
TIMotion团队 投稿
量子位 | 公众号 QbitAI
双人动作生成新SOTA!
针对Human-human motion generation问题,浙江大学提出了一种对双人运动序列进行时序和因果建模的架构TIMotion,论文已发表于CVPR 2025。

具体来说,通过分别利用运动序列时间上的因果关系和两人交互过程中的主动被动关系,TIMotion设计了两种有效的序列建模方式。
此外还设计了局部运动模式增强,使得生成的运动更加平滑自然。
同一提示词下,使用TIMotion和当前SOTA方法Intergen对比如下:
(翻译版)这两个人倾斜着身子,面对面,玩起了石头剪刀布。与此同时,有一个人选择出布。

仔细对比手部动作,可以看出TIMotion的生成效果更好。
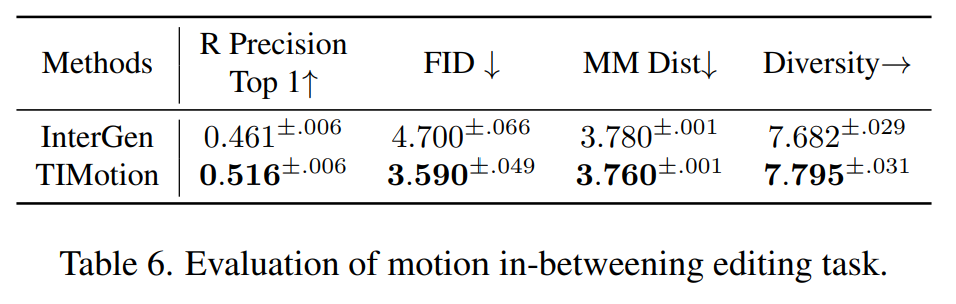
除此之外,实验结果显示,TIMotion在InterHuman和InterX数据集上均达到了SOTA效果。
下面具体来看。
全新瞄准双人动作生成
在生成式计算机视觉领域,人类动作生成对计算机动画、游戏开发和机器人控制都具有重要意义。
近年来,在用户指定的各种条件的驱动下,人类动作生成技术取得了显著进步。其中,许多利用大语言模型和扩散模型的方法得益于其强大的建模能力,在生成逼真而多样的动作方面取得了令人瞩目的成果。
尽管取得了这一进展,但现有的大多数方法主要是针对单人运动场景而设计的,因此忽略了人体运动的一个关键因素:人与人之间复杂而动态的互动。
为了更好地探索双人动作生成,研究团队首先抽象出了一个通用框架MetaMotion,如图1左侧所示,它由两个阶段组成:时序建模和交互混合。
以往的方法优先考虑的是交互混合而非时序建模,主要分为以下两类:
-
基于单人生成方法的扩展 -
基于单人建模的方法
如图(a)所示,基于单人生成方法的扩展会将两个人合并成一个人,然后将其输入现有的单人运动生成模块之中。基于单人建模的方法如图(b)所示,是对两个个体单独建模,然后分别使用自我注意和交叉注意机制,从两个个体自身和对方身上提取运动信息。
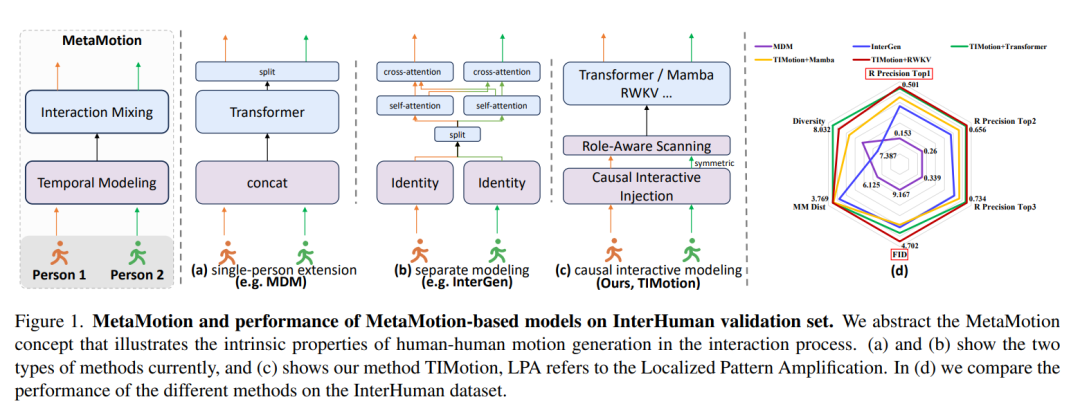
按照MetaMotion的一般逻辑,团队提出了 “时空交互框架”(Temporal and Interactive Framework),如图(c)所示,该框架模拟了人与人之间的因果互动,这种有效的时序建模方法可以简化交互混合模块的设计,减少可学习参数的数量。
提出双人动作生成架构TIMotion
团队首次提出了用于双人动作生成的核心概念 “MetaMotion”。
如上图所示,他们将双人运动生成过程抽象为两个阶段:时序建模和交互混合。
具体来说,两个单人序列通过时序建模模块得到输入序列。然后,输入序列被送入交互混合模块,这一过程可表示为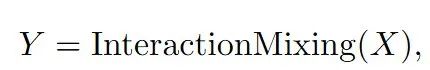
其中,InteractionMixing通常是Transformer结构,包括自注意和交叉注意机制。
值得注意的是,InteractionMixing也可以是一些新兴结构,比如Mamba、RWKV等等。
TIMotion
TIMotion的整体架构如下图所示,主要包含三个部分:(1) Causal Interactive Injection; (2) Role-Evolving Scanning; (3) Localized Pattern Amplification。
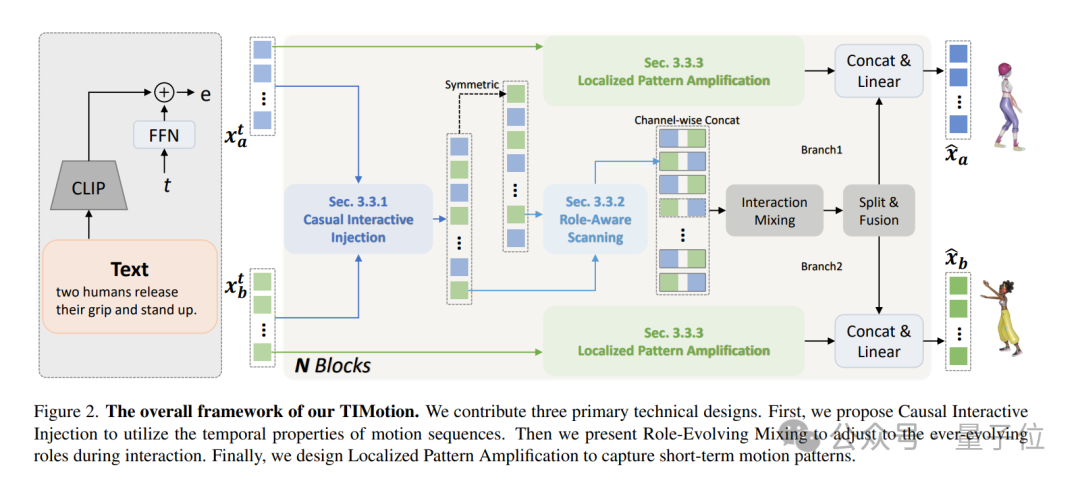
Causal Interactive Injection
运动的自我感知以及与他人运动的交互感知是双人运动生成的关键要素。
考虑到运动的因果属性,团队提出了 “因果互动注入”(Causal Interactive Injection)这一时序建模方法,以同时实现对自我运动的感知和两人之间的互动。
具体来说,团队用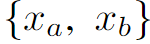 表示两个单人运动序列,其中
表示两个单人运动序列,其中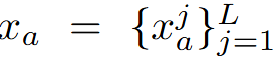 和
和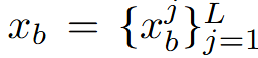 是各自的运动序列,L是序列的长度。
是各自的运动序列,L是序列的长度。
由于两个人在当前时间步的运动是由他们在之前时间步的运动共同决定的,因此团队将两个人的运动序列建模为一个因果交互序列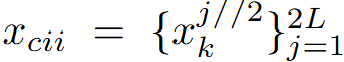 ,符号 // 表示除法后四舍五入,k可以通过下式获得:
,符号 // 表示除法后四舍五入,k可以通过下式获得:
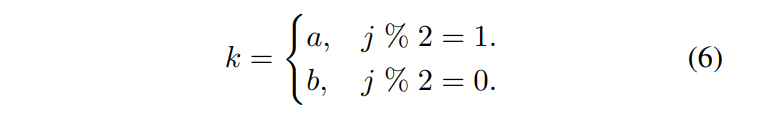
然后,团队可以将它们注入交互混合模块,并根据k的定义将两个个体的动作特征从输出结果中分离出来。
Role-Evolving Scanning
人类在交互过程中通常存在一定的内在顺序,例如,“握手”通常由一个人先伸出手,这意味着交互动作可以被分为主动运动和被动运动。
一些方法将文本描述分为主动和被动语态。
然而,随着互动的进行,“主动方”和“被动方”不断在两人之间交换,如图3所示。
为了避免冗余的文本预处理并且适应角色的不断变化,论文设计了一种高效且有效的方法:角色演变扫描(Role-Evolving Scanning)。
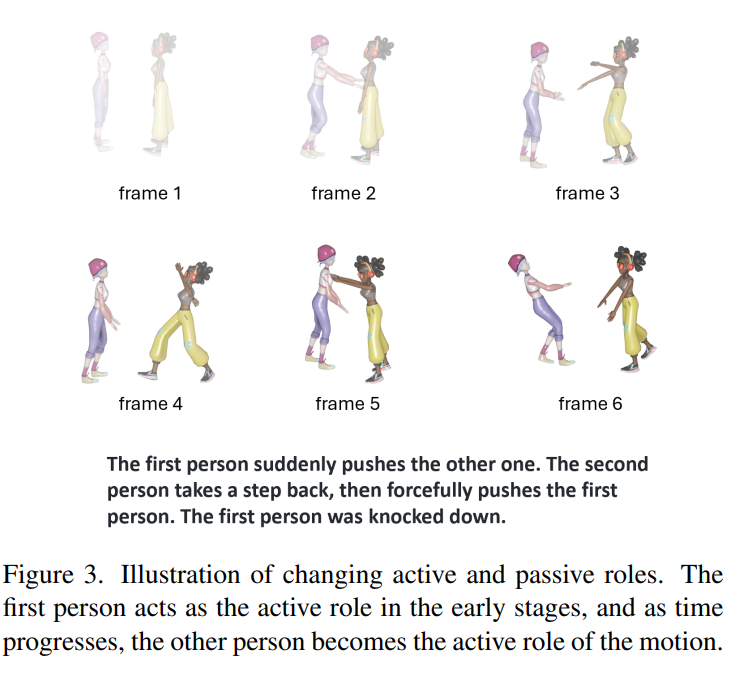
对于在Causal Interactive Injection中定义的因果交互序列x,显然a和b分别代表了主动方运动序列和被动方运动序列。然而这种关于主动和被动序列的假设并不总是符合实际顺序。
为了应对角色的变化,论文将因果交互序列重新建模为对称因果交互序列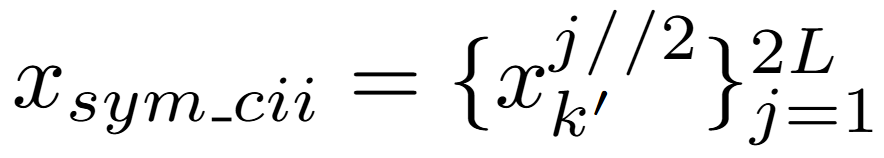 ,k’由下式得到:
,k’由下式得到:
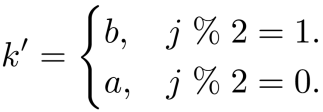
给定因果交互序列和对称因果交互序列,论文通过角色演变扫描得到最终的双人交互序列:
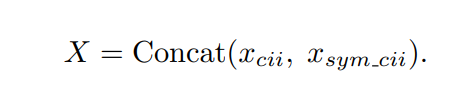
然后序列X被送入交互混合模块得到动作的特征。
接下来,分别按照特征通道和时间的维度将两个人的特征取出,并按照元素相加得到两人交互后的最终特征,特征split和fuse过程如下式:
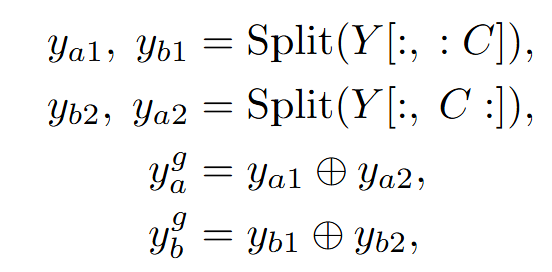
其中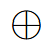 表示按元素相加。
表示按元素相加。
通过利用 “角色演变扫描 ”技术让两个人同时扮演主动和被动角色,网络可以根据文本的语义和动作的上下文动态调整两个人的角色。
Localized Pattern Amplification
因果交互注入和角色演变扫描主要基于双人互动之间的因果关系来建模整体运动,但忽视了对局部运动模式的关注。
为了解决这个问题,论文提出了局部运动模式增强(Localized Pattern Amplification),通过捕捉每个人的短期运动模式,使得生成更加平滑和合理的运动。
具体来说,论文利用一维卷积层和残差结构来实现局部运动模式增强。给定条件嵌入和两个单人的运动序列,可以建立下式的结构:
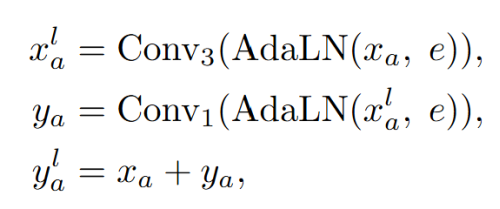
其中Convk表示卷积核为k的一维卷积,AdaLN为自适应层正则化。
得到全局输出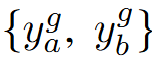 和局部输出
和局部输出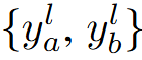 后,两者通过特征通道维度的进行Concat,然后通过线性层对特征进行转换,得到最终输出特征:
后,两者通过特征通道维度的进行Concat,然后通过线性层对特征进行转换,得到最终输出特征:
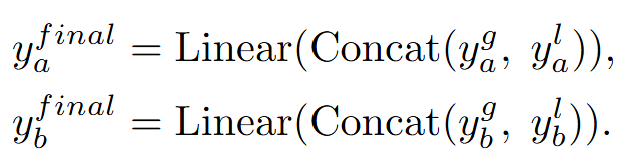
通过这种方式,能够捕捉每个人的短期动作模式,并将其与条件嵌入结合,从而生成更平滑和更合理的动作序列。
目标函数
论文采用了常见的单人动作损失函数,包括足部接触损失和关节速度损失。
此外,还使用了与InterGen相同的正则化损失函数,包括骨长度损失、掩码关节距离图损失和相对方向损失。
最终,总体损失定义为:
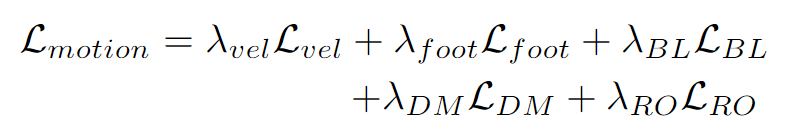
实验结果
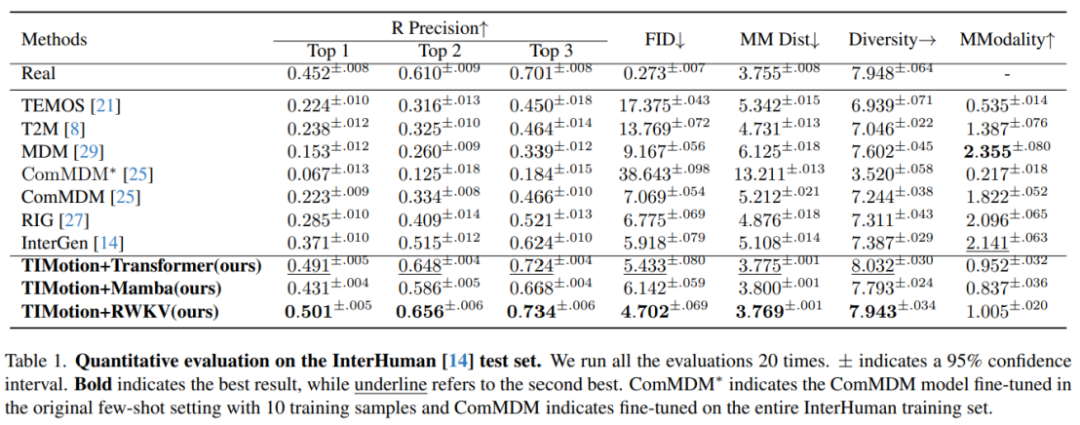
在InterHuman数据集上,TIMotion在三个不同的交互混合结构(Transformer, Mamba, RWKV)上都获得了较好的表现,其中TIMotion和RWKV结构相结合FID达4.702,Top1 R precision达到0.501,达到了SOTA。
在InterX数据集上,TIMotion在R precision,FID, MM Dist等度量指标上也达到了最优的表现。
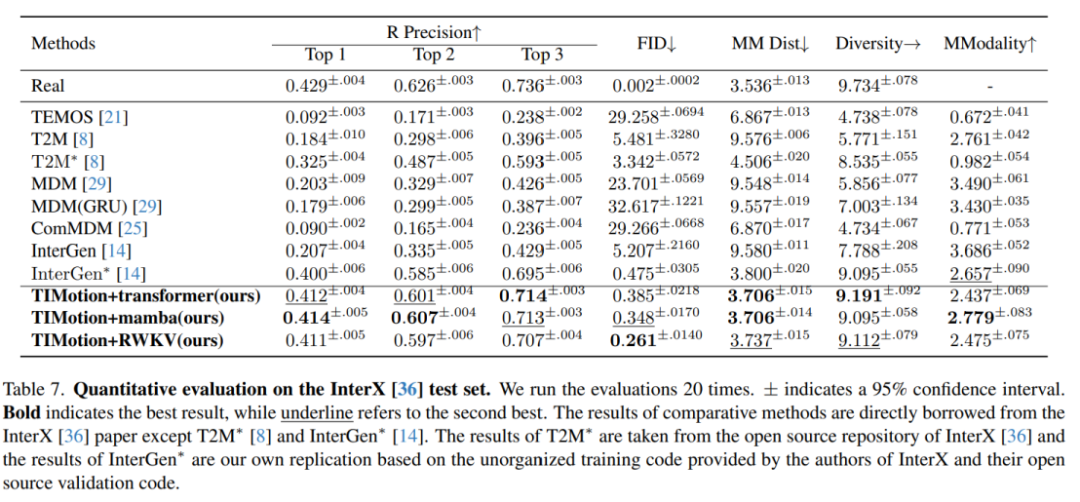
在计算复杂度方面,论文将TIMotion与当前最先进的方法InterGen进行了比较。
与InterGen相比,TIMotion所需的参数和FLOPs更少,但在综合指标FID和R Precision方面优于InterGen。
值得注意的是,使用与InterGen类似的Transformer架构,TIMotion每个样本的平均推理时间仅为0.632秒,而InterGen则需要1.991秒。
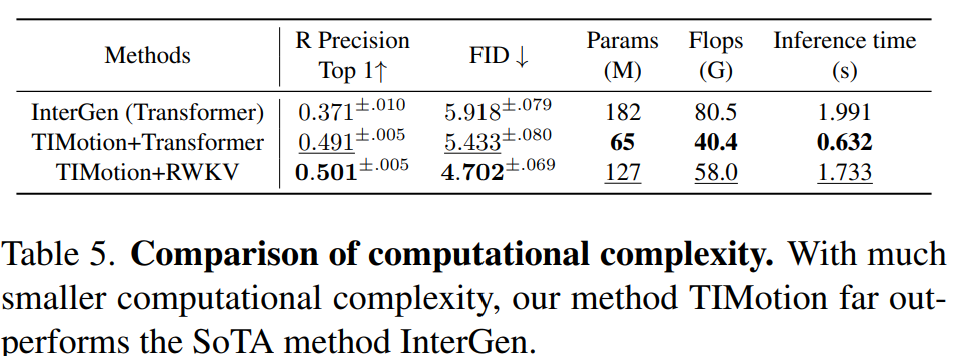
论文在InterHuman的测试集上进行了运动编辑的实验,通过给定序列的前10%和后10%帧让模型预测额外80%帧的序列来进行评估方法的可编辑性。
Table 6显示了TIMotion在运动插值编辑任务中,在所有度量指标上都超越了InterGen。
总结
论文将双人运动生成过程抽象为一个通用框架MetaMotion,其中包括两个阶段:时间建模和交互混合。
研究发现,由于目前的方法对时序建模的关注不足,导致次优结果和模型参数冗余。
在此基础上,团队提出了TIMotion,这是一种高效、出色的双人运动生成方法。
具体来说,他们首先提出了Causal Interactive Injection,利用时序和因果属性将两个独立的担任序列建模为一个因果序列。
此外,还提出了Role-Evolving Mixing来适应整个互动过程中的动态角色,并设计了Localized Pattern Amplification来捕捉短期运动模式,从而生成更平滑、更合理的运动。
TIMotion在两个大规模双人运动生成的数据集InterHuman和InterX上均达到了SOTA的效果,证明了论文所提出方法的有效性。
因此,TIMotion为Human-human motion generation提供了一个有效的解决方案。
论文:
https://arxiv.org/abs/2408.17135
项目主页:
https://aigc-explorer.github.io/TIMotion-page/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)