


研究背景
研究问题:这篇文章要解决的问题是如何在统一框架下对基于图的检索增强生成(RAG)方法进行系统的比较和分析。具体来说,现有的基于图的 RAG 方法没有在同一实验设置下进行系统的比较。
研究难点:该问题的研究难点包括:缺乏统一的框架来抽象和比较各种基于图的 RAG 方法;现有工作主要关注整体性能评估,而非单个组件的性能;缺乏对各种方法在准确性和效率方面的全面比较。
相关工作:该问题的研究相关工作有:RAG 技术在各种领域的广泛应用,如医疗保健、金融和教育;已有的基于图的 RAG 方法,如 RAPTOR、KGP、HippoRAG 等,但这些方法缺乏系统的比较和分析。

论文标题:
In-depth Analysis of Graph-based RAG in a Unified Framework
论文地址:
https://arxiv.org/abs/2503.04338
代码地址:
https://github.com/JayLZhou/GraphRAG

研究方法
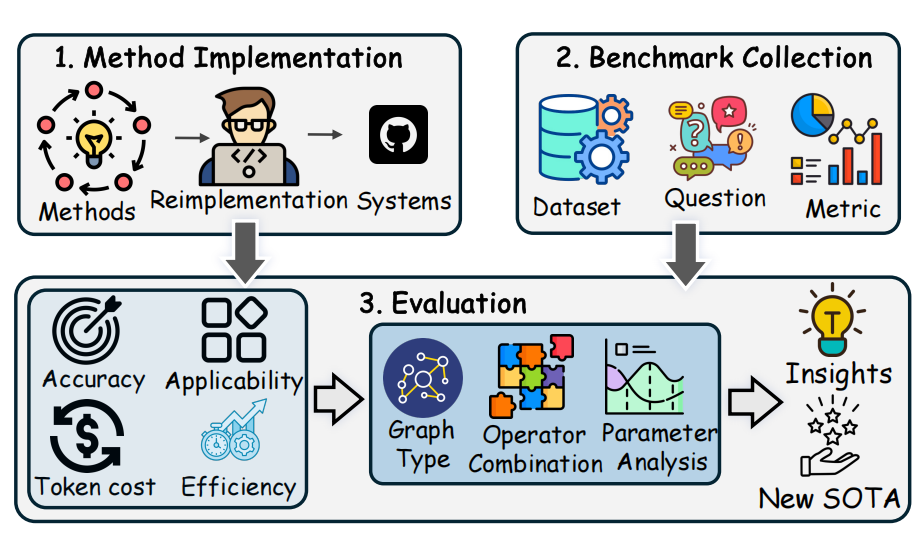
这篇论文提出了一个统一的框架,用于解决基于图的 RAG 方法的系统比较和分析问题。具体来说:
1. 图构建:首先,将大规模语料库分割成多个块,然后使用 LLM 或其他工具从这些块中提取节点和边,构建图。图的类型包括 passage graph、tree、knowledge graph、textual knowledge graph 和 rich knowledge graph。
2. 索引构建:为了支持高效的在线查询,构建索引以存储图中的实体或关系,并计算社区报告以实现高效的在线检索。索引类型包括节点索引、关系索引和社区索引。
3. 操作符配置:在统一框架下,任何现有的基于图的 RAG 方法都可以通过选择特定的操作符并将其组合来实现。操作符分为节点类型、关系类型、块类型、子图类型和社区类型。
4. 检索与生成:在检索与生成阶段,首先将用户输入的问题转换为检索原语,然后使用选定的操作符检索相关信息,并将其与问题一起输入 LLM 以生成答案。答案生成有两种范式:直接生成和 Map-Reduce。

实验设计
1. 数据集:实验使用了 11 个真实世界的数据集,包括特定问题和抽象问题的数据集。数据集如 MultihopQA、Quality、PopQA、MusiqueQA、HotpotQA、ALCE、Mix、MultihopSum、Agriculture、CS 和 Legal。
2. 评估指标:对于特定问题任务,使用准确率和召回率进行评估;对于抽象问题任务,使用包括全面性、多样性、赋能和总体质量在内的多维度比较方法进行评估。
3. 实现:所有算法在 Python 中实现,并使用提出的统一框架。实验在 350 集。数据集如 MultihopQA、Quality、PopQA、MusiqueQA、HotpotQA、ALCE、Mix、MultihopSum、Agriculture、CS 和 Legal。
4. 超参数设置:对于需要 top-k 选择的每种方法(例如块或实体),设置 k=4 以适应令牌长度限制。使用最先进的文本编码模型 BGE-M3 生成图的节点和关系的嵌入向量。

结果与分析
1. 特定问题任务的性能:RAG 技术显著提高了 LLM 在所有数据集上的性能,基于图的 RAG 方法通常比 Vanila RAG 具有更高的准确性。例如,在 Quality 数据集上,RAPTOR 相比 ZeroShot 提高了 53.80% 的准确性。然而,如果检索到的元素与给定问题不相关,RAG 可能会降低 LLM 的准确性。
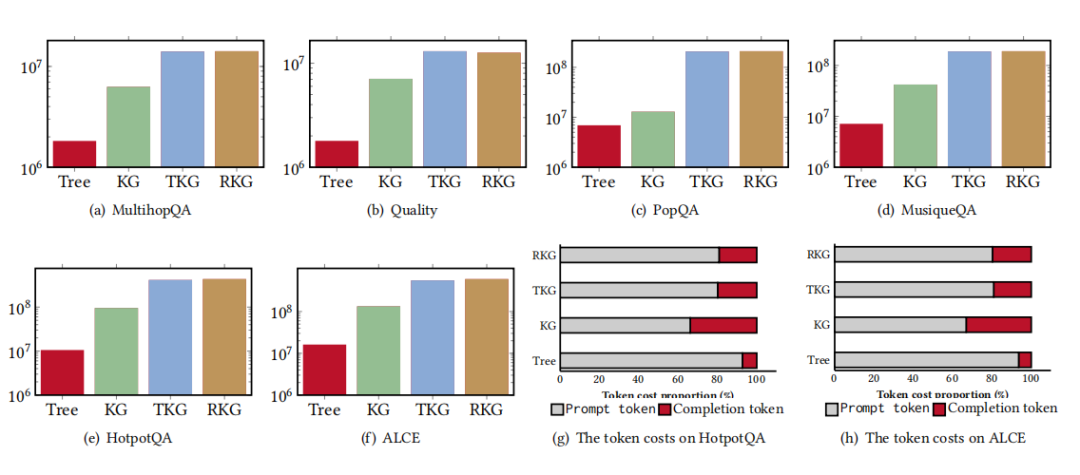
2. 图构建和索引构建的成本:构建树所需的令牌成本最低,而 TKG 和 RKG 的令牌成本最高。对于大型数据集,离线阶段的两种版本的 GraphRAG 通常比其他方法消耗更多的令牌。
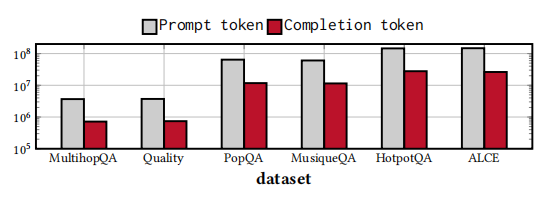
3. 生成成本:ZeroShot 和 VanilaRAG 在时间和令牌消耗方面是最具成本效益的方法。KGP 和 ToG 是最昂贵的方法,因为它们依赖于 LLM 进行信息检索。
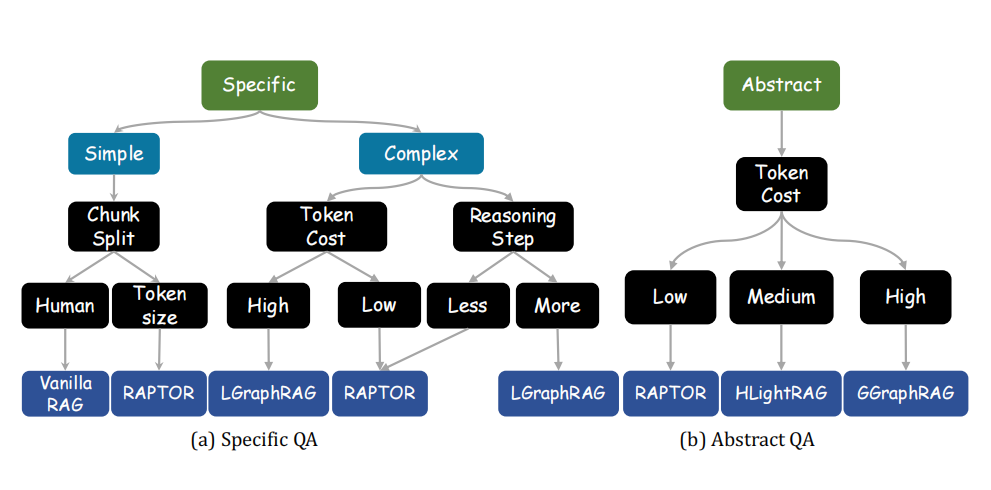
4. 复杂问题任务的新 SOTA 算法:基于上述分析,设计了新的 SOTA 方法 VGraphRAG,通过结合四种元素(实体、关系、社区和块)来有效地指导 LLM 生成准确的答案。在 ALCE 数据集上,VGraphRAG 在 STRREC、STREM 和 STRHIT 方面分别提高了 8.47%、13.18% 和 4.93%。
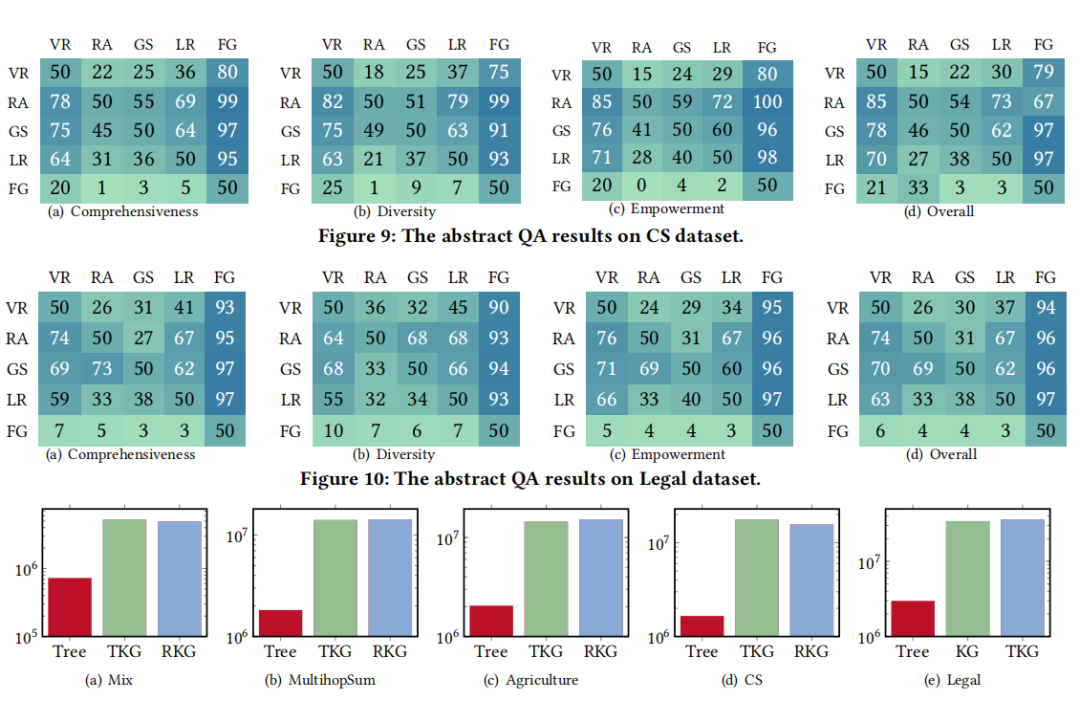
5. 抽象问题任务的性能:基于图的 RAG 方法通常优于 VanillaRAG,主要原因是它们有效地捕捉了块之间的相互连接。GGraphRAG 和 RAPTOR通常优于 HLightRAG 和 FastGraphRAG,因为它们将高层次的总结文本纳入提示中。
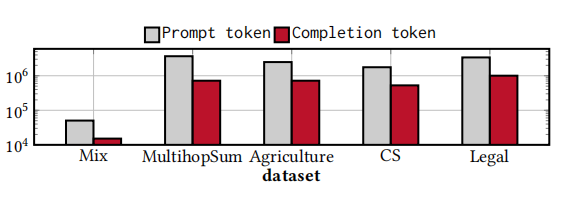
6. 新 SOTA 算法的成本效益:设计了一个成本效益更高的版本 CheapRAG,通过选择最有用的社区和块来显著减少令牌成本。在 MultihopSum 数据集上 CheapRAG 相比 GGraphRAG 减少了 100 倍的令牌成本,同时提高了答案质量。

总体结论
这篇论文提供了对现有基于图的 RAG 方法的深入实验评估和比较。首先,提出了一个新的统一框架,可以涵盖所有现有的基于图的 RAG 方法。然后,在统一框架下对各种基于图的 RAG 方法进行了深入分析和比较。
此外,通过多种数据集从不同角度系统地评估了这些方法,并通过结合现有技术开发了变体,这些变体通常优于最先进的方法。
从广泛的实验结果和分析中,识别了几个重要的发现并分析了影响性能的关键组件。最后,总结了所学到的教训并提出了促进未来研究的实际研究机会。

核心创新
1. 统一框架:提出了一个新颖的统一框架,涵盖所有现有的基于图的检索增强生成(RAG)方法,从高层次角度抽象出几个关键操作。
2. 全面比较:在统一框架下系统地比较了 12 种代表性的基于图的 RAG 方法,提供了对这些方法的深入分析。
3. 新变体识别:通过结合现有技术,识别出新的基于图的 RAG 方法变体,这些变体在某些任务上优于最先进的方法。
4. 实验设计:在多个广泛使用的问答(QA)数据集上进行了全面的实验,评估了这些方法处理不同类型查询的能力,并进行了深入分析。
5. 模块化设计:框架的模块化设计允许不同算法在各个阶段无缝集成,确保每个阶段(如图构建、检索和生成)可以独立优化和重组。
6. 操作符设计:通过调整检索阶段或交换组件,研究人员可以快速测试和实施新策略,显著加速检索增强模型的开发周期。
7. 标准化评估:提供了一个标准化的方法来评估基于图的 RAG 方法,确保了可重复性,促进了公平的基准测试,并为未来的 RAG 基础 LLM 应用的创新提供了便利。
(文:PaperWeekly)