加入各自的特殊标记(比如<SUMMARY>等)有一定效果。笔者认为这种token应该能够提示模型专注于当前阶段的生成。同时实验也验证了stage-level beamsearch的有效性。
Enhancing the reasoning ability of multimodal large language models via mixed preference optimization[2]
这项工作同样聚焦于构建推理数据。与Llava-CoT直接构造SFT数据不同,这篇工作构建了pair-wise CoT数据进行偏好优化(preference optimization),并提出MPO对DPO进行改进。考虑到多模态数据集中有的任务有标准答案(比如视觉问题回答等),有的不易评测(比如描述生成等),该工作采用不同的方式为这两类数据生成pair-wise cot样例:
-
对于有标准答案的数据样例,使用模型产生多个不同推理路径。若最终结果是正确的,则该路径为正样本,否则为负样本 -
• 对于不易评测、无标准答案的数据样例,该工作将完整生成的数据是为正样本,并将正样本截断,在不给图的情况下让模型续写,将续写后的拼接结果视为负样本。
这么做的前提假设是对于多模态任务在不给图的情况下无法进行,因此续写结果是比正常生成要差的,符合pair-wise的设计。
在训练方面,该工作提出Mixed preference optmization(MPO)。该方法在DPO基础上加了两个额外的loss,一个是一般的SFT loss,另一个是Quality loss。这个Loss要求模型能够显式区分正样本cot与负样本cot。

实验表明,MPO算法表现优于单纯的SFT。另外,可以发现直接使用cot prompting进行推理在Internvl2-8B上会造成性能下降,而进行了SFT与MPO微调的模型能够有提升,这验证了标注数据微调方法的效果。
Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search[3]
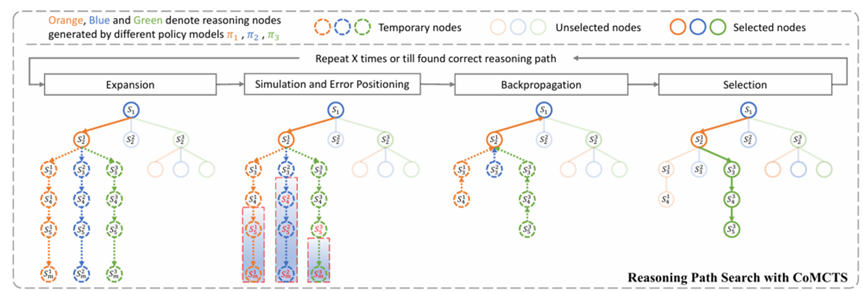
这项工作聚焦于推理方法,提出基于蒙特卡洛树搜索CoMCTS的方法。如下图所示,该方法分四个阶段进行推理:
-
• Expansion:扩展当前阶段,使用k个MLLM推理特定的步数

-
• Simulation and Error Positioning: 使用K个mllm计算每个节点的score,舍去得分较低的节点
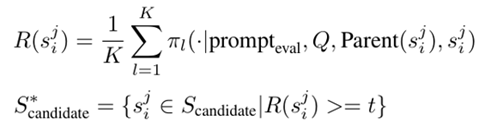
-
• Backpropagation:从下到上维护每个推理节点的V值和N值,其中V(Value)指节点价值,N指遍历次数。更新过程如下所示
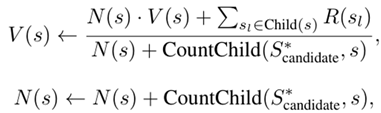
-
• Selection:根据上述的V和N值计算UCB Score,该score平衡搜索深度和广度,选择下一个遍历节点。
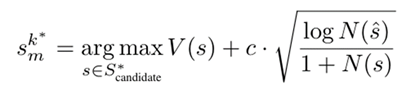
在找到下一个遍历节点后,就可以重复第一个Expansion stage,从而进行完整的树搜索,直到产生推理结果。这种树搜索方式允许构建包含反思的cot推理链,如下图所示,在推理的某一步,可以选择当前阶段的某个兄弟节点进行额外的一部推理,由于这个节点是错误的,可以认为加入一个反思的prompt,然后接上正确的推理节点,从而构造反思cot数据。

该工作通过上述方法构建了推理数据集用于SFT模型,实验验证了上述方法构建的反思数据能够提升CoT SFT的性能。

上述的三篇工作主要思路是通过调用更强的大模型、self-evaluation和tree search等方式构造符合一定模式的CoT数据,对模型进行微调,并在相关benchmark上评测。虽然取得了一定的效果,但是这类方法泛化性比较一般。一方面,用于SFT的CoT数据的推理模式通用性可能一般,比如对于多图交错场景,或比较简单的问题,Llava-CoT固定的四个阶段就不适用。另一方面,sft要求模型强行拟合CoT的模式,可能会加重模型幻觉。
基于强化学习的方法
在deepseek-r1出现后,更多的工作基于GRPO的强化学习方法激发模型的推理能力。
R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization[4]
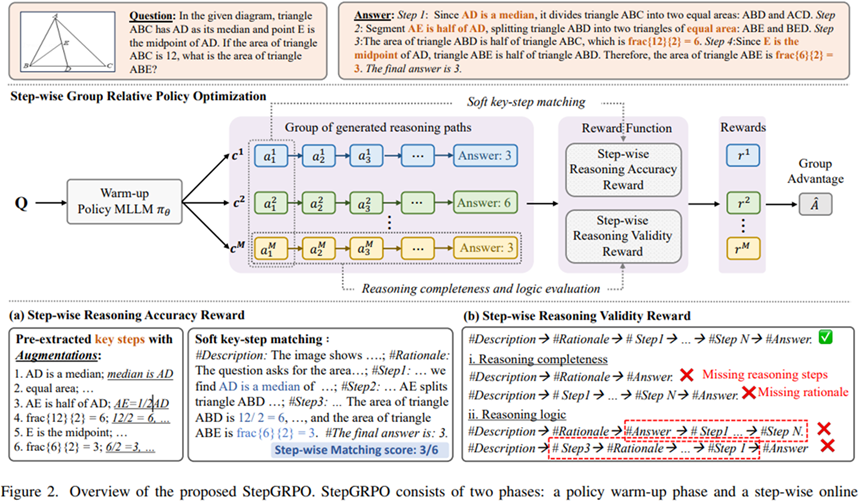
R1-VL提出StepGRPO方法,相比一般的GRPO完全不对模型sample的中间CoT过程进行限制,该方法要求CoT中包含特定的推理步骤,并约束推理过程的完整性和连贯性,StepGRPO主要包含下面两个reward:
StepRAR:要求包含key steps
-
• 首先使用GPT-4从cot数据中抽取key step words -
• 产生key step的多个等价描述 -
• 与模型生成的cot进行软匹配,匹配的key step words及其等价描述越多,得分越高
StepRVR:要求推理过程的完整性和连贯性
-
• 要求推理过程包含描述、steps和最终答案三个部分 -
• 要求上述三个部分出现的顺序是描述->steps->最终答案
实验验证StepGRPO相比SFT和GRPO效果更好。
Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning[5]
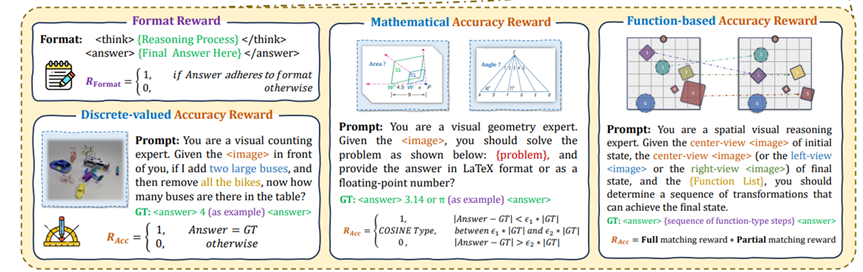
这项工作根据不同任务metric的特点设计更加soft的reward。如上图所示,主要考虑三个类别的reward:
-
• Discreate-valued Accuracy Reward:针对Counting等任务,只有模型输出结果完全一致的时候才视为正确,得到满分,否则为0分
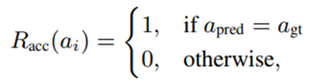
-
• Mathematical Accuracy Reward:针对结果是实数的数学类问题,允许模型产生一些数值计算误差,在允许的误差范围内可以得到一定的得分。这种误差容忍度采用cosine reward函数实现:
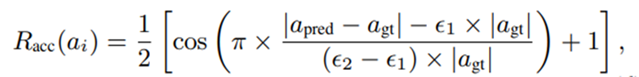
-
• Fuction-based Accuracy Reward:对于结果是function列表的任务,允许模型在正确选择<方法名,作用对象,值>三者中的其中一个或两个的情况下得到部分得分:
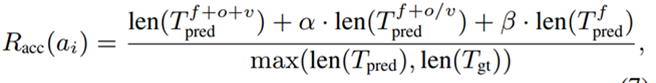
OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement[6]
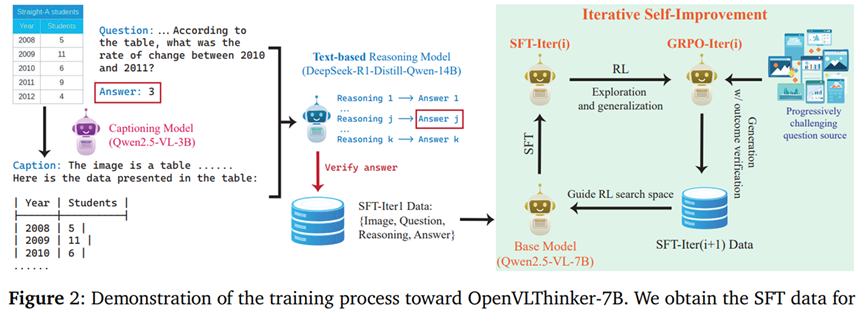
OpenVLThinker这项工作主要贡献是跑通了SFT与RL多轮迭代提升的框架。该过程比较类似DeepSeek-R1-Zero到DeepSeek-R1的过程。通过caption+文本模型的方式构建SFT推理数据对基础模型进行微调。基于这个微调模型进行GRPO的强化学习,并使用该rl模型生成新一轮的SFT数据。随后新一轮数据用于微调原始的Base Model得到第二代的SFT模型,重复上述过程。
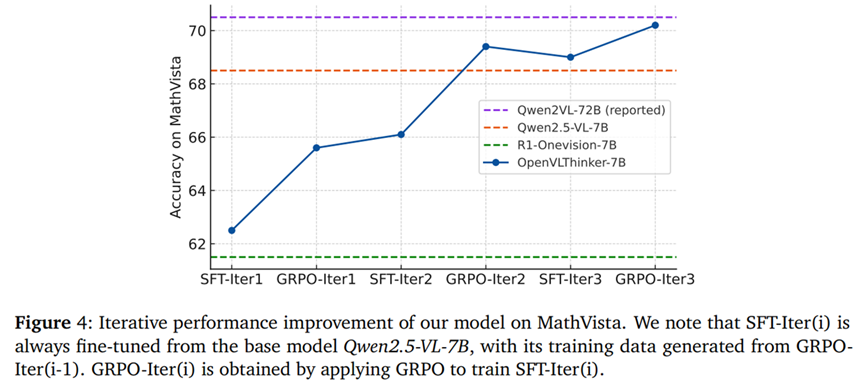
实验表明数据迭代策略在进行到第3轮时依旧能带来提升,并且可以让7B模型达到接近72B模型的性能。
总结
目前基于RL的多模态reasoning工作围绕设计和训练流程展开,在适合推理的任务上RL表现很好,且有比较好的泛化性能。然而,对于无法设计metric的任务,就无法用现在GRPO进行优化,需要合适的reward model。并且,现有的工作主要聚焦于将GRPO应用于多模态场景,但缺乏对其作用机理的研究和认识,比如RL为什么相比SFT具备更强的泛化能力?这是一个值得探索的问题。
另外,目前对于多模态的推理工作方法缺乏多模态侧的motivation,比如R1-VL设计的reward只对文本进行特殊处理,不涉及对多模态理解本身的改进。最后,RL的跨任务迁移能力也有待探索。目前工作的实验尽管验证了RL的泛化性能,但评测仍主要由相同下游任务不同领域图片构成,而非不同的任务类型,基于RL的训练方式是否能够泛化到没见过的任务上也是一个值得探索的问题。
引用链接
[1] Llava-cot: Let vision language models reason step-by-step:https://arxiv.org/abs/2411.10440[2]Enhancing the reasoning ability of multimodal large language models via mixed preference optimization:https://arxiv.org/abs/2411.10442[3]Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search:https://arxiv.org/abs/2412.18319[4]R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization:https://arxiv.org/abs/2503.12937[5]Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning:https://arxiv.org/abs/2503.20752[6]OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement:https://arxiv.org/abs/2503.17352
(文:机器学习算法与自然语言处理)