

极市导读
高达 128 倍下采样的 Autoencoder,以加速高分辨率扩散模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
本文提出了 Deep Compression Autoencoder (DC-AE) ,一种新的 Autoencoder,用于加速高分辨率扩散模型。现在的 Autoencoder 一般是 8 倍下采样的情况下结果很好,但是在高空间压缩比 (比如 64 倍) 下就没办法保持令人满意的重建精度。
为了解决这一挑战,DC-AE 提出了 2 个关键技术:
-
Residual Autoencoding: 学习残差,以减轻高空间压缩比 Autoencoder 的优化难度。 -
Decoupled HighResolution Adaptation: 高效的解耦 3 阶段训练策略,减轻高空间压缩比 Autoencoder 的泛化惩罚。通过这些设计,在保持重建质量的同时,将自动编码器的空间压缩比提高到 128。将 DC-AE 应用于 latent diffusion model,可以实现显著加速,而不会降低精度。
在 ImageNet 512×512 上,与 SD-VAE-f8 Autoencoder 相比,DC-AE 在 H100 GPU 上为 UViT-H 提供了 19.1 倍的 inference speedup 和 17.9 倍的 training speedup。

本文贡献
-
分析了增加 Autoencoder 空间压缩比的挑战,并分析了如何应对这些挑战。 -
提出了 Residual Autoencoding 和 Decoupled HighResolution Adaptation,有效提高了高空间压缩比 Autoencoder 的重建精度,使其重建精度在 latent diffusion model 中使用可行。 -
构建了 DC-AE,这是一种新的 Autoencoder。与以前的 Autoencoder 相比,它为扩散模型提供了显着的训练和推理加速。
本文目录
1 DC-AE:为高效扩散模型设计的超高倍下采样 Autoencoder
(来自 MIT 韩松团队,清华大学,NVIDIA 韩松团队)
1 DC-AE 论文解读
1.1 DC-AE 研究背景
1.2 高空间压缩比 Autoencoder 的局限性
1.3 DC-AE 贡献 1:Residual Autoencoding
1.4 DC-AE 贡献 2:Decoupled High-Resolution Adaptation
1.5 DC-AE 与 Latent Diffusion Model 的结合
1.6 实验结果
1 DC-AE:为高效扩散模型设计的超高倍下采样 Autoencoder
论文名称:Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models (ICLR 2025)
论文地址:
http://arxiv.org/pdf/2410.10733
Project Page:
http://github.com/mit-han-lab/efficientvit
1.1 DC-AE 研究背景
Latent Diffusion Model(LDM)在图像生成领域取得了巨大成功。LDM 使用 Autoencoder 将图像投影到 latent 空间,以降低扩散模型的成本。当前 Latent Diffusion Model 中主要采用的解决方案是使用空间压缩比为 8 的 Autoencoder(表示为 f8),将空间大小 的图像转换为空间大小 的 latent 特征。这种空间压缩比对于低分辨率图像生成(比如 )还是令人满意的。但对于高分辨率图像生成(比如 ),进一步增加空间压缩比至关重要,尤其是对于具有二次计算复杂度的 DiT 模型。
目前,进一步减少空间大小的常见做法是在扩散模型端进行下采样。在 Diffusion Transformer 模型中,这是通过使用具有 Patch size 为 的 Patch Embedding 层来实现的,该层将 latent 特征压缩为 tokens。之前的工作都集中在扩散模型端。相比之下,Autoencoder 端几乎没有努力。本文工作为加速扩散模型开辟了一个新的方向,即在 Autoencoder 端努力。
高空间压缩 Autoencoder 使用的主要瓶颈是重建精度下降。例如,图 2 显示了具有不同空间压缩比的 ImageNet 256×256 上 SD-VAE 的重建结果。可以看到,如果从 f8 切换到 f64,rFID 从 0.90 下降到 28.3。
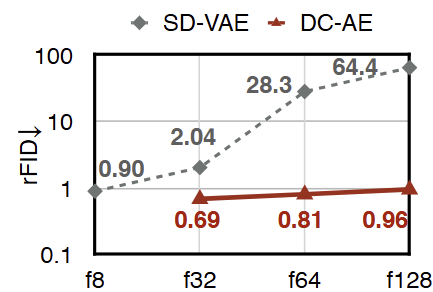
因此,DC-AE 的思路就是在 Autoencoder 端进行超高倍数的下采样 (空间压缩比上升到 32, 64, 128 倍),同时保持良好的重建精度的工作。这样一来,扩散模型就可以专注于对压缩之后的 token 进行去噪任务,而 DC-AE 专注于 token 压缩任务。
1.2 高空间压缩比 Autoencoder 的局限性
作者探索了高空间压缩比以及低空间压缩比 Autoencoder 之间精度差异的深层原因。具体而言,考虑 3 种空间压缩比逐渐增加的设置,从 f8 到 f64。每次空间压缩比增加时,在当前 Autoencoder 上堆叠额外的 Encoder 和 Decoder Stage。通过这种方式,高空间压缩比 Autoencoder 包含低空间压缩比的 Autoencoder 作为子网络,因此具有更强的学习能力。
结果如下图 3 所示。即使具有相同的总 latent size 以及更强的学习能力,当空间压缩比增加时,仍然观察到重建精度下降。这些结果表明添加的 Encoder 和 Decoder Stage (由多个 SD-VAE Block 组成) 比简单的 space-to-channel 操作差。
基于这一发现,作者推测精度的差距来自模型学习的过程:虽然在参数空间中具有良好的局部最优性,但优化难度阻碍了高空间压缩比 Autoencoder 达到这种局部最优。
1.3 DC-AE 贡献 1:Residual Autoencoding
Residual Autoencoding 如下图 4 所示。
顾名思义,Residual Autoencoding 就是给 Downsample Block 和 Upsample Block 添加残差。但是与传统的设计的主要区别在于,这里的残差并非 ResNet 中的 Identity Mapping,而是 Space-to-Channel 操作 (和 Channel-to-Space 操作),如下图 4(b) 左侧所示。
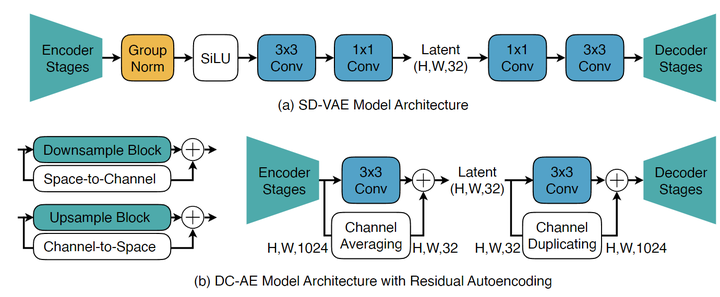
那么,如何给 Downsample Block 和 Upsample Block 添加残差呢?在实践中,DC-AE 的做法是:
给 Downsample Block 添加一个 Space-to-Channel 的操作 + Channel Average 操作 (匹配上 channel 数)。
给 Upsample Block 添加一个 Channel-to-Space 的操作 + Channel Duplicating 操作 (匹配上 channel 数)。
例子:
假设 Downsample Block 输入特征图形状为 ,其输出特征图形状为 ,则添加的 Shortcut 为:

对于 Upsample Block 输入特征图形状为 ,其输出特征图形状为 ,则添加的 Shortcut 为:
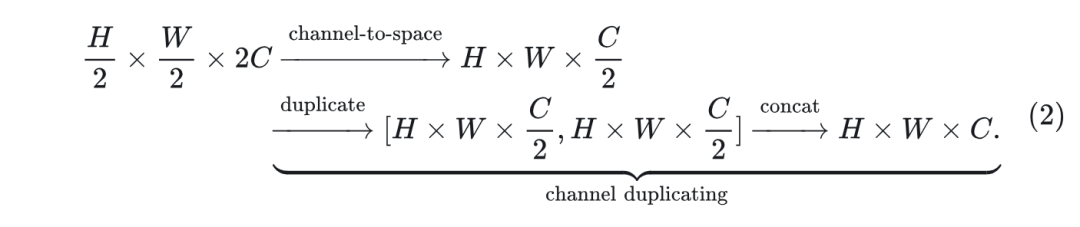
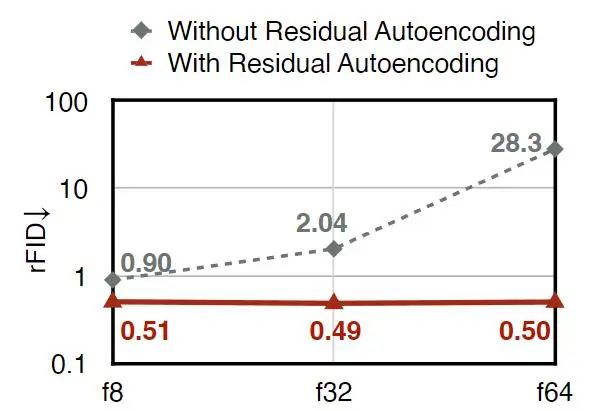
除了 Downsample Block 和 Upsample Block 外,还按照相同的原则改变中间 Stage 的设计,如图 4(b) 右侧所示。图 3(a) 显示了 ImageNet 256×256 上使用和不使用 Residual Autoencoding 的比较。可以看到,Residual Autoencoding 有效地提高了高空间压缩自编码器的重构精度。
1.4 DC-AE 贡献 2:Decoupled High-Resolution Adaptation
单独使用 Residual Autoencoding 就已经可以解决处理低分辨率图像时的精度差距。然而,当扩展到高分辨率图像时是不够的。由于高分辨率训练的高成本,高分辨率扩散模型的常见做法是:**直接使用在低分辨率图像上训练的 Autoencoder[1]**。该策略适用于低空间压缩比 Autoencoder。然而,高空间压缩比 Autoencoder 存在显著的精度下降问题。
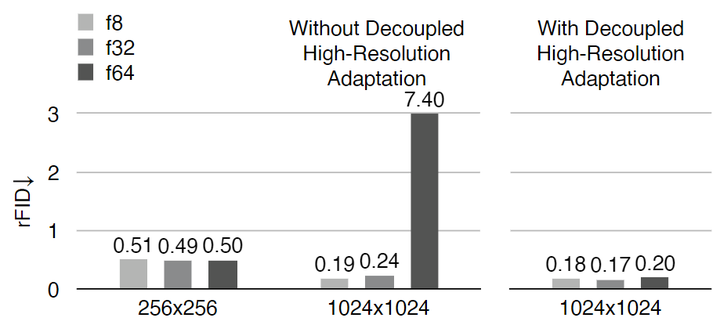
在图 3(b) 中,可以看到 f64 Autoencoder 的 rFID 在从 256×256 上升到 1024×1024 时从 0.50 下降到 7.40。相比之下,在相同设置下,f8 Autoencoder 的 rFID 从 0.51 提高到 0.19。
此外,当使用更高的空间压缩比时,作者还发现这个问题更加严重。本文将这种现象称为:高空间压缩比 Autoencoder 的泛化性惩罚。解决这个问题的一个直接方案是对高分辨率图像进行训练。然而,存在较大的训练成本,且高分辨率 GAN Loss 训练不稳定。
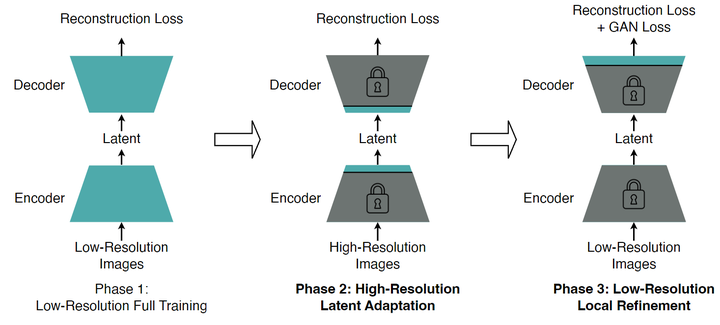
图 6 展示了 Decoupled High-Resolution Adaptation 的做法。与传统的单相训练策略[2]相比,Decoupled High-Resolution Adaptation 有 2 个关键的区别。
第 1 个区别是来自作者这样的发现:单独的 Reconstruction Loss 足以学习重建内容和语义,GAN Loss 主要改进了局部细节并去除了局部伪影 (图 7)。因此,第 1 个区别是:作者将 GAN Loss 训练与完整模型训练解耦,并为 GAN Loss 训练引入了一个专用的 local refinement 阶段 (图 6,Phase 3)。这个阶段只微调 Decoder 的头部层,同时冻结所有其他层。这个做法可以实现相同的局部细化的目标,同时只微调 Decoder 的头部层具有较低的训练成本,并且比完整训练提供更高的精度。而且,这种方法使我们能够在低分辨率图像上进行 local refinement 阶段,而不必担心泛化性惩罚。进一步降低了 Phase 3 的训练成本,避免了高度不稳定的高分辨率 GAN Loss 训练。
第 2 个区别是:引入了一个额外的 high-resolution latent adaptation 阶段 (图 6,Phase 2) 来调整中间层 (即 Encoder 的头层和 Decoder 输入层),以适应潜在空间以减轻泛化性惩罚。作者发现只有调整中间层足以解决这个问题,同时训练成本低于高分辨率完整训练 (内存成本:153.98 GB → 67.81 GB)。
简单来讲,为了缓解高空间压缩比 Autoencoder 的泛化性惩罚,应该对高分辨率图像进行训练。但是实际做不了,因为训练成本高且 GAN Loss 不稳定。所以DC-AE 贡献 2:Decoupled High-Resolution Adaptation,把高分辨率和低分辨率解耦开:
训练高分辨率的 Phase 2,不使用 GAN Loss,同时只微调一点点模型。
训练低分辨率的 Phase 3,使用 GAN Loss,同时也是去只微调一点点模型。

1.5 DC-AE 与 Latent Diffusion Model 的结合
对于 Diffusion Transformer 而言,增加 Patch Size pp 是减少 token 数量的常用方法。这相当于首先应用 Space-to-Channel 操作减少 spatial size pp 倍,然后使用 Patch Size 为 1 的 Transformer 模型。
由于低空间压缩 Autoencoder (例如 f8) 与 Space-to-Channel 操作相结合也可以实现高空间压缩比,一个自然的问题是如何将其与直接到达目标空间压缩比与 DC-AE 进行比较。
图 8 展示了实验结果。可以看到,直接使用 Autoencoder 达到目标空间压缩比在所有设置中都给出了最好的结果。此外,作者还发现,将空间压缩比从 Diffusion 模型转移到 Autoencoder 始终会带来更好的 FID。
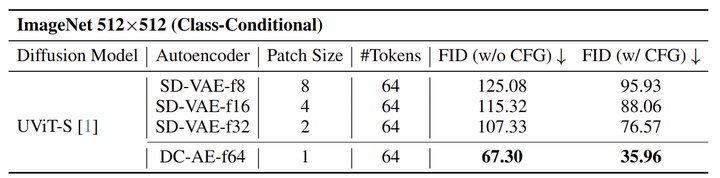
1.6 实验结果
作者使用以下数据集的混合来训练自动编码器 (Baseline 和 DC-AE),包含 ImageNet、SAM、MapillaryVistas 和 FFHQ。
对于图像生成任务,作者将 Autoencoder 应用于包括 DiT 和 U-ViT 在内的 Diffusion Transformer 模型。作者遵循与原始论文相同的设置。此外,通过将 U-ViT 与 SiT sampler 相结合来构建 U-SiT。作者考虑 3 种不同分辨率的设置,包括 ImageNet 用于 512×512 生成,FFHQ 和 MJHQ 用于 1024×1024 生成,MapillaryVistas 用于 2048×2048 生成。
图 8 总结了 DC-AE 和 SD-VAE 在各种设置下的结果 ( ff 表示空间压缩比, cc 表示 latent channel 数)。DC-AE 在所有情况下都比 SD-VAE 提供了显着的重建精度改进。
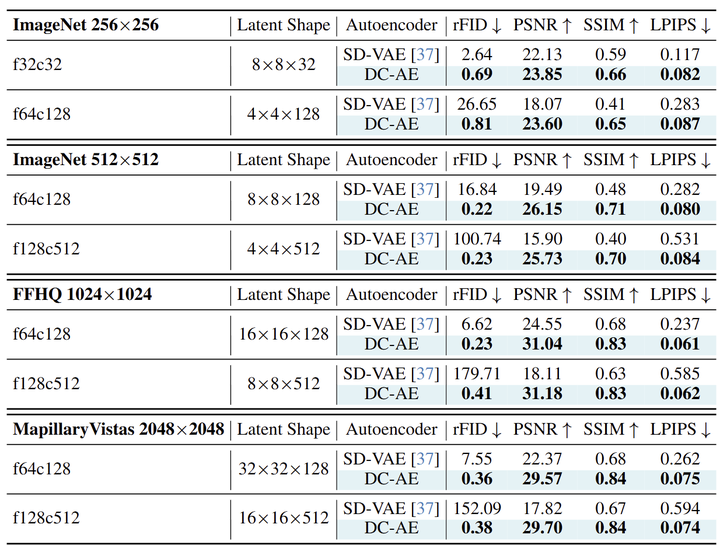
作者还将 DC-AE 与广泛使用的 SD-VAE-f8 Autoencoder 在各种 DiT 模型上进行了比较。DC-AE 总是使用 1 的Patch Size (表示为 p1)。SD-VAE-f8 遵循常见的设置并使用 2 或 4 的 Patch Size (表示为 p2, p4)。结果总结在图 10 和 11 中。
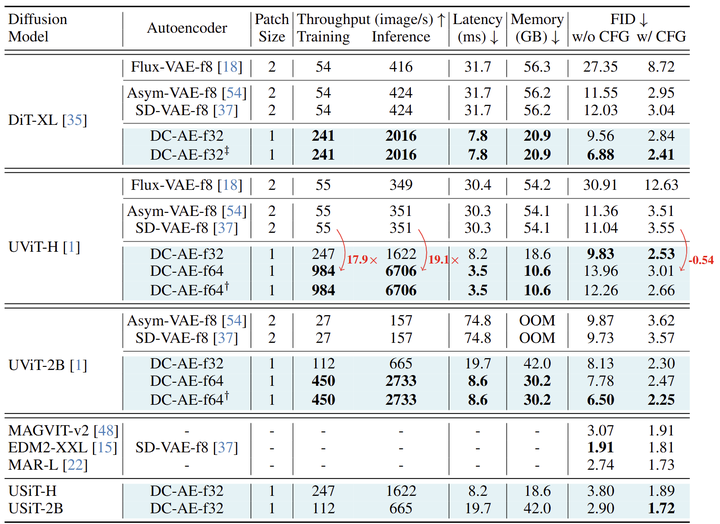
ImageNet 512×512 图像生成
如图 10 所示,DC-AE-f32p1 始终提供比 SD-VAE-f8p2 更好的 FID。此外,它比 SD-VAE-f8p2 的 token 减少了 4 倍,导致 DIT-XL 的 H100 训练吞吐量提高了 4.5 倍,H100 推理吞吐量提高了 4.8 倍。
将 DC-AE 应用于 U-SiT 模型获得了极具竞争力的结果。例如,DC-AE-f32+USiT-2B 在 ImageNet 512×512 上实现了 1.72 FID,优于 SOTA 扩散模型 EDM2-XXL 和 SOTA 自回归图像生成模型 (MAGVIT-v2 和 MAR-L)。
文生图
图 11 报告了文生图实验结果。所有模型都从头开始训练 100K iterations。与之前的情况类似,可以观察到 DC-AE-f32p1 比 SD-VAE-f8p2 提供了更好的 FID 和更好的 CLIP score。图 12 展示了扩散模型与 DC-AE 生成的样本,显示了合成高质量图像的能力,同时比以前的模型更高效。


参考
-
^Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation -
^Highresolution image synthesis with latent diffusion models
(文:极市干货)