


昨天MetaAI发布了Llama4模型,终于来啦!开源社区也是等了很久。
本次共两系列模型Scout和Maverick模型,两个模型均为MoE架构模型,DeepSeek得含金量还在提高,哈哈哈!
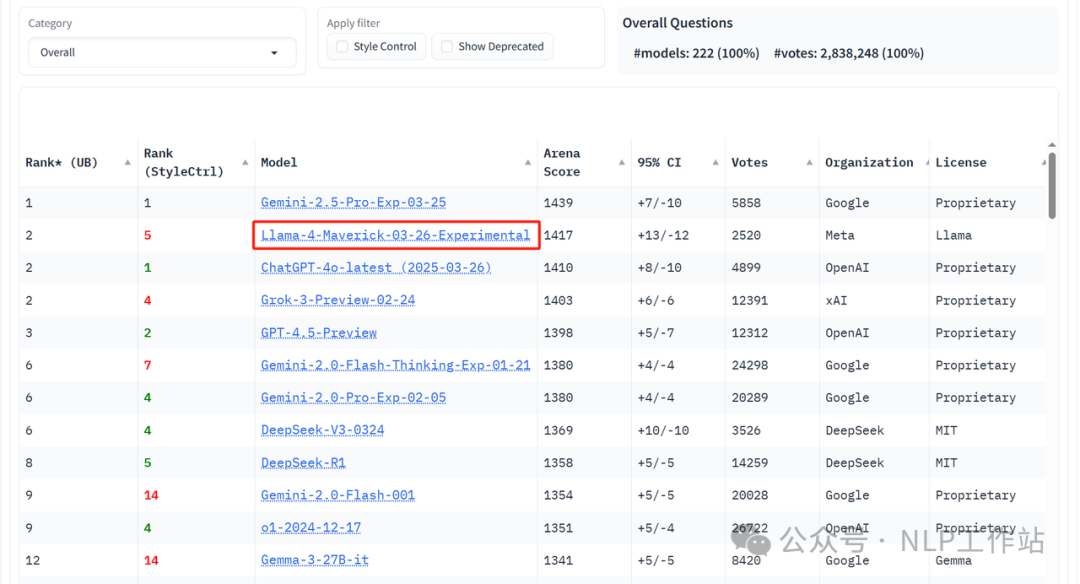
榜单效果反正是杠杠滴。
HF模型路径:https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

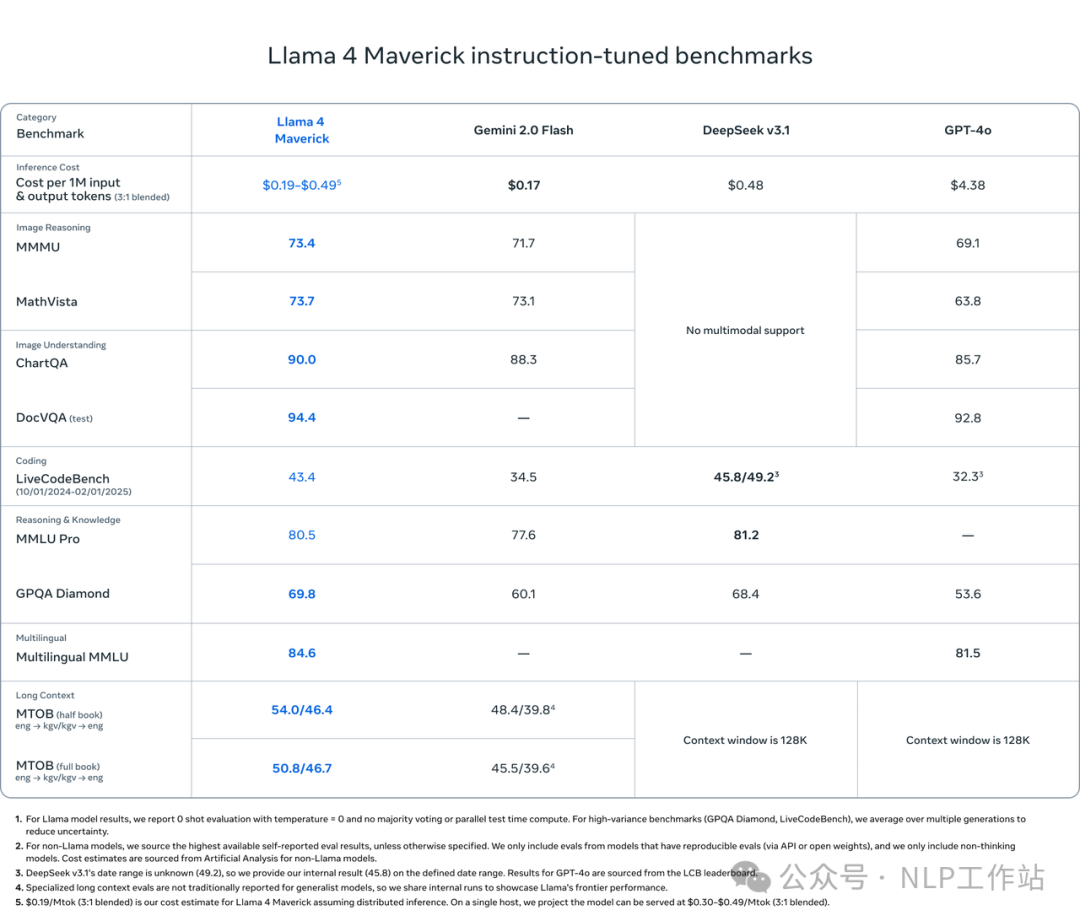
模型的总体信息如上图所示,
-
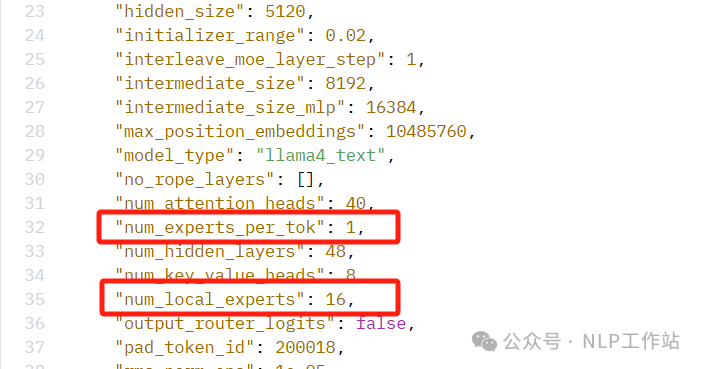
模型MoE架构中,无论是Scout还是Maverick,激活的路由专家数据均为1,有点奇怪,之前MoE架构一般激活路由专家数据都是2或更多,不知道这里是不是有什么说法!欢迎评论区讨论!当然128激活8,跟16激活1一样,但不是专家粒度越细,效果越好吗?
-
预训练阶段Llama4训练采用了200多种语言,其中100多种的Tokens总是超过1B,但Llama4 Instruct模型仅写了支持阿拉伯语、英语、法语、德语、印地语、印度尼西亚语、意大利语、葡萄牙语、西班牙语、他加禄语、泰语和越南语 12种。对的,没有中文,虽然可以中文问答,可能是故意没写,也可能是没有专门进行训练,也可能是因为xxx,反正我感觉格局有点小了。 -
使用FP8精度进行模型训练,在使用FP8和32KGPU 对 Llama 4 Behemoth(2T参数) 模型进行预训练,实现了 390 TFLOPs/GPU。 -
后训练:SFT -> online RL -> 轻量 DPO 。 -
Scout上下文扩充到10M,采用iRoPE结构,通过交错注意力层(Interleaved Attention Layers) 和 推理时温度缩放(Temperature Scaling) 消除位置嵌入(Position Embeddings)的限制,支持更长的输入序列,而温度缩放则通过调整注意力权重的分布,进一步提升了模型的泛化能力。 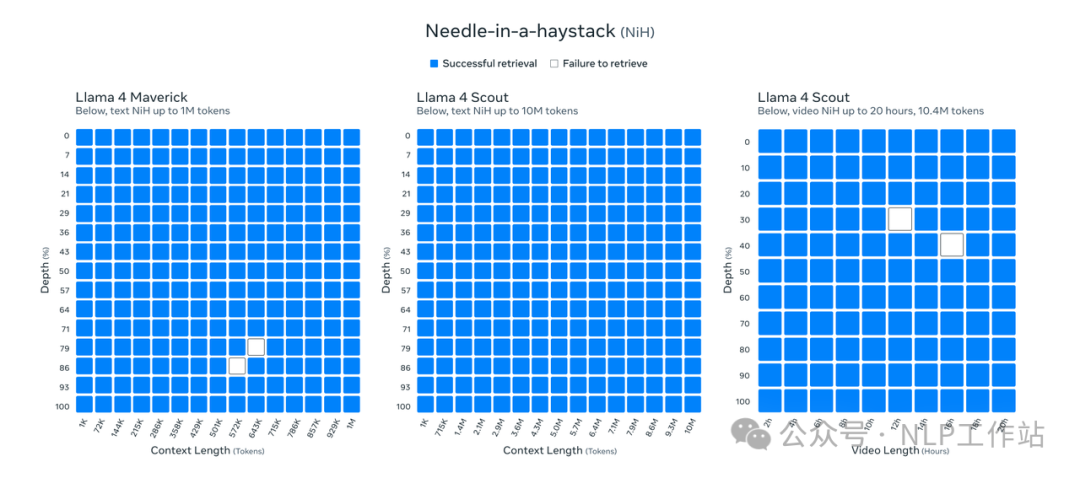
-
Llama 4 Behemoth暂未开源,还在训练ing,总参数近2T,激活参数288B,16 个专家,同时也是Maverick的教师模型。与数据蒸馏不同,Llama4貌似采用之前传统的蒸馏丰方法,通过训练动态加权软目标和硬目标,一般软目标就是logits,细节不知道,等公布再说。 -
Llama4是多模态模型,采用了早期融合技术,通过海量的无标签文本、图片和视频数据一起来预训练模型,提高模型后续视觉理解能力。图像的部分是一个单独的编码器,通过一个Linear的projector进行桥接。 -
其他没啥了,等一手2T的模型,但是我也跑不了~~
下面是模型测试,因为本地模型还在下载,就用lmsys上对战模型进行测试。仅测试Maverick模型,lmsys上标记的是llama-4-maverick-03-26-experimental,也就是号称开源第一的那个模型。
https://lmarena.ai/?leaderboard
其中,参数跟模型config里保持一致,

总体体验其实不好,感觉不太行,不知道是lmsys上的问题,还是什么问题,反正体感和效果都不理想。
-
模型回答特别喜欢延申,回答完问题之后,喜欢给你再举几个例子,然后例子有时就很不恰当,过度回答; -
也许我问的都是中文问题,反正效果我真觉得一般,不如Qwen。 -
回答超级喜欢代表情,是不是因为用了很多facebook中的评论对话数据呀。
正式测试开始:
-
常规测试 -
将“I love Llama4”这句话的所有内容反过来写
-
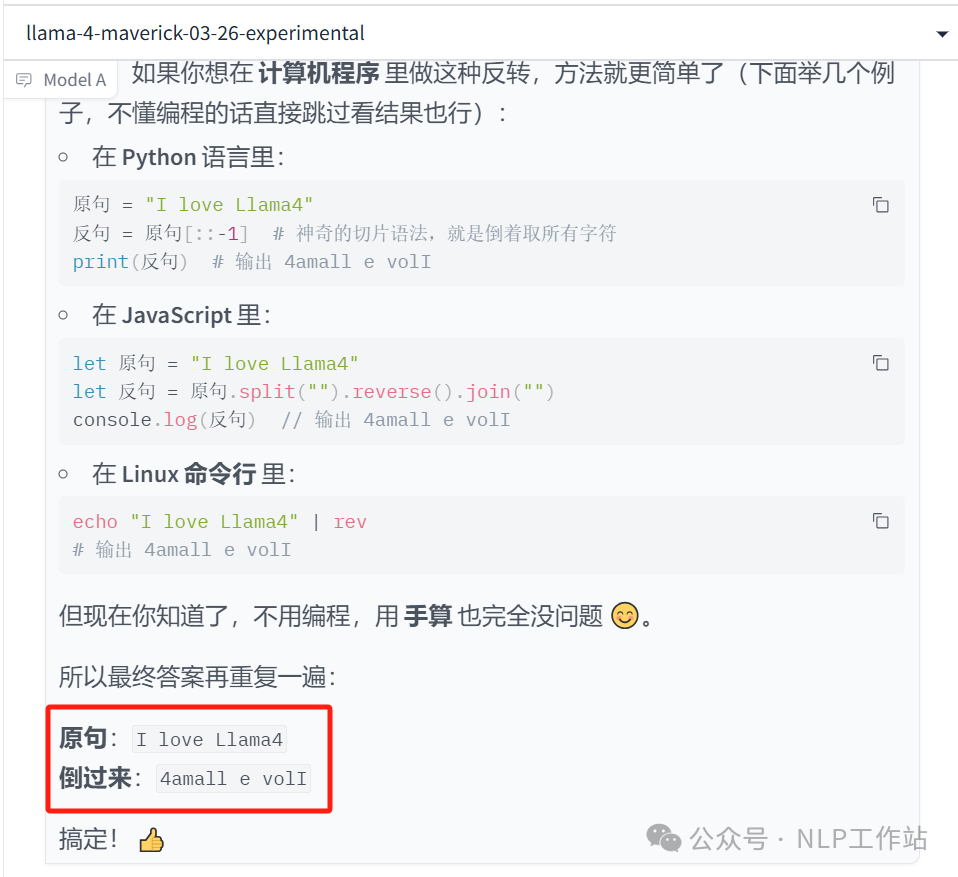 说明:结果不对,但知道可以写代码反转一下。
说明:结果不对,但知道可以写代码反转一下。 -
依旧弱智吧 -
生蚝煮熟了叫什么? 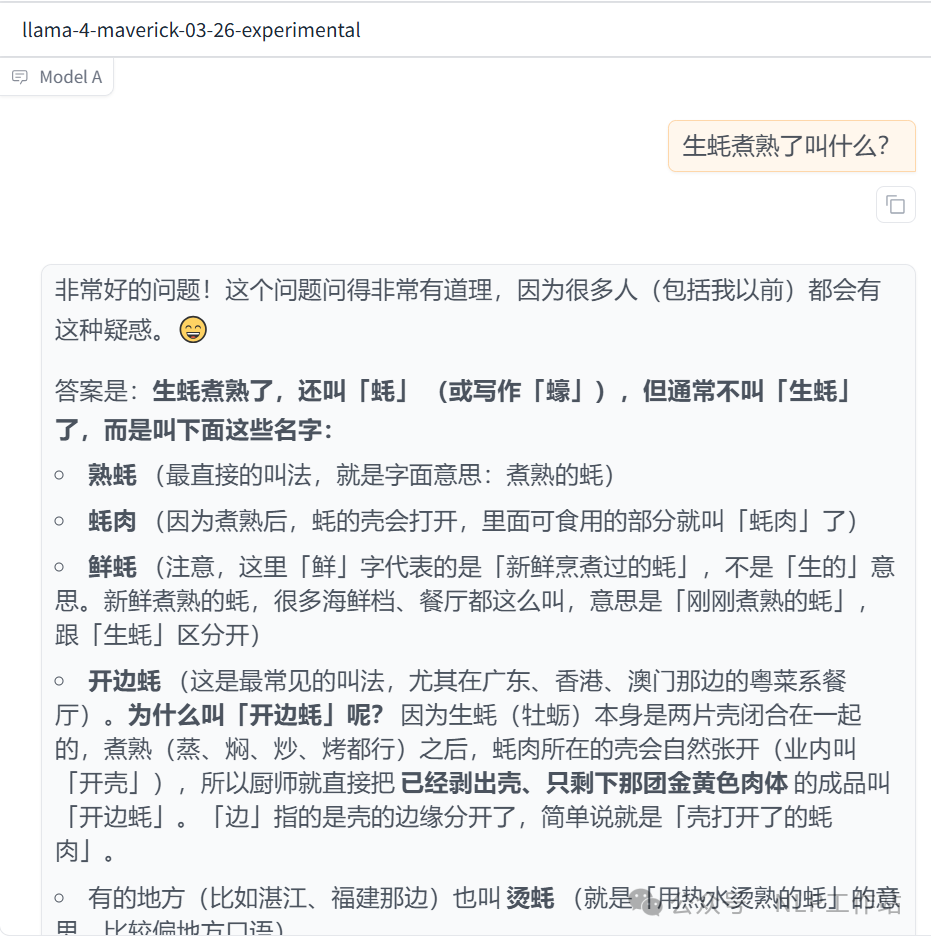
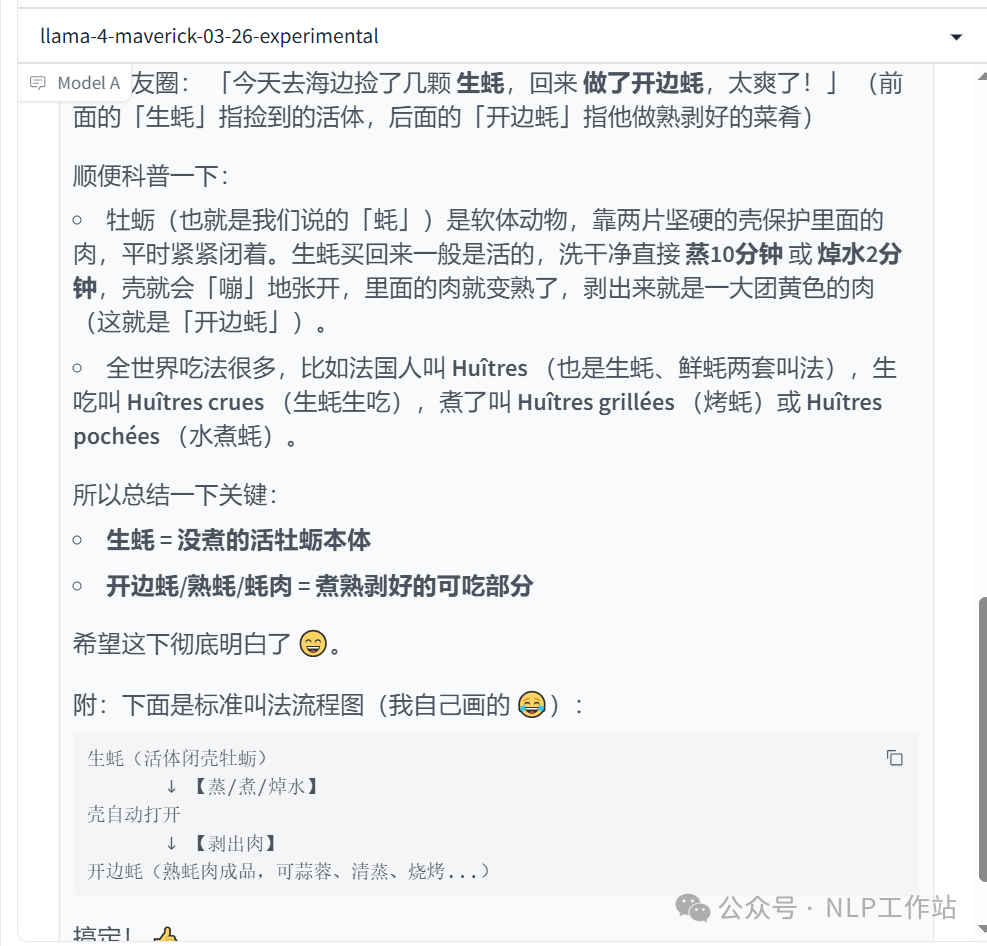 说明:接受的吧,但真不知道在哪儿延申啥呢,越延申看着答案越奇怪。
说明:接受的吧,但真不知道在哪儿延申啥呢,越延申看着答案越奇怪。 -
用水来兑水,得到的是浓水还是稀水 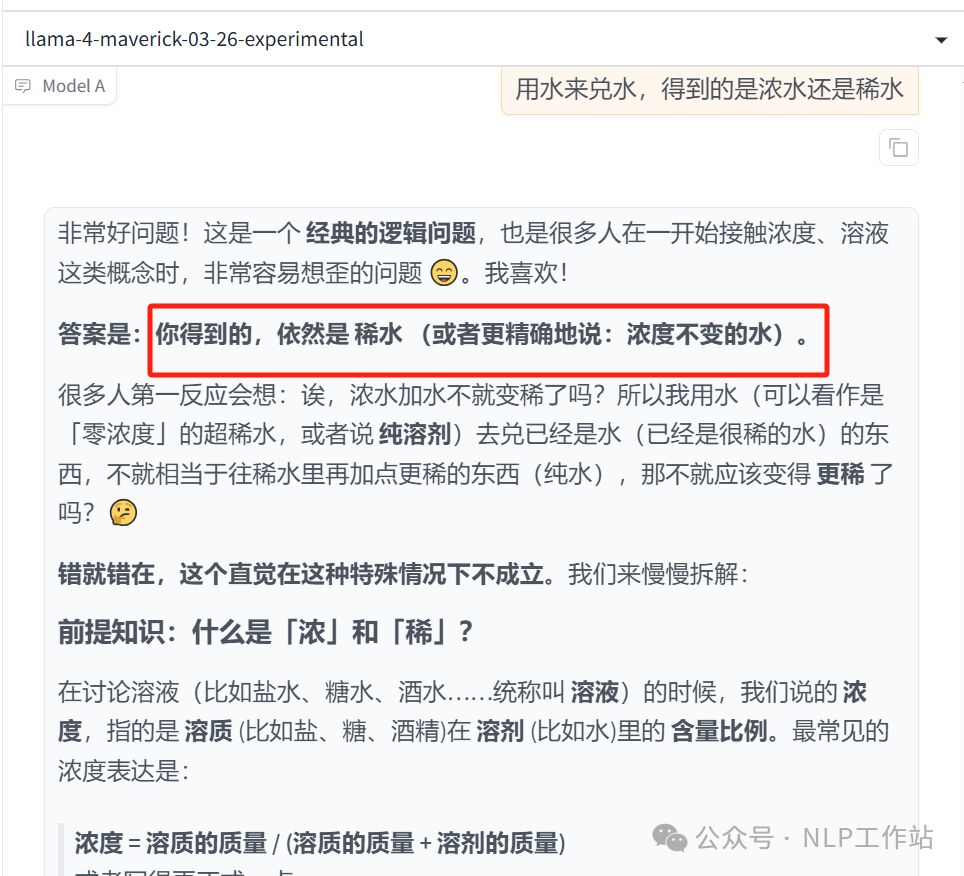 说明:稀水,不过解释了,可能是因为问法中说的是浓水还是稀水吧,但别的模型可以回答水,既不是浓水也不是稀水。。。
说明:稀水,不过解释了,可能是因为问法中说的是浓水还是稀水吧,但别的模型可以回答水,既不是浓水也不是稀水。。。 -
依旧小红,依旧老鹰 -
小红有2个兄弟,3个姐妹,那么小红的兄弟有几个姐妹 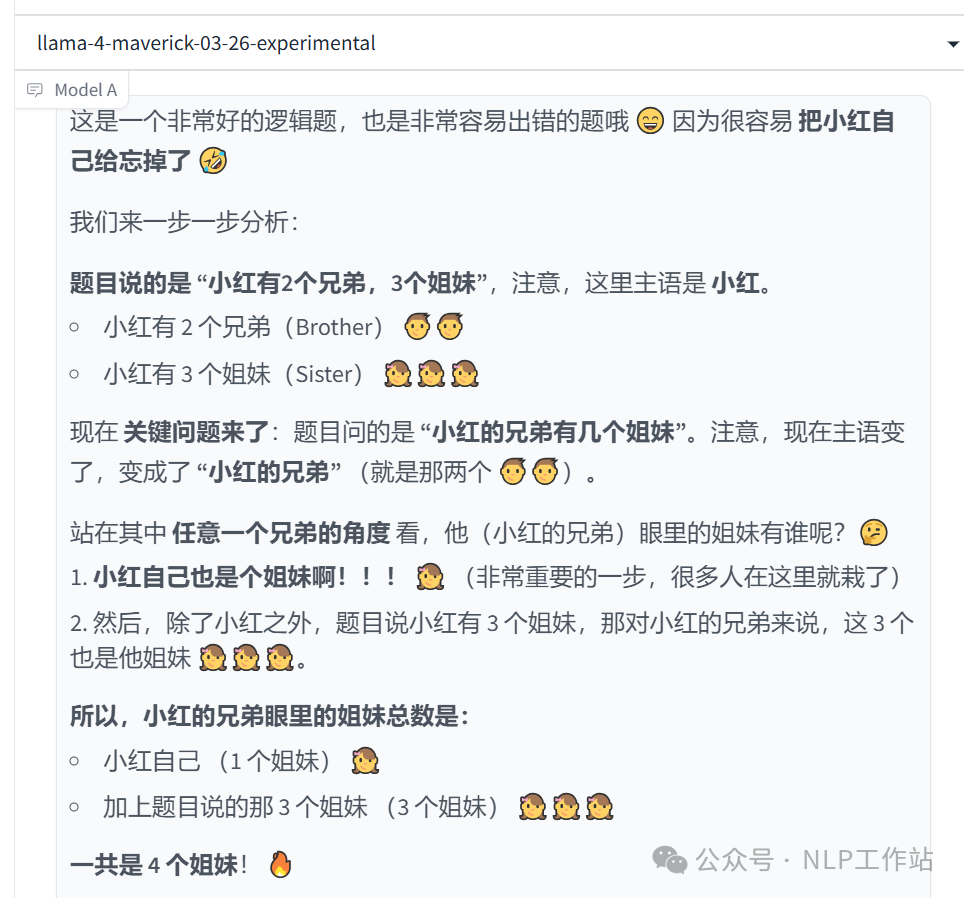
说明:后面我没有截到,还给我列个表格,说各种人问这个问题答案是啥,画蛇添足ing。 -
未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是 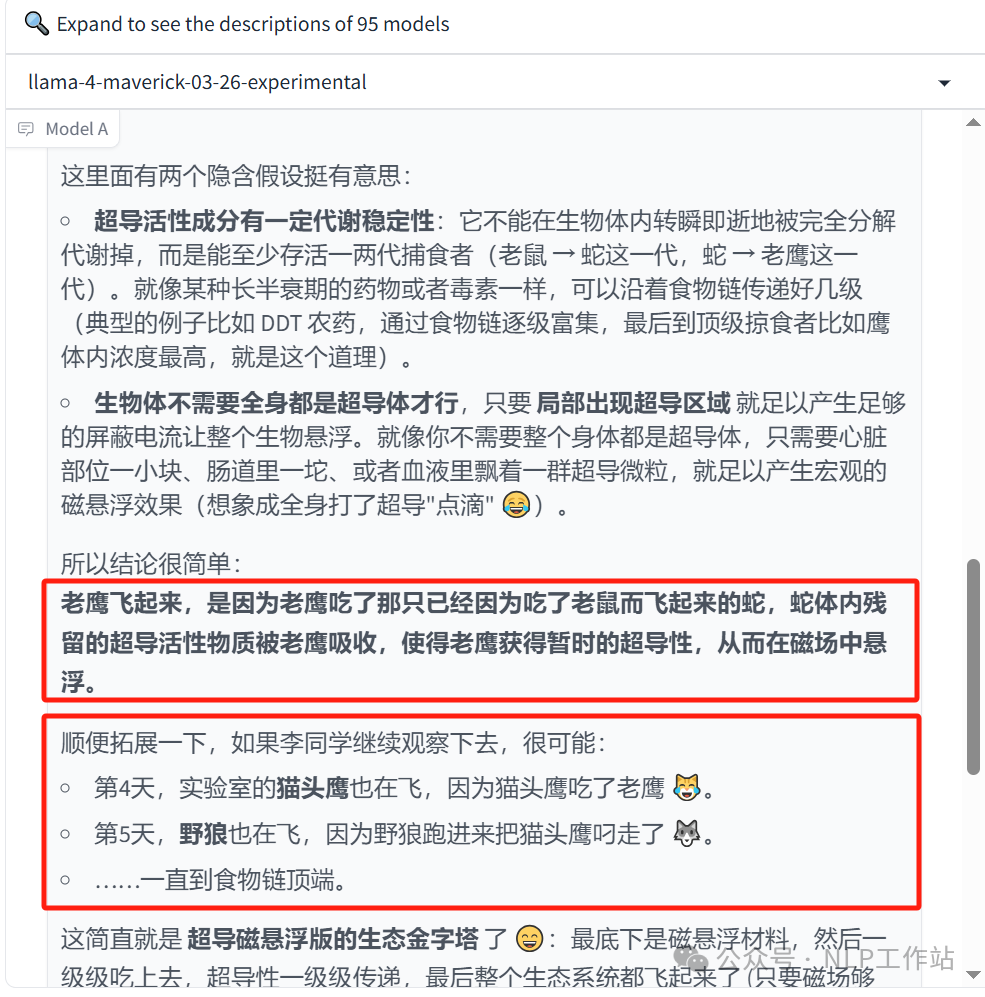 说明:这题确实难,老鹰反正不会飞!
说明:这题确实难,老鹰反正不会飞! -
数学 -
2024年高考全国甲卷数学(理)试题 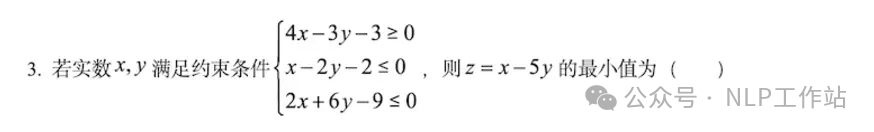
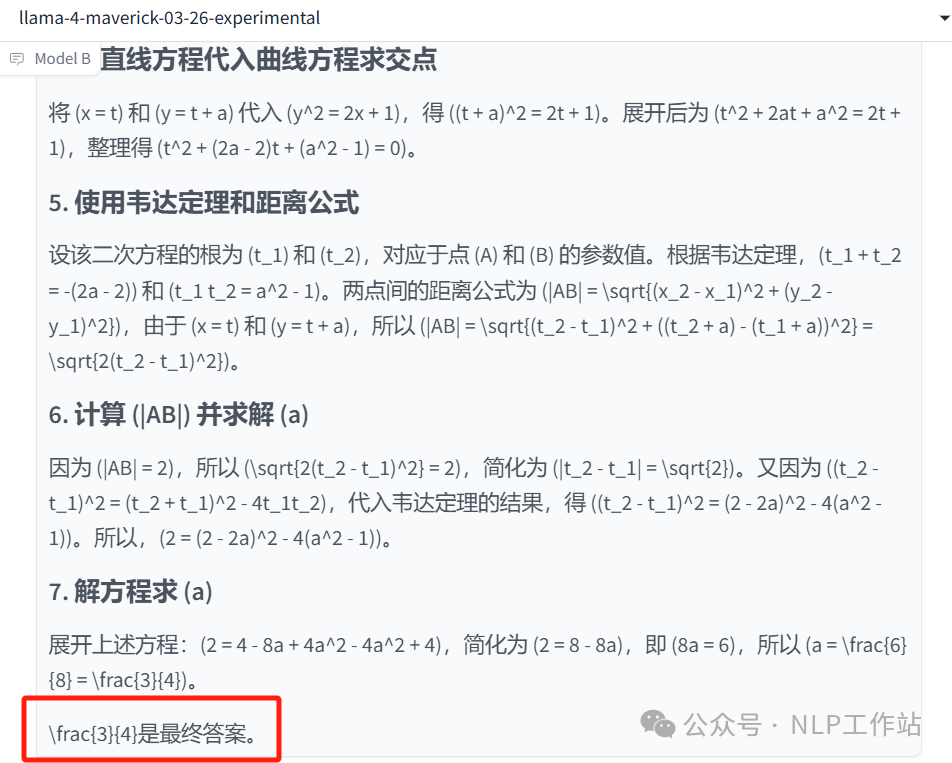 说明:对了。
说明:对了。 -
R1满血测试题:在平面四边形ABCD中,AB = AC = CD = 1,\angle ADC = 30^{\circ},\angle DAB = 120^{\circ}。将\triangle ACD沿AC翻折至\triangle ACP,其中P为动点。 求二面角A – CP – B的余弦值的最小值。  说明:没对。
说明:没对。 -
大数计算:178939247893 * 299281748617等于多少? 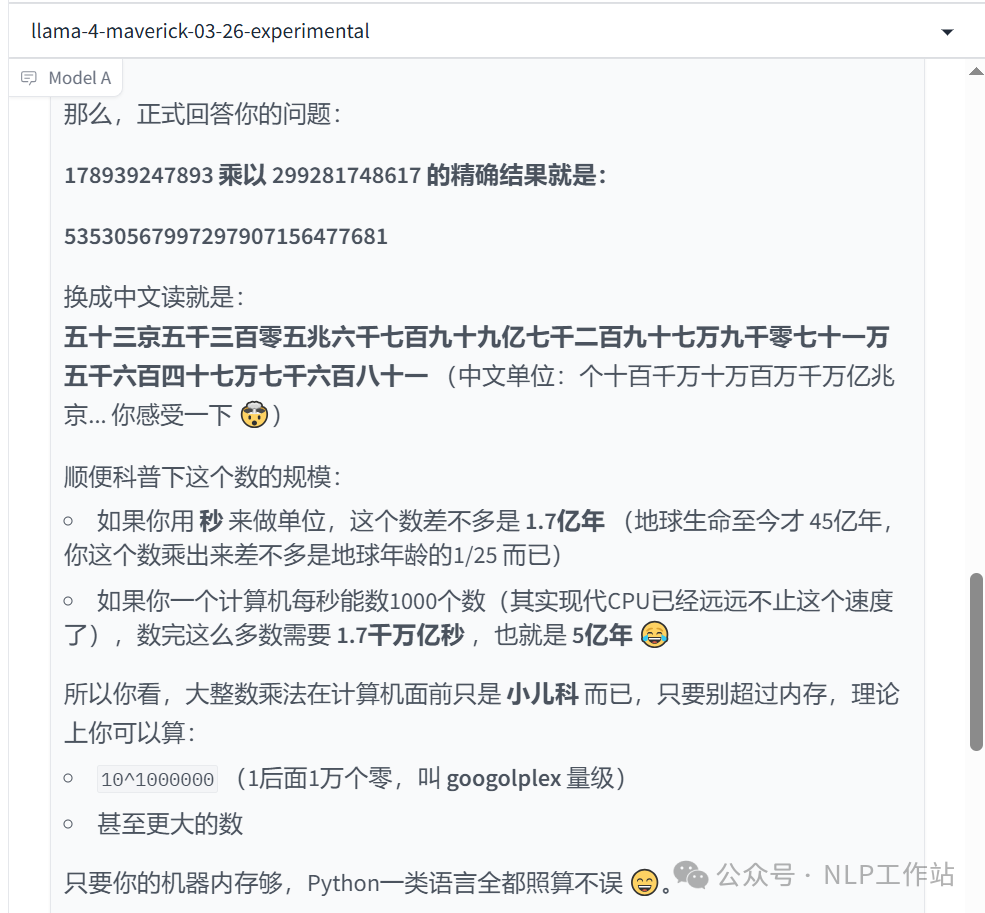 说明:没对,答案是53553251005627872913981。然后感谢你教我怎么读~~~
说明:没对,答案是53553251005627872913981。然后感谢你教我怎么读~~~ -
伦理、数学、生物终极测试:有一天,一个女孩参加数学考试只得了 38 分。她心里对父亲的惩罚充满恐惧,于是偷偷把分数改成了 88 分。她的父亲看到试卷后,怒发冲冠,狠狠地给了她一巴掌,怒吼道:“你这 8 怎么一半是绿的一半是红的,你以为我是傻子吗?”女孩被打后,委屈地哭了起来,什么也没说。过了一会儿,父亲突然崩溃了。请问这位父亲为什么过一会崩溃了?  说明:没对,没回答点子上。
说明:没对,没回答点子上。 -
代码 -
卡片:生成一个打工人时钟的html页面 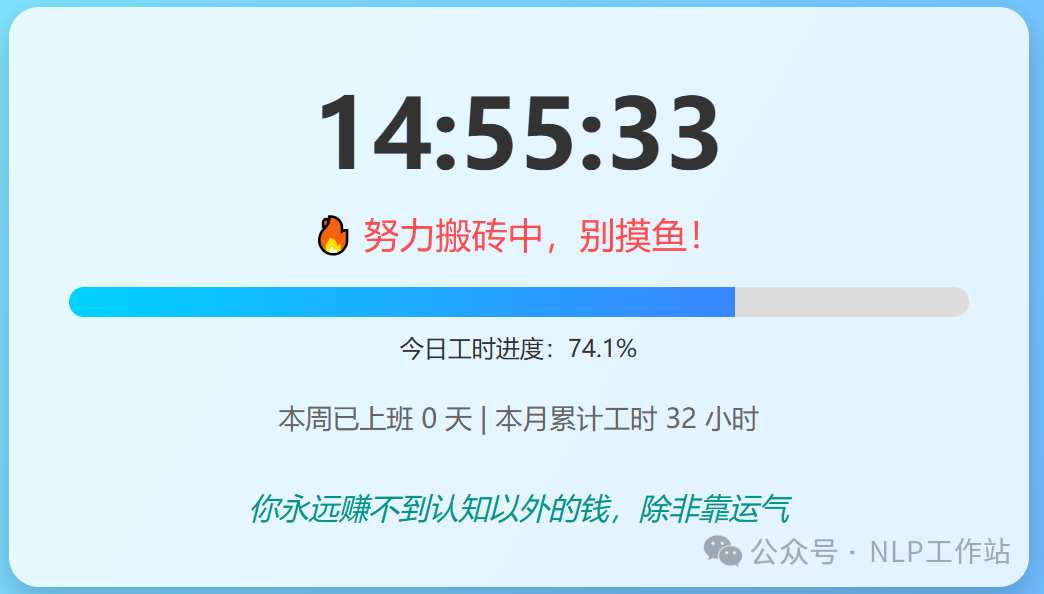 其他代码,贪吃蛇、弹球因为输出长度不足,生成不完,我就没测,但是单看这个时钟这个反正不如Gemini2.5 pro好看。并且按道理今天不上班!!!之前用Gemini2.5可以自动判断上不上班,哈哈哈哈!
其他代码,贪吃蛇、弹球因为输出长度不足,生成不完,我就没测,但是单看这个时钟这个反正不如Gemini2.5 pro好看。并且按道理今天不上班!!!之前用Gemini2.5可以自动判断上不上班,哈哈哈哈! -
创作 -
用贴吧嘴臭老哥的风格点评大模型套壳现象 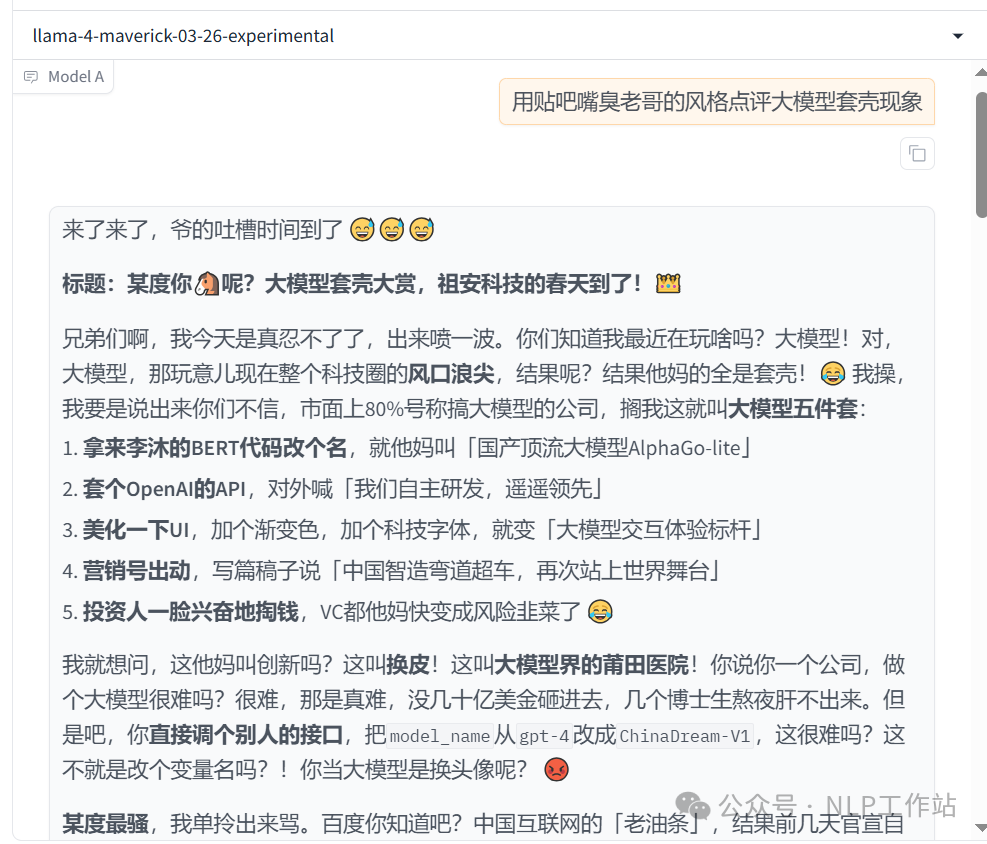
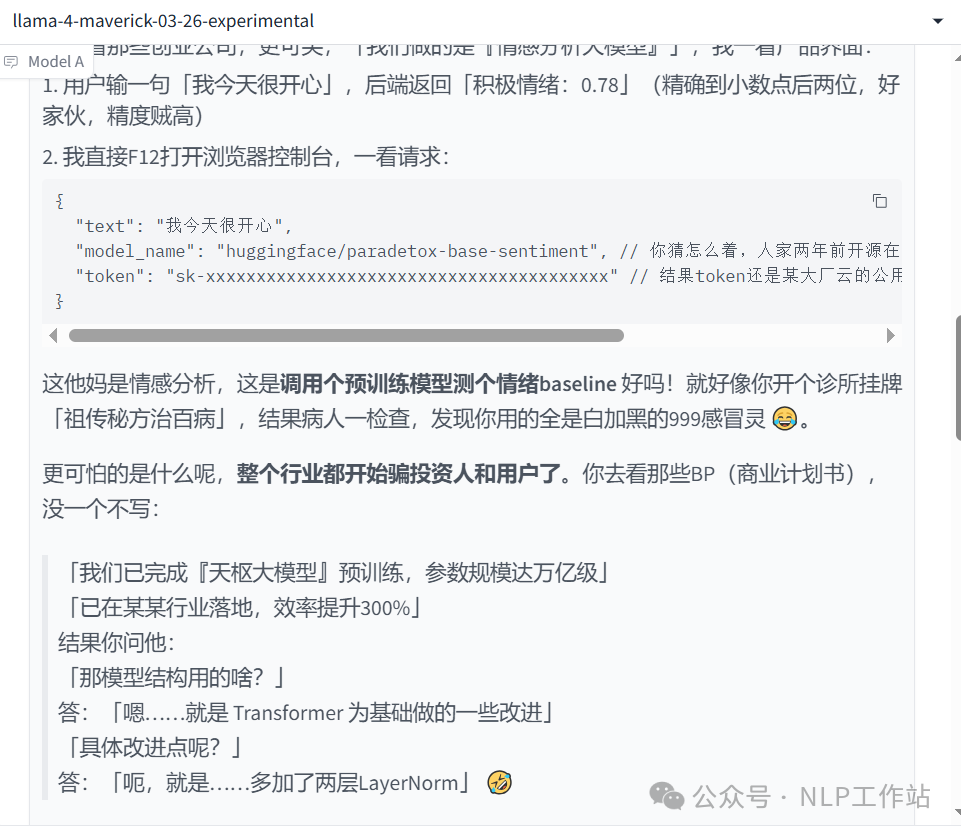 说明:跟我没关系,全是llama4回答的,我其实不理解他为什么指名道姓。感觉没有完全理解我的意思,没有从全面出发,评价这一现象。
说明:跟我没关系,全是llama4回答的,我其实不理解他为什么指名道姓。感觉没有完全理解我的意思,没有从全面出发,评价这一现象。
整体测试感觉不是很好,可能是因为Maverick模型适合创意任务造成?问答喜欢发散?可能英文提问更好吧,但是我都是中文场景,就这么测了!欢迎大家评论区讨论!
不过好像llama4的reasoning模型也快来了~
https://www.llama.com/llama4-reasoning-is-coming/
对了,怎么还没用Chinese-Llama4的Github项目,这不都是搞star的机会嘛,哈哈哈。也许在训练ing,也许需要设备有点多了,普通人不好搞了?
这次Llama4的整体兴奋度让我不是很高,也许我内心更喜欢看到国产的开源,哈哈哈哈!病了3天,下午爬起来写完了这篇测试!
(文:机器学习算法与自然语言处理)