

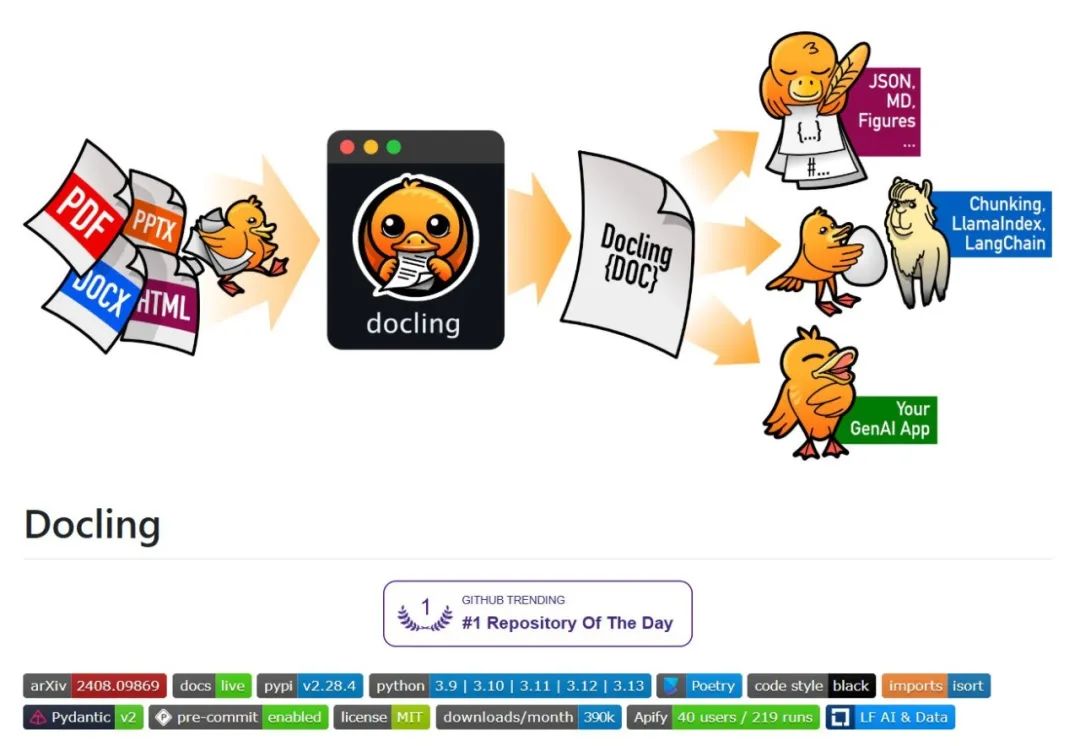
-
🗂️ 解析多种文档格式,包括 PDF、DOCX、XLSX、HTML、图像等
-
📑 高级 PDF 理解,包括页面布局、阅读顺序、表格结构、代码、公式、图像分类等
-
🧬 统一、富有表现力的 DoclingDocument 表示格式
-
↪️ 各种导出格式和选项,包括 Markdown、HTML 和无损 JSON
-
🔒 敏感数据和隔离环境的本地执行功能
-
🤖 即插即用集成,包括 LangChain、LlamaIndex、Crew AI 和 Haystack for agentic AI
-
🔍 广泛支持扫描的 PDF 和图像的 OCR
-
🥚 支持 VLM(视觉语言模型)
-
💻 简单方便的 CLI
SmolDocling 是一种多模态图像文本到文本模型,旨在实现高效的文档转换。它保留了 Docling 最受欢迎的功能,同时通过无缝支持 DoclingDocuments 确保与 Docling 完全兼容。
SmolDocling 尺寸极小(256M 个参数),性能可与更大的模型相匹配,支持以下功能:
-
🏷️ DocTags 用于高效标记化 – 引入 DocTags,这是一种高效且最小化的文档表示,与 DoclingDocuments 完全兼容。
-
🔍 OCR(光学字符识别) – 从图像中准确提取文本。
-
📐 布局和本地化 – 保留文档结构和文档元素边界框。
-
💻 代码识别 – 检测和格式化代码块,包括标识。
-
🔢 公式识别 – 识别和处理数学表达式。
-
📊 图表识别 – 提取和解释图表数据。
-
📑 表格识别 – 支持列和行标题以进行结构化表格提取。
-
🖼️ 图形分类 – 区分图形和图形元素。
-
📝 标题对应 – 将标题链接到相关图像和图形。
-
📜 列表分组 – 正确组织和构建列表元素。
-
📄 全页转换 – 处理整个页面以进行全面的文档转换,包括所有页面元素(代码、公式、表格、图表等)
-
🔲 带边界框的 OCR – 使用边界框的 OCR 区域。
-
📂 通用文档处理 – 针对科学和非科学文档进行训练。
-
🔄 无缝 Docling 集成 – 导入 Docling 并以多种格式导出。
-
💨 使用 VLLM 快速推理 – A100 GPU 上每页平均 0.35 秒。

https://github.com/docling-project/docling
https://huggingface.co/ds4sd/SmolDocling-256M-preview
文章来源:PyTorch研习社
(文:PyTorch研习社)