

这可能只是一个谣言!

最近,一则劲爆消息刷屏:据说DeepSeek R2在ARC-AGI测试中得分高达90%!
如果属实,这将是AI领域的重大突破,但问题是——这极可能只是一则未经证实的谣言。
事实上,我找了一圈,未能找到的任何相关的公开或权威信息。目前DeepSeek R2 甚至尚未正式发布,任何经过验证的测试分数则更是无从谈起了。
“谣言”从何而来?
这一消息最初由Twitter用户Smoke-away(@SmokeAwayyy)发布:
传言说DeepSeek R2在ARC-AGI上得分90%。
随后Chubby♨️(@kimmonismus)转发并评论道:
如果这是真的,我看不出封闭源码的AI如何能赢得这场AI竞赛。
然而,多位网友立即对此表示怀疑。
JendryDomingo(@JendryDomingo)给出了source 说明:
来源:我昨晚梦到的

更令人怀疑的是,这位传言发布者Smoke-away此前曾预测DeepSeek R2会在3月17日发布,但这一预测已经落空。
国内有许多自媒体,甚至一些小地方官媒也纷纷跟风转发。

而作为近期最受瞩目的中国AI企业,DeepSeek 此前也出面澄清:只有@deepseek_ai才是其唯一官方账号。
这些冒牌货都有着显著的特征:
-
使用相同的头像
-
使用相似的名字
-
谎称代表DeepSeek

JendryDomingo(@JendryDomingo) 则指出一切最好以官方消息为准:
R2计划于5月发布,据报道将带来更强的编程能力,以及对英语以外语言的推理支持。DeepSeek 公司已通过其企业咨询用户账号正式确认,有关提前发布的传言是虚假的。
什么是ARC-AGI?
虽然极可能是谣言,但今天也就顺便来说说这个ARC-AGI——它是什么,以及为何它会如此重要?
为什么一个小小谣言能带来如何大的传播量?
ARC-AGI(Abstraction and Reasoning Corpus for Artificial General Intelligence)是由François Chollet(Keras创建者)开发的基准测试,旨在测量AI在面对全新问题时的适应能力和推理能力。
与仅测量特定技能的基准不同,ARC-AGI专门设计用来比较人工智能与人类智能,测试AI系统获取新技能的效率,而非仅仅测试已习得的技能。
这个测试涉及一系列视觉谜题,要求理解基本概念如物体、边界和空间关系。
别说,还挺有点公务员考题那味?(不过没那么难)
虽然人类可以轻松解决这些谜题,但现有AI系统通常难以应对。ARC被认为是评估AI能力最具挑战性的指标之一。
简单的说,就是——
人能轻松搞定,但AI 不行。
更重要的是,ARC-AGI被设计成无法通过训练模型处理数百万个示例来“作弊”。这个基准由一个公共训练集(400个简单示例)和一个更具挑战性的公共评估集(400个谜题)组成,以评估AI系统的泛化能力。
ARC-AGI 的题目都什么样
说到这里,你可能还是对ARC-AGI 没什么概念。那我们就来看看几类典型的ARC-AGI测试题目都什么样:
类目1:模式识别与变换
这类题目要求识别输入网格中的视觉模式并应用特定变换规则。例如在这个任务中,需要识别彩色块的分布规律,然后将其转换为新的排列形式。
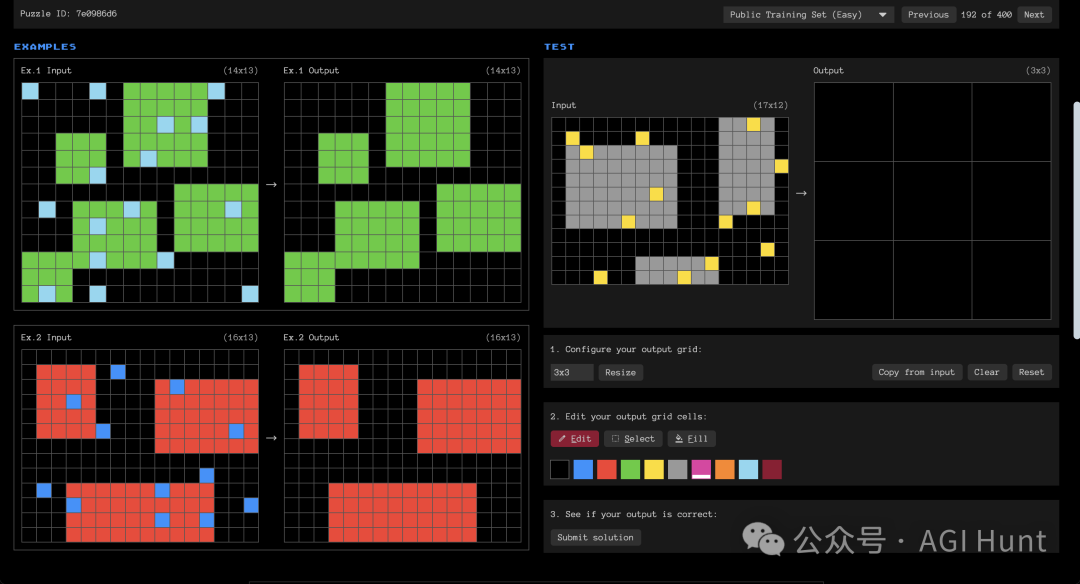
https://arcprize.org/play?task=7e0986d6
以上图为例,题目在左侧给出了2个input 和output 的示例,要求根据规律给出右侧input 下的output 是什么。
在答题时,可以先点一下“Copy from input”或更改输出答案的size 后后,再使用2 中的颜色格对右上方的output 进行颜色更改为你的答案。
然后点击“Submit solution”就可以看到结果是否正确了。
比如我第一次不加思索的结果 :
:
类目2:物体识别与抽象
这类题目需要将网格中的元素识别为”物体”,并进行操作。例如在这个任务中,可能需要将不同颜色的方块按特定规则分组或重组。
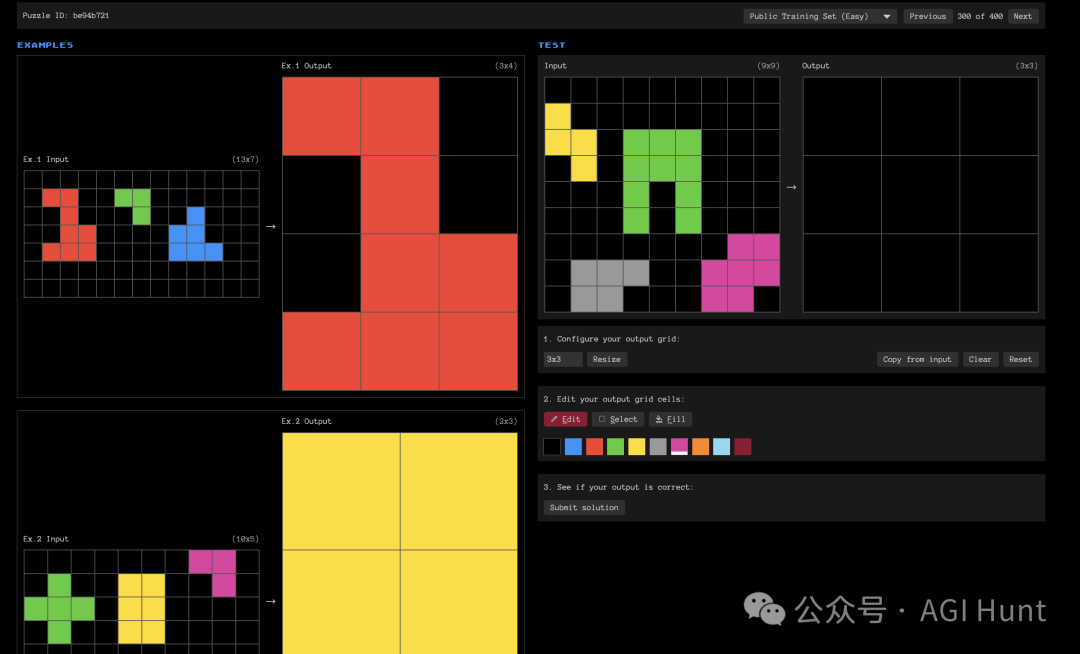
https://arcprize.org/play?task=be94b721
有些复杂的题,会有多个示例(比如上题共有4个示例,注意往下翻,别像我看漏了……)。
我试着回答了一些题,结果……
作为一个自以为聪明过人从小被称为理科小天才的自负型选手,我忍不住在ARC-AGI官网上尝试了几道题目,结果……
以下面这道图案变换题小试身手(https://arcprize.org/play?task=00576224):
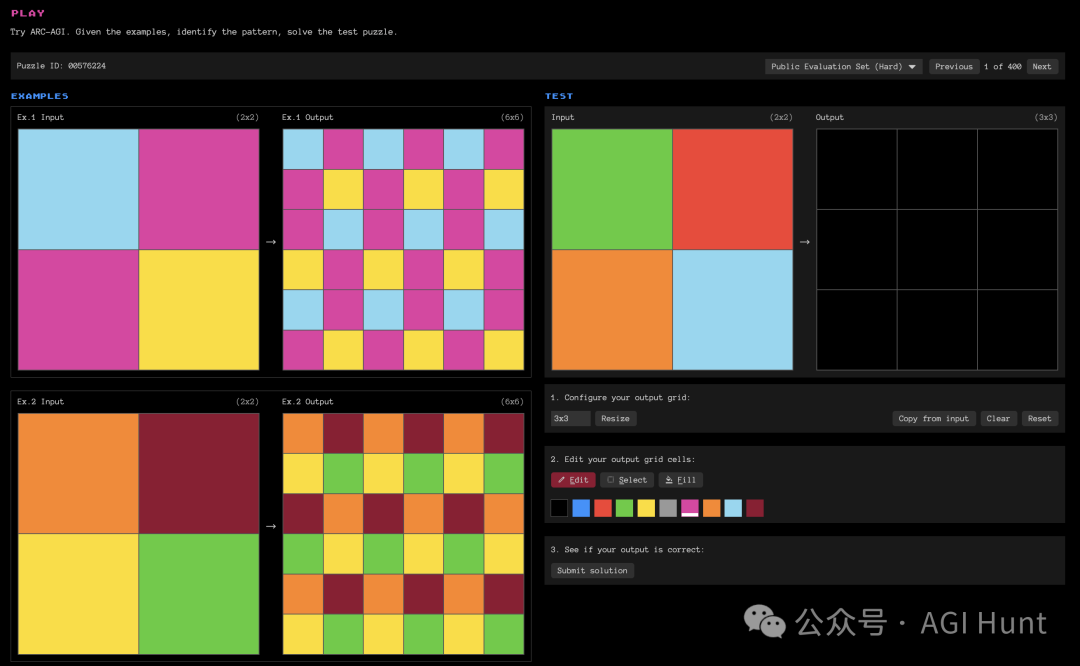
输入是一个含有几个彩色方块的网格,输出则是经过某种规则变换后的整齐方块阵列。
乍看之下,可以很快就能判断出规则是将输入在横向和纵向分别重复三遍,但第二行要进行水平翻转。
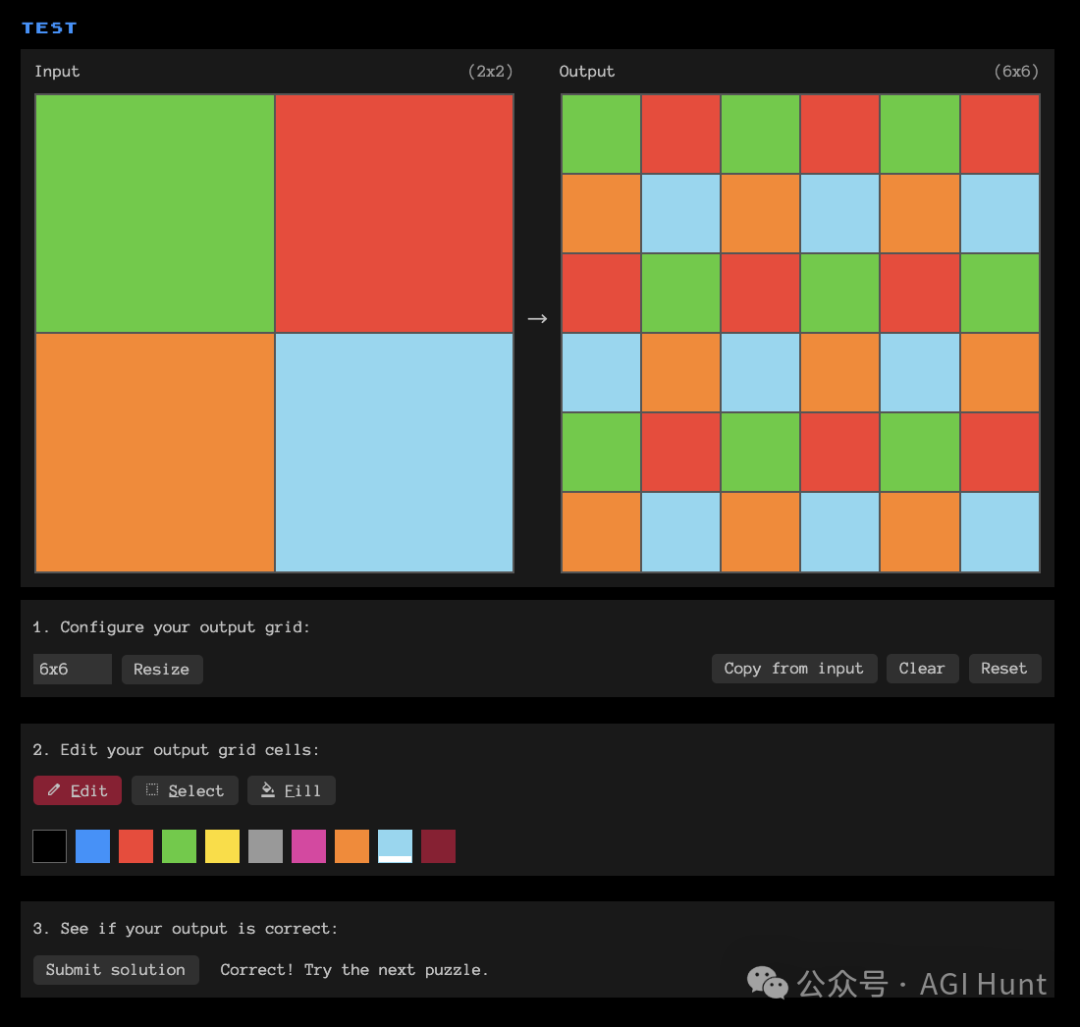
倒是轻松拿捏,搞定!
(得吐槽一下,这些题对色盲选手而言太不友好了。。
就不举例更多题目了,因为,太简单了!
(只要认真审题 & 别大意 & 别太笨)
而回归ARC-AGI 的初衷,它不仅仅是简单的图像识别或模式匹配,而是在测试一种更为核心的智能能力——在极少示例的情况下进行抽象推理并应用。
这些人类能够轻松搞定的,却恰恰是当前AI系统最为欠缺的能力,因此也才成为评判通用人工智能进展的真正标尺。
顶尖AI模型在ARC-AGI上的真实表现
而目前各大顶尖AI模型在ARC-AGI上的真实得分,离传言中的90%还有多少差距呢?
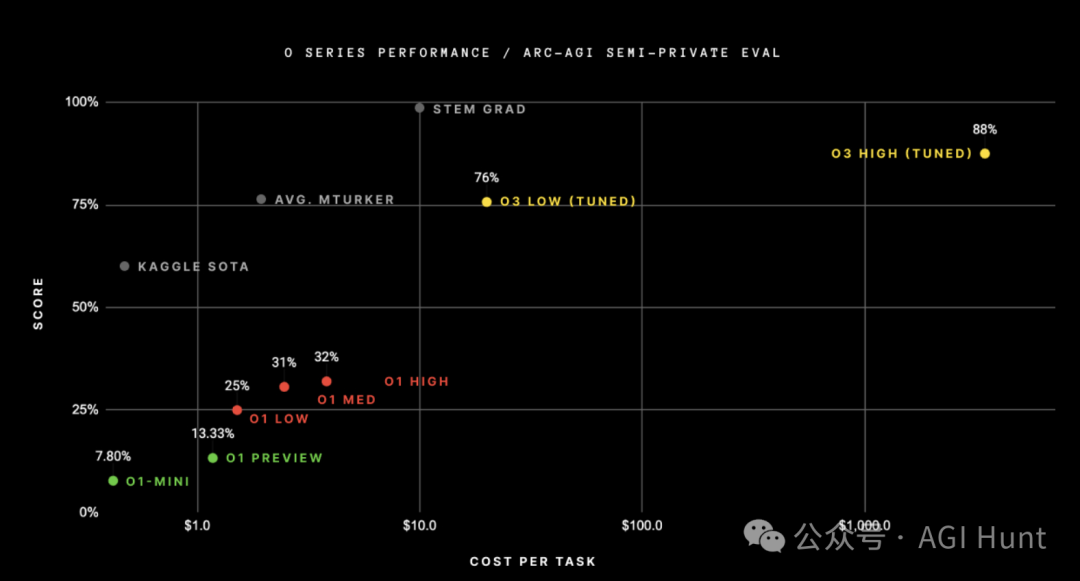
我整理了一下:
-
OpenAI的o3:在低计算模式下获得了75.7%的成绩,在高计算模式下达到了87.5%,这被视为AI推理能力的突破性进展。
-
OpenAI的o1:在ARC-AGI的高计算模式下得分约30-32%。
-
DeepSeek R1:DeepSeek R1家族的得分约为15-20%。
-
GPT-4o:得分约为5%,被视为纯LLM扩展的巅峰。
ARC-AGI-1基准测试花了4年才从2020年GPT-3的0%提高到2024年GPT-4o的5%。
因此,话说回来,声称DeepSeek R2 在如此短时间内达到90%的消息,虽然值得怀疑,倒也并非完全不可能。
这种对人类来说”轻松拿捏“的题目,却是当前AI系统的噩梦。
据说,普通人类在短暂思考后就能解决这类问题——
根据纽约大学2024年的研究,98.7%的ARC任务至少能被一位普通测试者解决,人类平均正确率在公共训练集上达到76.2%。
——即使是最强大的AI模型也难以在如此有限的示例中推断出抽象规则并应用。这种将输入在横纵方向重复但添加特定变换规则的任务,需要AI具备对模式的抽象理解和灵活应用能力。
这也正是ARC-AGI测试的核心意义——它揭示了人类智能与当前AI之间的根本差距。虽然如OpenAI的o3等顶级模型已取得显著进步,但这种差距仍然存在。人类可以轻松识别模式并推断变换规则,而AI则需要大量示例和复杂的推理过程才能达到相似的效果。
不得不说,花费巨资打造的顶尖的模型其实还干不过中国一个普通的公务员,甚至是落榜生啊!
也难怪LeCun 对LLM 能达到AGI 一直持喷击态度。
Yann LeCun:LLM 绝无可能实现AGI!
得分90%意味着什么?
话说回来,如果一个模型真能在ARC-AGI上获得90%的分数,这将是什么概念?
ARC-AGI被视为通向AGI(通用人工智能)的“北极星”。
任何(开源)AI 系统都将展示出前所未有的适应性和推理能力,这将颠覆我们对AI 的能力认识。

而ARC-AGI的创建者François Chollet指出,即使是目前最先进的o3模型,在即将新推出的ARC-AGI-2基准测试中,其得分也可能降至30%以下,而一个聪明的人类仍能在没有任何训练的情况下达到95%以上。
这一点更凸显了90%分数的不可思议——简单来说,这将意味着AI 已极大地接近人类的适应性智能水平。
网友们怎么看?
对于这一传言,网友们的反应褒贬不一:
支持开源AI发展的声音:
munchonthenet(@munchonthenet)指出:
别忘了,DeepSeek原本只是个花费了OpenAI基础设施一小部分成本的副项目,却成功生产出了高质量产品。现在它受到重视,下一个版本可能会远超我们现在使用的任何模型。
NewAIWorld(@Newaiworld_)分享了更广泛的视角:
老实说,我已经不会再感到惊讶了。中国现在正在全力发展!很多迹象表明中国已在AI、先进机器人和其他技术领域取得领先地位。
深度技术分析:
JFPuget(@JFPuget) 从技术角度提出质疑:
在哪个ARC-AGI上?我敢打赌这不是在隐藏的测试数据上。恰恰是因为它是隐藏的,只在官方比赛中使用。
CNicholson1988(@CNicholson1988) 幽默地评论:
有个新传言说它得分110%。
DeepSeek与顶尖AI 模型的真实实力对比
虽然90%的分数极可能是谣言,但DeepSeek R1 确实就已展现出了其非凡的能力。
尽管资源相对有限,DeepSeek的模型在基准测试中的表现已几乎追平美国顶尖AI开发商的最新前沿模型。
据ArtificialAnalysis的独立AI分析排名,DeepSeek R1几乎与OpenAI的o1模型不相上下,并且已经超越了包括Google的Gemini 2.0 Flash、Anthropic的Claude 3.5 Sonnet、Meta的Llama 3.3-70B和OpenAI的GPT-4o在内的一系列其他模型。
在一些数学测试中,DeepSeek R1在AIME 2024数学基准测试中取得了79.8%的成功率,甚至超过了OpenAI的o1推理模型。
更值得注意的是,DeepSeek R1以每百万标记仅0.14美元的价格运行查询,相比OpenAI的7.50美元便宜了98%。
所以,这能信吗?
综合各方信息,这个90%的传言极不可信:
-
没有官方消息:DeepSeek官方尚未发布R2模型,更没有确认任何测试分数。
-
技术跨越过大:从R1的15-20%跳跃到R2的90%,技术提升幅度过于夸张。
-
历史参考:同一传言来源此前预测的R2发布日期已被证明是错误的。
-
专家质疑:多位AI领域专家对此表示怀疑,认为这种飞跃性进步短期内不太可能实现。
不管你信不信,你反正不信。
开源vs闭源,中国vs美国
不过,无论传言真假,中国AI公司的崛起已成事实。
DeepSeek R1在解决问题和技术推理任务方面表现尤为出色,在某些领域甚至超过了ChatGPT和Claude。
事实上,这场AI竞赛已不再仅由美国公司独霸。
虽然ChatGPT和Gemini主导着西方市场,但DeepSeek正作为一个强大的替代品崭露头角,具有明显的优势——尤其在成本效益和资源效率方面。
开源模式vs封闭源码模式的对决也在持续。
如Chubby♨️(@kimmonismus)所言,如果开源模型真能在性能上超越封闭源码模型,这将对整个AI产业格局产生深远影响。
虽为谣言,但仍期待!
(文:AGI Hunt)