


极市导读
谁说归一化层是不可或缺的! >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 DyT:取代 Transformer 归一化层
(来自 Meta 明星团队:Xinlei Chen, Kaiming, LeCun, Zhuang Liu)
1 DyT 论文解读
1.1 DyT 论文背景
1.2 归一化层
1.3 归一化层的作用
1.4 Dynamic Tanh (DyT) 操作
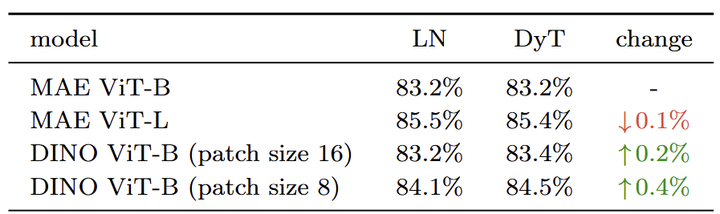
1.5 实验:视觉监督学习
1.6 实验:视觉自监督学习
1.7 实验:扩散模型
1.8 实验:大语言模型
1.9 DyT 分析性实验
太长不看版
本文发现,Transformer 中常用的归一化层 (Normalization layer) 可以使用一种极简的技术来替代,即本文提出的 Dynamic Tanh (DyT) 函数。这是一种 element-wise 的操作:
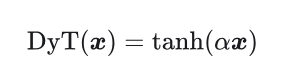
DyT 函数可以直接替代归一化层。
DyT 函数的提出来自这样一个观察,即:Transformer 中的归一化层的输入-输出映射,总是呈现出 S 形。
DyT 函数使得 Transformer 的性能接近或者超过了归一化层。实验包括:视觉识别任务 (ViT, ConvNeXt),生成任务 (DiT),自监督学习 (MAE, DINO),LLM (LLaMA) 等等。
这个发现算得上是对传统观点,即:”归一化层在现代神经网络中不可或缺的” 的挑战,为深入了解归一化层在网络中的作用提供了一个新的视角。
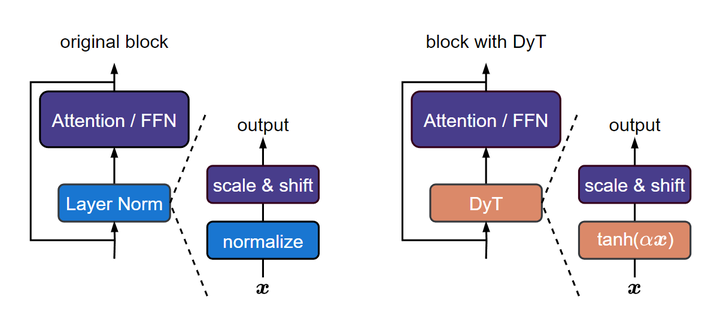
图1:左:原始 Transformer Block;右:使用 Dynamic Tanh (DyT) 的 Transformer Block
1 DyT:取代 Transformer 归一化层
论文名称:Transformers without Normalization (CVPR 2025)
论文地址:
http://arxiv.org/pdf/2503.10622
项目主页:
http://jiachenzhu.github.io/DyT
1.1 DyT 论文背景
过去的十年中,Normalization 层成为现代神经网络最基本的组成部分之一。一开始可以追溯到 Batch Normalization,BN 使得视觉识别模型收敛更快,更好。自 BN 之后,领域提出了许多归一化层的变体,诸如 Layer Normalization,Instance Normalization,Group Normalization等等。今天,几乎所有现代网络都使用归一化层,尤其是 Transformer 几乎都使用 Layer Normalization。
Normalization 层的成功源自其在多数任务中的效果很好。除了效果以外,它还可以加速收敛,稳定训练。随着神经网络变得越来越广泛和更深,Normalization 层的必要性就变得更加关键了。因此传统观念认为,神经网络的有效训练,归一化层是关键。近年来,新的架构通过聚焦于替换卷积或者注意力,但是无一例外地保留了归一化层,也证明了这一点。
本文挑战了 “神经网络的有效训练,归一化层是不可或缺的” 的传统观点,通过提出的 Dynamic Tanh (DyT) 来取代 Normalization 层。DyT 是一种 element-wise 的操作: 。
DyT 的提出是观察到 LN 层的输入-输出映射为 S 形状的,tanh-like 曲线。因此,目的是通过 \alpha 学习适当的比例因子并通过有界的 tanh 函数压缩极值,来模拟 LN 的行为。
DyT 与归一化层不同的地方在于,不需要计算激活值得统计信息。
初步测量表明 DyT 可以提高模型的训练和推理速度,使其成为高效神经网络架构的候选。
1.2 归一化层
给定一个形状为 的输入 ,其中 是标记的数量,输出通常计算为:
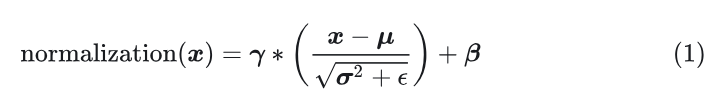
其中,
下面是不同类型归一化层的做法:
1) Batch Normalization:计算批处理维度和 token 维度的均值和方差:
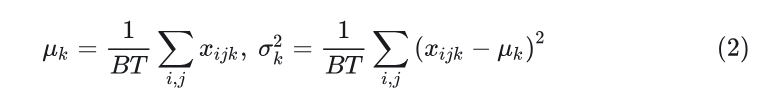
2) Layer Normalization:计算每个样本中的每个 token 的均值和方差:

3) RMSNorm 是 LN 简化版,mean-centering 这一步省了:
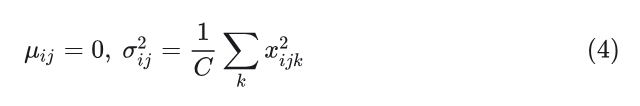
RMSNorm 在现代大模型上用的非常多,比如:T5, LLaMA, Mistral, Qwen, InternLM 以及 DeepSeek。
1.3 归一化层的作用
作者分析了 3 个模型:ImageNet-1K 上训练的 Vision Transformer model (ViT-B),LibriSpeech 上训练的 wav2vec 2.0 Large Transformer model,ImageNet-1K 上训练的 Diffusion Transformer (DiT-XL)。
作者对这 3 个网络,采样小批量样本,前向传递。然后,测量输入-输出映射 (仿射变换之前测量归一化层的输入和输出),直接可视化输入-输出之间的关系。如下图 2 所示。
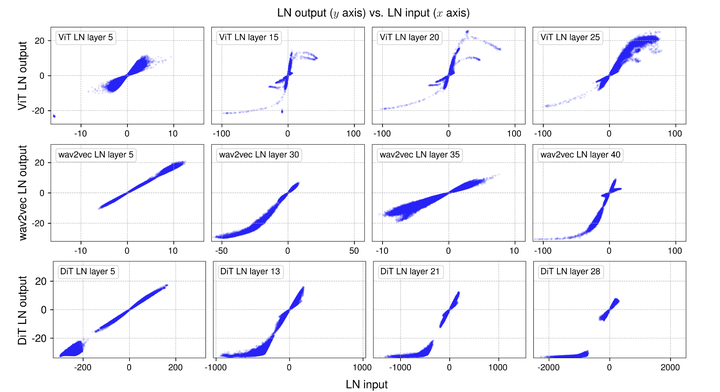
S 形状的 tanh-like 曲线
对于所有 3 个模型,在早期的 LN 层中,这种输入输出关系大多是线性的,类似于 x-y 图中的直线。
在更深的层中,曲线变为了 S 形的 tanh-like 曲线,如图 3 所示。
乍一想,LN 只是对输入做了线性变换。LN 以逐 token 的方式作归一化,每个 token 有不同均值和标准差,因此这也可能不是对输入张量作纯线性变换的原因。尽管如此,实际的非线性变换与 tanh 函数高度相似这一点,仍然令人惊讶。
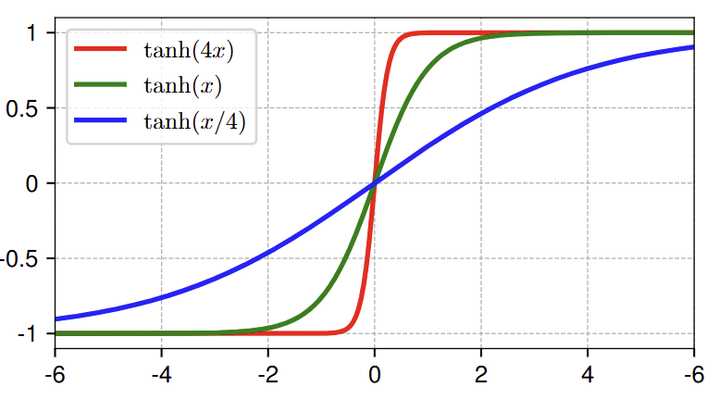
LN 的 “极端区” 是区分它与 affine transformation 的关键
这种 S 形状的曲线中,作者观察到,大多数的点 (约占 99%) 都集中在中心的 “线性区” 中,其他的点超出这个范围,在 “极端区” 中。归一化层的主要效果就是将主要特征压缩到不太极端的范围里。这个 “极端区” 才是 affine transformation 无法逼近的地方。作者认为:归一化层相比于 affine transformation 不可或缺的原因,就在于其还存在一段非线性的 “极端区”,其对异常值特征会带来挤压效应。
LN 层是如何对每个 token 执行线性变换,同时又以非线性的方式压缩极值的?
从图 4 左侧 2 图 (每个 token 用一种颜色) 中可以观察到,每个 token 都形成一条直线。但是由于每个 token 数值方差不同,所以最终范围不同。输入值范围比较小的特征的方差也小,所以输出之后的范围就扩大了很多;输入值范围比较大的特征的方差也大,所以输出之后的范围就没扩大多少。把这些点收集在一起,就形成 S 型曲线。
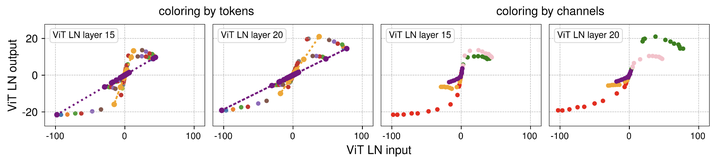
从图 4 右侧 2 图 (每个 channel 用一种颜色) 中可以观察到,不同的 channel 往往具有不同的输入范围,只有少数 channel (例如,红色、绿色和粉色) 表现出较大的极值。
1.4 Dynamic Tanh (DyT) 操作
DyT 的定义:
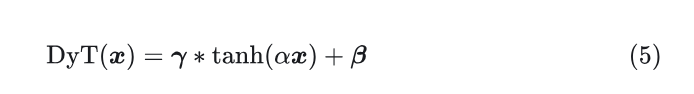
其中, 是一个可学习的标量参数,允许根据其范围以不同的方式缩放输入。伪代码如下:
# input x has the shape of [B, T, C]
# B: batch size, T: tokens, C: dimension
class DyT(Module):
def __init__(self, C, init_(@$bm alpha$@)):
super().__init__()
self.α = Parameter(ones(1) * init_(α))
self.γ = Parameter(ones(C))
self.β = Parameter(zeros(C))
def forward(self, x):
x = tanh(self.α* x)
return self.γ * x + self.β
初始化: 简单初始化 为全 1 的向量,初始化 为全 0 的向量,对于 scaler 参数 ,除了 LLM训练,默认初始化 0.5 通常就足够了。
注意: DyT 不是一种新的 Normalization 层,因为它在前向传递期间无需计算统计数据,直接对向量中逐元素操作。但它保留了对 “极端区” 数值的 “挤压” 效应,对 “线性区” 的输入做线性变换。
1.5 实验:视觉监督学习
模型:ViT, ConvNeXt
数据集:ImageNet-1K
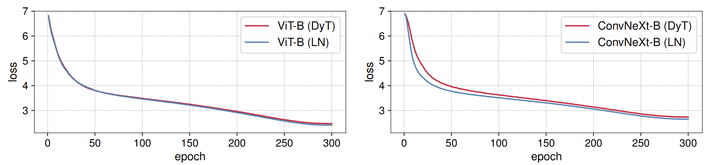

DyT 在不同架构和尺寸上的表现略好于 LN。图 5 的 training loss 曲线也表明了 DyT 和基于 LN 的模型的收敛行为是高度对齐的。
1.6 实验:视觉自监督学习
模型:MAE, DINO
数据集:ImageNet-1K
遵循标准的自监督学习方式,首先在 ImageNet-1K 上预训练模型,不使用任何标签。然后增加分类头,并按照有监督学习微调预训练模型,结果如图 7 所示。DyT 在自监督学习任务中始终与 LN 相当。
1.7 实验:扩散模型
模型:DiT
数据集:ImageNet-1K
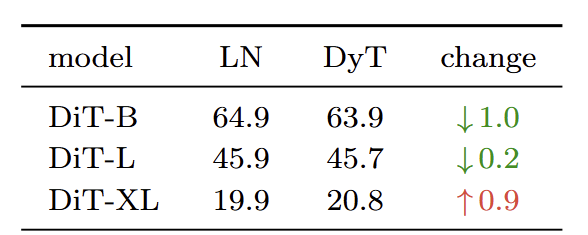
在 DiT 中,LN 层的 affine 参数在 DiT 中用于 class condition,因此作者保持这个参数。在 DiT 实验中只用 函数替换归一化操作。FID 分数结果如图 8 所示,DyT 比 LN 实现了相当或者更好的 FID 结果。
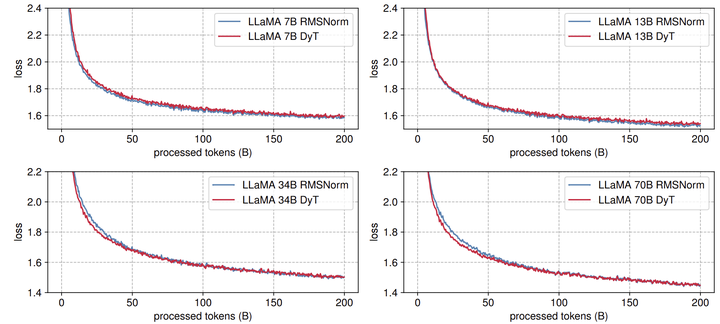
1.8 实验:大语言模型
模型:LLaMA 7B, 13B, 34B, 70B
数据集:The Pile dataset,200B tokens
LLaMA 使用的是 RMSNorm。实验采用 OpenLLaMA 框架,lm-eval 做评估。如图 9 所示,DyT 在所有 4 种模型大小上的表现与 RMSNorm 相当。图 10 展示了损失曲线,展示了所有模型大小的类似趋势,训练损失在整个训练过程中紧密对齐。

1.9 DyT 分析性实验
DyT 最关心的效率分析
作者首先对比了 DyT 与 RMSNorm 的效率,看下 DyT 是不是可以加速。
作者使用 RMSNorm 或 DyT 对 LLAMA 7B 模型进行基准测试,通过使用 4096 个 token 的单个序列测量 100 次 forward (推理) 和 100 次 backward (训练) 花费的时间。图 11 报告了在 BF16 精度的 NVIDIA H100 上运行时所有 RMSNorm 或 DyT 层以及整个模型所需的时间。与 RMSNorm 层相比,DyT 层显著降低了计算时间,在 FP32 精度下观察到了类似的趋势。DyT 可能更适合面向效率的网络设计。

DyT 的两部分: 和
替换和删除 的影响
作者用一些替代的函数(hardtanh 和 sigmoid,如图 12 所示)来替换 DyT 层中的 tanh,同时保持 不变。此外也通过将 tanh 替换为 identity 函数来评估完全去除的影响,同时仍然保持 不变。
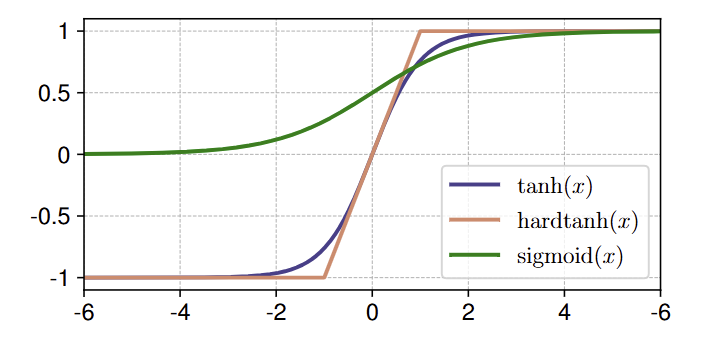
如图 13 所示,压缩函数对于稳定训练至关重要。使用 identity 函数会导致训练不稳定,压缩函数可以实现稳定的训练。在压缩函数中, 表现最好。作者认为可能是由于它的平滑度和 zero-center 属性。

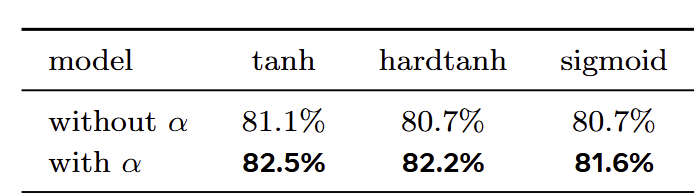
去掉 的影响
接下来,作者评估了在保留压缩函数 (tanh、hardtanh 和 sigmoid) 的同时去除可学习的 的影响。如图 14 所示,去除 会导致所有压缩函数的性能下降,突出其在整体模型性能中的重要作用。
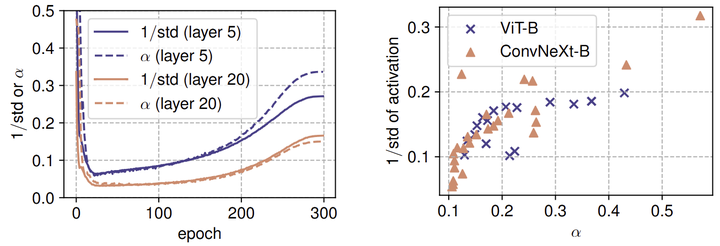
值的影响
在训练期间, 密切跟踪激活的 std 。如图 15 左侧面板所示, 首先减少,然后在训练过程中增加,但总是随着输入激活的标准差而持续波动。这体现出 可以把激活值维持在适当范围内的作用,从而稳定有效的训练。
在训练之后,作者进一步分析表明,网络中 的最终值与输入激活的 之间有很强的相关性。如图 8 右侧面板所示,较高的 值通常对应于较大的 值,反之亦然。
这两种分析表明,通过学习的 可以近似输入激活的 std,来部分作为归一化机制。与对每个 token 进行归一化的 LN 不同, 对整个输入激活一起做归一化。因此,仅 不能以非线性方式抑制极值。

(文:极市干货)