

生成式人工智能正以前所未有的速度发展,堪比手机和互联网的快速演进。如今,人工智能模型的参数规模已达到数十亿,甚至数百亿,对计算能力的需求急剧上升。统计数据显示,2015年全球生成的数据量约为10艾字节(EB)。到2025年,预计这一数字将飙升至175泽字节(ZB),而到2035年,可能会达到惊人的2432泽字节。

“依赖云端来处理所有这些数据显然是不现实的,”Actions Technology 董事长兼首席执行官周正宇博士表示要使人工智能真正普及并发挥其全部潜力,计算任务必须在云服务器和边缘设备(如个人电脑、智能手机、汽车和物联网(IoT)设备)之间合理分配,而不是仅依赖云端。
这种云和边缘人工智能协同工作的架构被称为混合人工智能。业界普遍认为,这种架构将提供更强大、高效和优化的人工智能体验。换句话说,要使人工智能真正触手可及并无缝融入日常生活,部署边缘人工智能至关重要。

然而,随着边缘人工智能的发展,它面临着两大挑战。首先,我们需要在性能、功耗和成本之间找到平衡。在增强计算能力的同时,如何在不使功耗和成本超出合理范围的情况下取得最佳结果,特别是在电池供电的低功耗设备中?其次,构建一个稳健的生态系统至关重要。类似于中央处理器(CPU)和图形处理器(GPU)的发展,一个统一的生态系统是必要的,包括工具链、语言、兼容性和开发便捷性,以推动人工智能技术的普及和大规模应用。
边缘人工智能部署的优势
边缘人工智能将机器学习无缝集成到物联网设备中,减少了对云计算能力的依赖。即使在没有网络连接或网络拥堵的情况下,它也能提供低延迟的人工智能体验。此外,边缘人工智能还具有显著的优势,包括低功耗、增强的数据隐私和更高的个性化。这些是部署边缘人工智能的核心优势。

周正宇博士指出,从边缘人工智能到生成式人工智能,人工智能应用对计算能力的需求各不相同。许多边缘人工智能应用是专门化的,并不需要大型模型或大量的计算能力。这在物联网人工智能(AIoT)领域尤其如此,如语音交互、音频处理、预测性维护和健康监测。因此,边缘人工智能对于人工智能的广泛应用至关重要,而将人工智能集成到电池供电的低能耗物联网设备中是实现边缘人工智能的关键。
据ABI Research预测,边缘人工智能市场正在迅速扩张。到2028年,基于中小型模型的边缘人工智能设备数量预计将达到40亿台,年复合增长率(CAGR)为32%。到2030年,预计75%的这些物联网人工智能设备将使用高能效的专用硬件。
例如,主流的可穿戴产品,如耳机和智能手表,以及其他便携式音频设备,如蓝牙音箱,平均功耗范围从十几毫瓦到几十毫瓦不等,存储容量低于10兆字节(MB)。这定义了低功耗边缘人工智能,特别是在可穿戴设备中的资源预算。

为此,Actions Technology 最近推出了其“Actions Intelligence”战略,以推动电池供电的低功耗音频边缘人工智能应用的发展,这些应用的模型参数低于1000万个(10M)。该公司的目标是为低功耗物联网人工智能设备提供0.1-1万亿次操作每秒(TOPS)的通用人工智能计算能力,且功耗预算范围在10毫瓦至100毫瓦之间。
这意味着,作为一家致力于以毫瓦级功耗提供TOPS级人工智能计算能力的公司,以满足物联网设备的低功耗和高能效需求,Actions Technology 旨在通过其“Actions Intelligence”战略实现10 TOPS/W至100 TOPS/W的人工智能计算效率。
克服冯·诺依曼架构中的瓶颈
现有的通用中央处理器(CPU)和数字信号处理器(DSP)在算法方面具有很大的灵活性,但它们的计算能力和能效不足以满足既定目标。根本原因在于传统的冯·诺依曼架构将内存和计算单元分离,导致了“内存墙”和“功耗墙”瓶颈,阻碍了计算能力和能效的提升。
“内存墙”指的是在冯·诺依曼架构中,计算单元必须先从内存中提取数据,然后在计算完成后再将结果写入内存。然而,由于处理器和内存的设计工艺、封装和要求不同,内存访问速度无法跟上处理器的处理速度。结果,数据流受到限制,就像水流过狭窄的漏斗一样。无论处理器发送多少数据,内存一次只能处理少量数据。这种狭窄的数据交换路径和由此产生的高能耗在存储和计算之间形成了“内存墙”。

此外,在传统架构中,将数据从内存传输到计算单元所需的能量远高于计算本身所需的能量。这意味着大部分能量和时间都消耗在数据传输上,而不是计算本身。内存和处理器之间频繁的数据迁移导致了显著的功耗,这被称为“功耗墙”。例如,测试结果显示,英特尔7nm的CPU大约有63%的功耗用于数据传输,而不是计算。
Arm和Cadence的公开数据显示,使用28/22nm工艺的ARM A7 CPU,运行频率为1.2 GHz,其理论计算能力为0.01 TOPS,但功耗为100 mW,理想能效仅为0.1 TOPS/W。类似地,运行频率为600 MHz的HiFi4 DSP,其理论计算能力为0.01 TOPS,但功耗为40 mW,理想能效为0.25 TOPS/W。即使是Arm中国专门的神经处理单元(NPU)系列“周易”在能效方面也取得了显著的改进,但其能效仍然只有2 TOPS/W。

周正宇博士认为,“解决‘内存墙’和‘功耗墙’的最佳方法是采用基于静态随机存取存储器(SRAM)的内存计算(CIM)架构。”CIM的核心思想是将计算(部分或全部)转移到内存中,以便内存单元可以直接执行计算。这消除了对单独计算单元的需求,并使内存单元能够同时处理存储和计算,从而降低数据访问和存储延迟以及功耗。本质上,CIM集成了内存和计算。通过完全依赖内存进行计算,CIM能够实现更细粒度的并行处理,从而显著提高性能,尤其是在能效方面。
虽然实现“内存-计算集成”并非易事,但人工智能本质上是神经网络,由无数个神经元协同工作形成复杂的计算模式。机器学习算法严重依赖矩阵运算,而矩阵运算非常适合分布式并行处理。因此,CIM是人工智能应用的理想解决方案。
知易行难。“边缘AI部署需要创新。”
将计算集成到内存中,根本上取决于选择合适的存储介质,这对于成本和成功都至关重要。周正宇博士指出,公司旨在将低功耗边缘AI和其他片上系统(SoC)模块的计算能力集成到单个芯片中。这种方法排除了使用需要特殊工艺的DDR RAM和Flash。相反,采用互补金属氧化物半导体(CMOS)工艺的SRAM,以及新兴的非易失性随机存取存储器(NVRAM)技术,如电阻式随机存取存储器(RRAM)和磁阻式随机存取存储器(MRAM),更适合。
采用成熟工艺的SRAM可以进行升级以保持与先进工艺的兼容性。它具有快速的读/写速度、高能效和无限的读/写周期。其唯一的限制是内存密度低,但这足以满足大多数边缘AI应用的计算能力需求。短期内,SRAM是实现低功耗边缘AI设备高能效的最佳解决方案。它确保快速部署,没有大规模生产风险。
长期来看,诸如RRAM之类的NVRAM新兴技术(其密度高于SRAM,读功耗更低)可以集成到SoC中,为CIM架构开辟新的可能性。然而,RRAM技术仍处于早期阶段,大规模生产存在风险,目前最先进的制造工艺仅限于22nm。此外,一个显著的缺点是其写入周期有限,超过此限制可能会造成永久性损坏。因此,周正宇博士设想了一种将SRAM和RRAM结合的混合技术,作为RRAM完全开发后的最佳解决方案。在这个方案中,基于SRAM的CIM将处理需要频繁写入的AI计算,而基于RRAM的CIM将用于写入较少或不太频繁的任务。这种混合解决方案有望提供更大的计算能力和更高的能效。
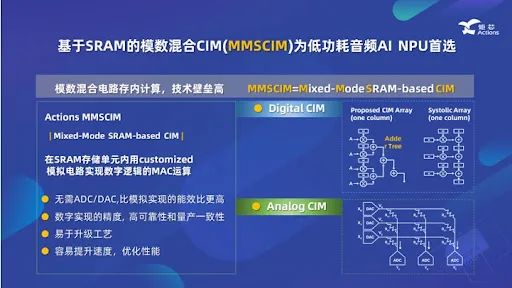
目前,业界实现基于SRAM的CIM电路主要有两种方法。方法一使用数字电路在尽可能靠近SRAM的地方执行计算。然而,由于计算单元实际上不是SRAM阵列的一部分,因此该方法本质上是一种近内存技术。方法二需要利用SRAM介质中某些模拟器件的特性来执行模拟计算。虽然这种方法实现了真正的CIM,但它有很大的缺点。模拟计算的精度受到影响,一致性和可制造性可能无法保证。这意味着同一芯片在不同时间、不同条件下可能会产生不一致的结果。此外,这种方法需要模数转换器(ADC)和数模转换器(DAC)来交换基于模拟计算的CIM和其他数字模块之间的数据。这限制了数据流管理和接口交互设计,阻碍了运行效率的提高。
为了解决这些问题,Actions Technology推出了其混合模式SRAM基CIM (MMSCIM)技术,该技术在SRAM介质中使用定制的模拟设计来实现数字计算电路。这一突破实现了真正的CIM,同时保持了计算精度,并确保了大规模生产的一致性。
周正宇博士强调了MMSCIM的几个优点。首先,MMSCIM比纯数字解决方案具有更高的能效,几乎与全模拟系统的能效相匹配。其次,MMSCIM消除了对ADC/DAC的需求,确保了数字精度、高可靠性和大规模生产的一致性,这是数字技术的固有优势。第三,MMSCIM能够适应工艺升级,并且可以轻松地转移到不同的半导体制造厂(FAB)。第四,MMSCIM可以轻松提高速度并优化性能、功耗和面积(PPA)。最后,MMSCIM对稀疏矩阵的适应性进一步提高了能效并降低了功耗。

对于高质量的音频处理和语音应用,MMSCIM是未来低功耗边缘AI音频技术的最佳架构。通过消除内存和存储之间数据传输的需要,MMSCIM显著降低了延迟,提高了性能,并最大限度地减少了功耗和热量产生。对于需要最大能效的电池供电的物联网设备,Actions Technology的MMSCIM技术为将边缘AI变为现实提供了理想的解决方案,在这些设备中,每一毫瓦都至关重要,用于优化AI计算能力。
根据Actions Technology公布的首个MMSCIM路线图,GEN1 MMSCIM于2024年推出。GEN1 MMSCIM基于22nm工艺构建,每个内核的性能为100 GOPS,能效达到6.4 TOPS/W @INT8。由于其能够适应稀疏矩阵,因此对于具有合理稀疏性的模型(即某些参数为零时),可以进一步优化能效。根据稀疏程度的不同,能效可能超过10 TOPS/W。
2025年,Actions Technology计划发布GEN2 MMSCIM,同样基于22nm工艺构建,性能比GEN1提高三倍。GEN2 MMSCIM的每个内核将提供300 GOPS的计算能力,支持transformer模型,并实现7.8 TOPS/W @INT8的能效。到2026年,将推出使用12nm工艺的GEN3 MMSCIM,每个内核将提供1 TOPS的计算能力,支持transformer模型,并实现高达15.6 TOPS/W @INT8的能效。
每一代MMSCIM技术都通过内核叠加来提高总计算能力。例如,每个内核具有300 GOPS的GEN2 MMSCIM,通过组合四个内核可以实现超过1 TOPS的计算能力。
下一代边缘AI音频芯片为何如此强大?
炬芯科技推出的基于MMSCIM的下一代边缘AI音频芯片包含三个系列:ATS323X系列专注于实现低延迟私有无线音频传输,ATS286X系列则面向蓝牙AI音频应用领域,而ATS362X系列则致力于满足AI DSP应用需求。
每个系列均采用异构架构设计,巧妙融合了CPU(ARM)、DSP(HiFi5)和NPU(MMSCIM)。炬芯科技通过创新技术,将MMSCIM与先进的HiFi5 DSP整合为“炬芯智能NPU(AI-NPU)”架构,这一架构通过协同计算,实现了高灵活性与高效能的完美结合。在此架构中,MMSCIM负责处理基础且通用的AI算子,以低功耗提供强劲的计算能力。而随着新兴AI模型和算子的不断涌现,HiFi5 DSP则补充支持MMSCIM未涵盖的特殊算子,确保系统的全面性和前瞻性。
这些边缘AI芯片支持最多达一百万参数的片上AI模型,并可通过外部伪静态随机存取存储器(PSRAM)轻松扩展至八百万参数,满足更广泛的应用需求。此外,炬芯科技还开发了“ANDT”(Actions NPU Development Tools,炬芯NPU开发工具),这是一款专为AI-NPU架构量身打造的AI开发工具。该工具全面支持TensorFlow、HDF5、PyTorch和ONNX等标准AI开发工作流,让开发者能够更便捷地进行AI算法的开发和部署。ANDT能够智能地在CIM和HiFi5 DSP之间分配AI算法任务,实现低功耗与高效能的平衡,助力低功耗边缘音频AI生态系统的快速发展。
周振宇博士分享了GEN1 MMSCIM与HiFi5 DSP的能效测试结果。在500兆赫兹频率下,使用717K参数的卷积神经网络(CNN)模型进行环境噪声消除测试时,MMSCIM相比HiFi5 DSP降低了近98%的功耗,能效显著提升了44倍。在另一项使用935K参数CNN模型进行语音识别的测试中,MMSCIM同样表现出色,降低了93%的功耗,能效提升了14倍。
此外,在使用更复杂的网络模型进行环境噪声消除的测试中,GEN1 MMSCIM也展现出了卓越的性能。在运行深度循环神经网络时,相比HiFi5 DSP降低了89%的功耗;在运行卷积循环神经网络时,降低了88%的功耗;在运行卷积深度循环神经网络时,降低了76%的功耗。在相同条件下,运行特定CNN-Con2D算子模型时,GEN1 MMSCIM的AI计算能力更是达到了HiFi5 DSP的16.1倍,充分展示了其强大的计算能力和能效优势。
通往高质量音频的道路
音频处理既复杂又系统化。高质量音频不仅仅依赖于硬件信号链(包括前置放大器、ADC/DAC、音频处理、编解码器和模拟放大器),还需要每个处理过程都满足可量化的客观指标,例如高信噪比、低噪声底限、宽动态范围和高线性度。同样重要的是理解人类的听觉偏好,并将电子科学和声学无缝地融入设计中。
周正宇博士指出:“是的,尤其是在主观方面。悦耳的声音没有普遍的定义;每个人都有自己的偏好,每个品牌都有自己的标志性风格。”凭借在音频行业超过20年的经验,周正宇博士将 Actions Technology 作为领先的国际品牌的主观和客观认可归因于其“深厚的专业知识和丰富的经验”。这使得公司研发团队能够理解什么是自然、清晰和悦耳的声音,并进行必要的调整,将芯片、算法和声学完美融合。

另一个关键趋势是人工智能的快速发展,它为人工智能与音频的集成开辟了新的可能性。人工智能正在通过语音识别、噪声控制、语音翻译、关键词识别、语音增强和语音分离方面的创新来改变音频行业。这些进步正在推动音频设备和系统的创新和改进,为消费者提供更丰富、更个性化的体验,无论是在家中、个人音乐欣赏还是商业应用中。
周正宇博士将人工智能视为一种新型计算,它使用基于神经网络的深度学习计算来替代音频领域的传统符号逻辑计算,从而极大地增强了用户体验。他解释说:“在我看来,每种音频产品都应该使用人工智能进行改进,尤其是在与专业、低功耗、高效的硬件相结合时。这可以显著提高模型效率。”
目前,无线家庭影院系统、游戏耳机和麦克风等低延迟、高质量音频产品市场占据主导地位。周正宇博士预测,未来将涌现更多利基市场,例如更专业的直播麦克风和其他需要超低延迟的无线设备。对优先考虑完全沉浸式体验的 7.1.4 声道(即 12 声道)环绕声系统的需求将挑战无线传输带宽、采样率和延迟。这将推动对高带宽私有无线技术、人工智能音频处理和新编解码器技术的需求,以满足对超低延迟和卓越音质的需求。
根据QYResearch的数据,全球无线音频设备市场(包括条形音箱、耳机、麦克风和无线扬声器)在2023年达到1996.28亿元人民币,其中中国市场占654.38亿元人民币。预计到2029年,这一数字将增长到5820.85亿元人民币,复合年增长率约为19.25%。主要市场包括商业、汽车、消费和家庭应用。

以智能眼镜、智能耳机、智能手表和智能手环等产品为主导的可穿戴设备市场也显示出巨大的潜力。IDC预测,2024年全球可穿戴设备出货量将同比增长6.1%,达到5.379亿台,其中可听戴设备占总量的57.7%。Canalys还报告称,2024年第二季度,全球智能个人音频出货量达到1.1亿台,创下历史最高第二季度出货量,同比增长10.6%。
在这种情况下,人工智能技术的探索和应用无疑将成为各行业的热门话题,释放人工智能技术增强用户体验的巨大潜力。对于公司而言,从单一产品供应商转变为提供系统解决方案将成为常态。企业将越来越需要通过开放平台和工具构建独特的AI生态系统,使客户能够基于基础组件开发差异化解决方案,同时平衡性能、成本和功耗。
结论
从ChatGPT到Sora,从文本到文本、文本到图像再到文本到视频、图像到文本以及视频到文本的技术,基于云的大型模型不断突破人工智能能力的边界。然而,人工智能的发展之路仍然漫长。从云端向边缘计算的转变正成为一大趋势。边缘人工智能凭借其低延迟、个性化服务和增强的数据隐私等优势,将在物联网设备中发挥越来越重要的作用,为制造业、汽车业和消费品等行业带来激动人心的新机遇。
(文:AI音频时代)