
“ 文本序列化是自然语言处理任务的前置条件,而文本序列化需要经过分词,构建词汇表和序列化的几个步骤”
在神经网络或者说在机器学习领域中,数据主要以向量的形式存在,表现形式为多维矩阵;但怎么把现实世界中的数据输入到神经网络中是机器学习的一个前提。
而现实世界中的数据格式虽然多种多样,但事实上无非以下几种主要模态:
-
文字
-
图片
-
视频
但我们也知道,计算机只认识数字,而不认识文字和图片;因此,就需要把这些数据转换为计算机能够识别的格式;而在神经网络模型中就是怎么把这些数据转换为向量的格式。
简单来说,就是把现实世界中的数据转化为用多维矩阵进行表示的过程。图片是由多个像素点组成,因此天生的就可以用矩阵表示;但文字却不同,处理起来要复杂得多。至于视频,就是动起来的多张图片。
文本处理
在自然语言处理任务中,要想把文本数据输入到神经网络中,需要经过大概以下几个步骤:
-
分词
-
构建词汇表
-
文本序列化
但为什么自然语言处理需要经过以下几个步骤? 下面来介绍一下每个步骤的作用:
分词
在自然语言体系中,语义是以词或句子的形态体现的;因此,我们就需要去理解词或句子的意思;但众所周知的是,以我们汉语为例常用的词和字就几千个;而我们生活中绝大部分的语义都是由重复的字和词组成的。
因此,从效率的角度来讲,我们不可能把每个句子的语义都记下来;我们需要的是找到其中常用的字和词,然后通过类似排列组合的方式组合成一个个句子。

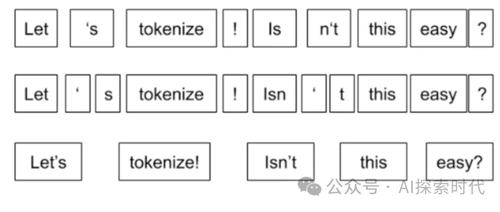
所以,自然语言处理的第一步就是分词;也就是说通过某种方式把句子中相同的字或词挑出来,组成一个字词列表。而常用的分词技术根据不同的语言又有不同的实现方式;比如说在英语体系中,很多时候每个单词就表示单独的意思;因此最简单的分词方式就是把每个不同的单词都找出来。
但在汉语言中,由于存在多音字,成语等具有复杂语言的形态;因此,汉语分词就不能使用找不同字的形式。
因此,分词的难点是怎么对文本数据进行拆分,但又不会影响到词语本身对意思。
词汇表
理解了什么是分词,以及为什么要分词,那么再理解词汇表就很简单了;对句子进行分词之后,就获取到了一个字和词的列表;因此就可以根据这个列表来构建词汇表,变成让计算机可以处理的数字格式。
学过计算机原理的应该都知道,计算机无法直接处理文字,因此文字在计算机中是通过编码的方式来实现的;比如说大名鼎鼎的ASCII码表,就是用八位二进制表示的。

而ASCII码表本质上就是一个字典结构,即使用K-V的形式来表示字符;需要计算机处理时就使用二进制表示,需要现实给人看时就使用字符表示;而词汇表就是类似ASCII码表的形式,把字或词作为K,把数字作为V。
这样一个数字就可以代表一个字或词;这样就可以让计算机处理。
在词汇表中有两个比较特殊的词汇,那就是UNK和PAD;我们知道常用的汉字只有几千个,但实际上的汉字有上万个;因此,我们根据文本数据的内容,可能并不能获取到所有的汉字;因此遇到“没见过”的汉字该怎么办呢,这时就使用UNK来表示。
而在矩阵计算中,需要的是相同的矩阵形式;比如说需要5*5的固定矩阵;但在自然语言中,每个句子的长度都不一样;短的可能就一两个字,长的可能有几十个字;这时变换的矩阵维度就不在相同。
dict = { "UNK_TAG": 0, "PAD_TAG": 1}因此,就可以使用PAD对文字比较少的句子进行补充;而对文字比较长的句子进行截取。
文本序列化
在经过分词和构建词汇表之后,就可以对文本进行序列化;在自然语言处理任务中,文本需要转换为编码的数字进行表示;也就是把文字变成数字表示。
dict_1 = { "UNK_TAG": 0, "PAD_TAG": 1}dict_2 = { 0: "UNK_TAG", 1: "PAD_TAG"}
所以就有了一个从文字变成数字和从数字变成文字的过程;本质上其实就是在词汇表中,根据文本获取其编码的数字,以及根据编码的数字获取文字。
文本序列化最重要的一步,就是把数字表示的句子转换成向量表示,也就是多维矩阵;而这就需要通过one-hot或者word embedding的方式来进行序列化。
但是在使用word embedding之前,需要把句子的数字列表转换为tensor格式。
# 将句子列表转换为tensorsentences_tensor = torch.tensor(sentences, dtype=torch.long)# 定义 Embedding 层embedding = nn.Embedding(vocab_size, embedding_dim)# 通过 Embedding 层embedded_sentences = embedding(sentences_tensor)
(文:AI探索时代)