


尽管人工智能(AI)在飞速发展,当前 AI 开发仍严重依赖人类专家大量的手动实验和反复的调参迭代,过程费时费力。这种以人为中心的方式已成为制约创新速度和通向通用人工智能(AGI)的关键瓶颈。为突破限制,AI-for-AI(AI4AI)应运而生。AI4AI 旨在让 AI 作为智能体来自主设计、优化和改进 AI 算法,大幅减少人类干预,加速迭代开发周期,推动 AGI 发展进程。

最近,上海交通大学与上海人工智能实验室联合团队最新研究表明,一个仅依赖 7B 参数大模型的 AI 智能体(ML-Agent),采用 “经验学习” 新范式,只在 9 个机器学习任务上持续探索学习,迭代进化,最终就能设计出超越 671B Deepseek-R1 驱动的智能体设计的 AI 模型,首次实现了在自主机器学习领域从 “提示工程” 到 “经验学习” 的范式跃迁,开创了 AI4AI 的新路径。

-
论文标题:
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
-
论文地址:
https://arxiv.org/pdf/2505.23723
-
代码地址:
https://github.com/MASWorks/ML-Agent
😫 传统自主机器学习:费时低效的困境
传统机器学习工程繁琐低效,研究人员常需数天至数月进行模型设计、参数调优,与反复试错,限制了 AI 创新发展的速度。最近,基于大语言模型(LLM)的智能体(Agent)的出现给该领域带来显著变革。它们能理解自然语言指令,生成代码并与环境交互,实现自主机器学习(Autonomous Machine Learning,AI4AI),提升 AI 开发效率。
然而,这些智能体仍高度依赖人工设计的提示词(Prompt Engineering),缺乏从经验中自主学习与泛化的能力。其能力提升仍需研究人员根据数小时的执行结果不断调整提示词形成 “等待 – 修改 – 重试” 的低效循环,仍难以摆脱对人力的依赖与效率瓶颈。
😀 AI4AI 破局之路:从指令遵循到自我进化
为解决这一关键限制,该研究首次探索了基于学习的智能体自主机器学习范式,其中智能体可以通过在线强化学习从机器学习任务的执行轨迹中进行学习。这种方式使得智能体能够主动探索不同的策略,跨任务积累知识,逐步优化决策,持续从自身经验中学习,并通过训练不断提升其设计优化 AI 的能力。
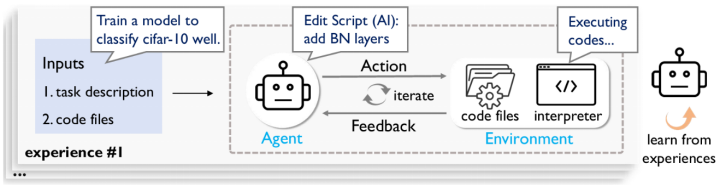
自主机器学习流程
🤖 ML-Agent:首个经验学习的 AI4AI 智能体
利用提出的训练框架,研究人员训练了一个由 7B 规模的 Qwen2.5 大模型驱动的自主机器学习智能体。在训练过程中,智能体能够高效地探索机器学习的环境,从经验中学习,并通过对各种机器学习任务的迭代探索实现持续的性能提升。令人惊喜的是,只在 9 个机器学习任务上反复学习,7B 的智能体不仅超越了 671B 规模的 DeepSeek-R1 智能体,还表现出了卓越的跨任务泛化能力。这项研究标志着 AI 智能体在设计 AI 中从 “工具执行者” 向 “自主学习者” 的转变,带来了 “AI 自主设计 AI” 的新范式。
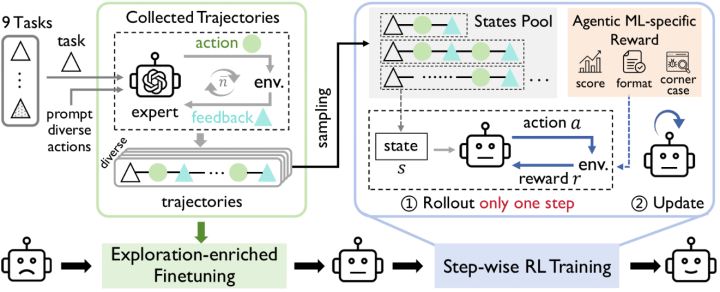
自主机器学习训练框架
🌟 三大核心突破,解锁 AI 自进化
研究团队提出全新训练框架,攻克自主机器学习三大难题:
1️⃣ 敢想敢试:探索增强微调
-
问题:传统自主机器学习智能体重复相似操作,创新受限!
-
解法:探索增强微调 (Exploration-enriched fine-tuning),通过精心设计的多样化的专家轨迹数据集,训练智能体尝试不同策略,大幅提升探索能力。
-
效果:拓宽智能体的探索范围,增强后续强化学习阶段多样化策略生成能力,不再局限局部最优解,而是具备更广泛的策略选择空间!
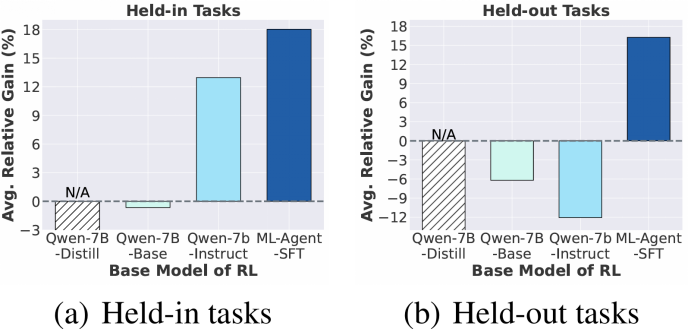
探索增强微调助力强化学习训练
2️⃣ 快速迭代:逐步强化学习范式
-
问题:完整迭代机器学习实验需数小时,传统 RL 方法在机器学习实验中采样效率低下!
-
解法:逐步强化学习范式(Step-wise RL paradigm),重构训练目标函数,每次只优化单步动作,数据收集效率提升数倍。
-
效果:RL 训练阶段可扩展性提高,训练时间显著缩短!
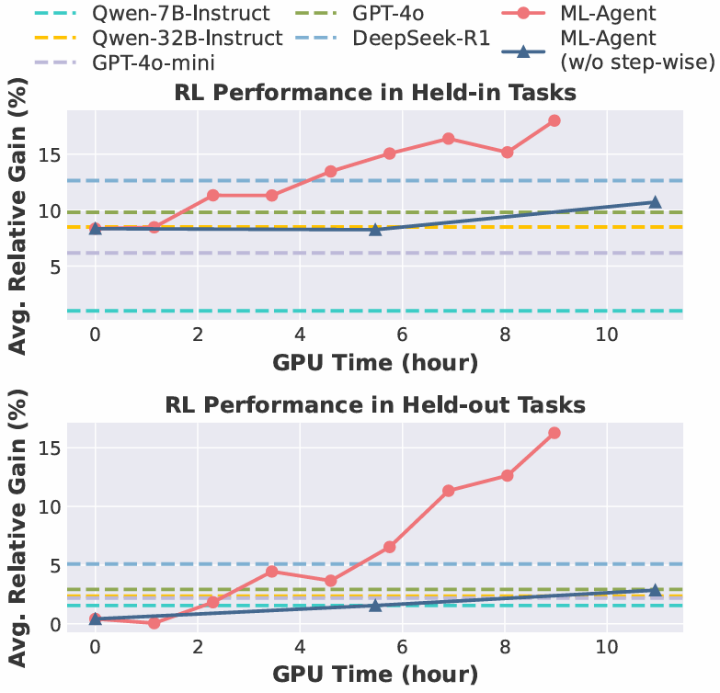
逐步强化学习(红线,每训练 5 步进行一次评测)比基于整条轨迹的强化学习(蓝线,每训练 1 步进行一次评测)更高效
3️⃣ 听懂反馈:定制化奖励模块
-
问题:实验反馈复杂(如代码错误、资源溢出、性能提升),难以统一!
-
解法:机器学习定制化奖励模块(Agentic ML-Specific Reward Module) 惩罚错误、鼓励改进,将机器学习多样执行结果转换为统一反馈。
-
效果:为 RL 优化提供一致有效的奖励信号,推动智能体在自主机器学习训练中进行持续迭代改进!
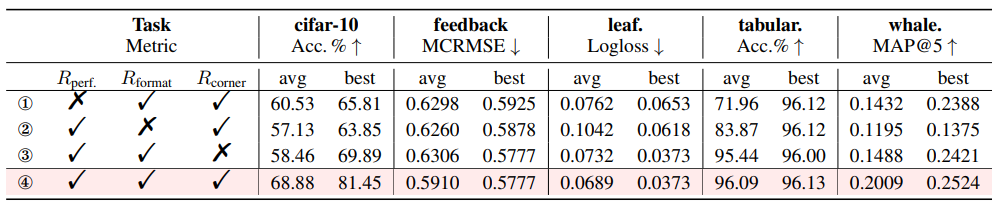
机器学习定制化奖励模块每一组成部分的有效性
📊 ML-Agent 持续进化,展现泛化能力!
研究团队利用所提训练框架训练了一个由开源大模型 Qwen2.5-7B 驱动的自主机器学习智能体 ——ML-Agent,并开展广泛的实验以评估其性能。结果表明:
✅ ML-Agent 具有强大泛化能力
研究将 ML-Agent 与 5 个强大的开源 / 闭源 LLM 驱动的智能体进行了比较。下表说明,ML-Agent 在见过 / 未见过的机器学习任务中的平均和最好性能都达到了最高。令人惊喜的是,只在 9 个机器学习任务上不断学习,7B 大模型驱动的 ML-Agent 就在所有 10 个未见过的机器学习任务上超过了 671B 的 Deepseek-R1 驱动的自主机器学习智能体,展现出了强大的泛化能力。
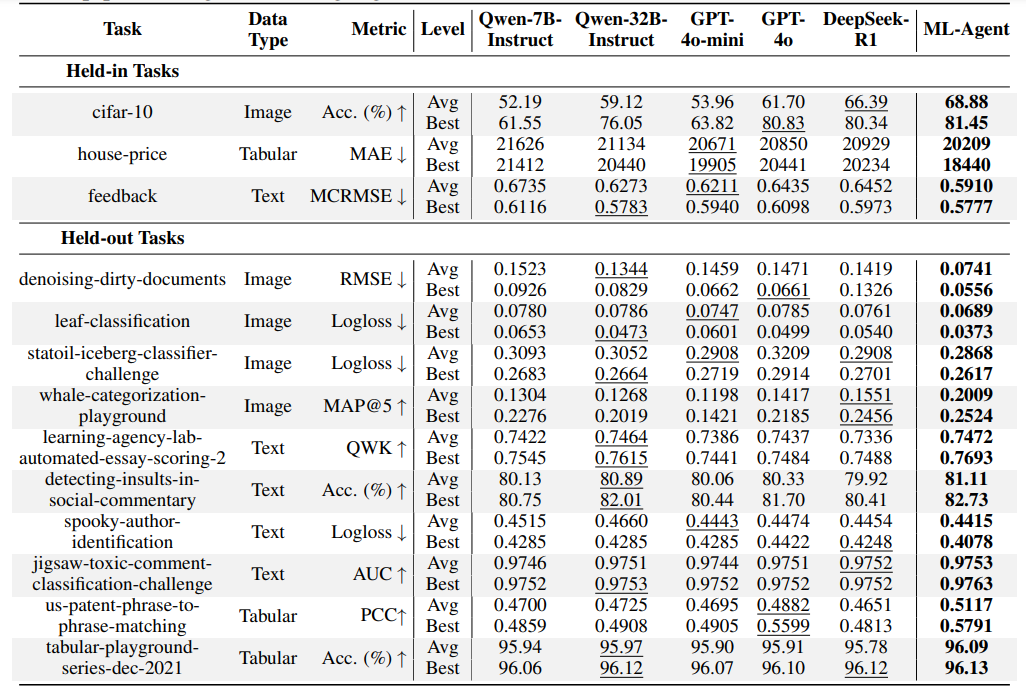
ML-Agent 具有强大泛化能力
✅ ML-Agent 优于最先进方法
为了进一步证明训练框架的有效性,研究人员将 ML-Agent 与一个专门为自主机器学习设计的 LLM 智能体(AIDE)作比较。结果显示,ML-Agent 总体优于 AIDE 智能体,凸显了所提训练框架的有效性。
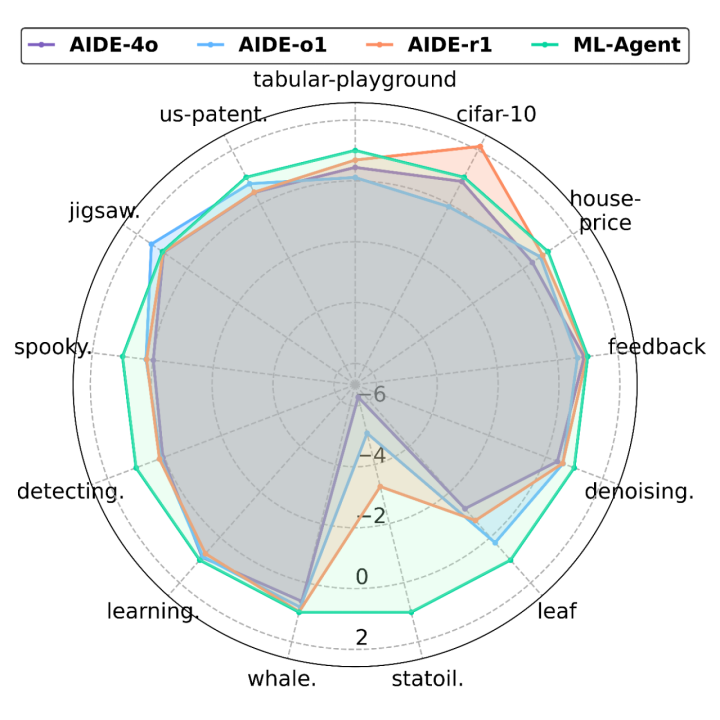
ML-Agent 优于最先进的自主机器学习智能体
✅ ML-Agent 持续进化
随着训练的进行,ML-Agent 不断自我探索,从自主机器学习的经验中学习,在训练过 / 未经训练过的机器学习任务上性能持续提升,最终超越所有基线方法。
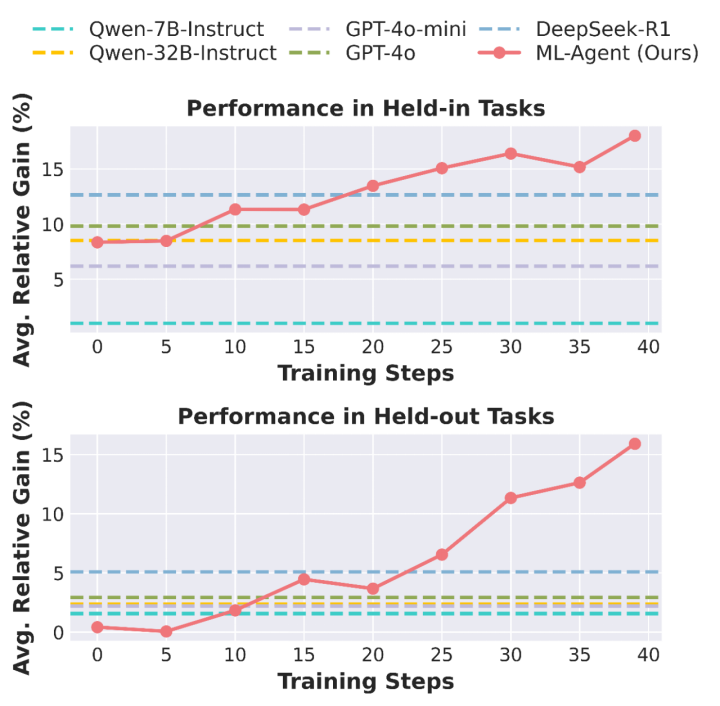
ML-Agent 的自主机器学习能力在训练中持续提升
ML-Agent 引领了 AI4AI 的新范式,将自主机器学习从依赖人类优化的、提示工程的低效模式,转变为智能体自主探索的、基于自我经验学习的设计方式。这一转变大幅减少人类干预,加速了 AI 算法的设计迭代。随着 ML-Agent 在更多的机器学习任务上持续自我学习与探索,其能力有望不断提升,设计出更高效智能的 AI,为构建强大的 AI4AI 系统奠定坚实基础,为实现通用人工智能的长远目标贡献关键力量。
🔥 MASWorks 大模型多智能体开源社区
ML-Agent 也是最近刚发起的大模型多智能体开源社区 MASWorks 的拼图之一。MASWorks 社区致力于连接全球研究者,汇聚顶尖智慧,旨在打造一个开放、协作的平台,共同分享、贡献知识,推动多智能体系统(MAS)领域的蓬勃发展。
作为社区启动的首个重磅活动,MASWorks 将在 ICML 2025 举办聚焦大语言模型多智能体的 Workshop:MAS-2025!期待全球广大学者的积极参与,共同探讨、碰撞思想,描绘 MAS 的未来蓝图!
-
MASWorks 地址:
https://github.com/MASWorks
-
MAS-2025 地址:
https://mas-2025.github.io/MAS-2025/
©
(文:机器之心)