

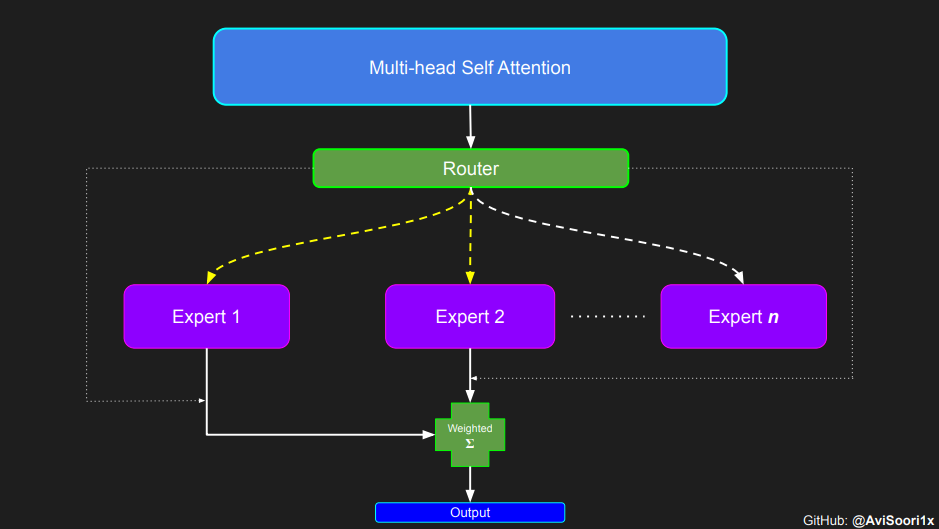
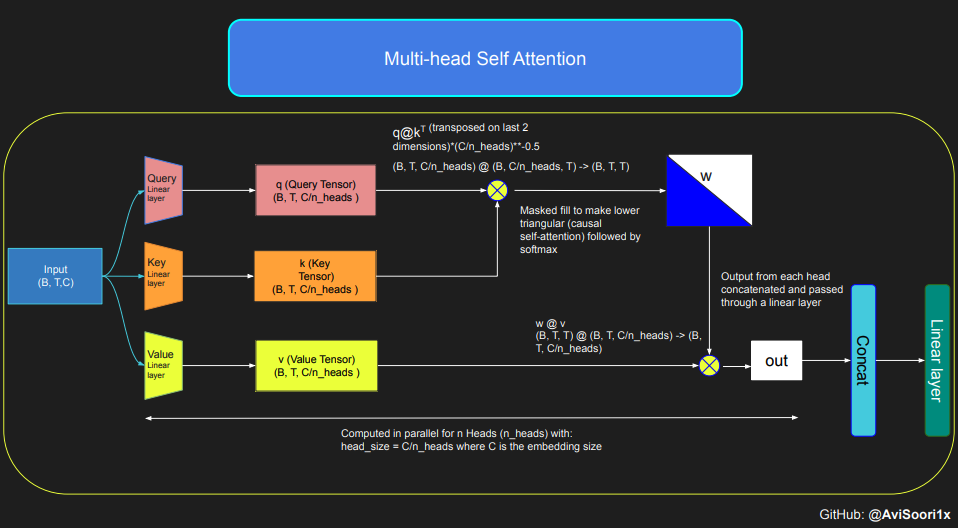
huggingface的一篇博客,带你从零开始实现一个稀疏专家混合语言模型(MoE模型)。本项目灵感来源于 Andrej Karpathy 的项目“makemore”。文章通过逐步解析代码,展示了如何构建自注意力机制、专家模块、Top-k 门控机制以及稀疏 MoE 模块,并将其整合为一个完整的语言模型。阅读本文,可以深入了解稀疏 MoE 架构的实现细节、训练过程以及如何通过代码实现高效的模型训练和推理。
参考文献:
[1] https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch
(文:NLP工程化)