

近年来,Transformer 架构在自然语言处理领域取得了巨大成功,从机器翻译到文本生成,其强大的建模能力为语言理解与生成带来了前所未有的突破。
然而,随着模型规模的不断扩大和应用场景的日益复杂,传统 Transformer 架构逐渐暴露出缺陷,尤其是在处理长文本、关键信息检索以及对抗幻觉等任务时,Transformer 常常因过度关注无关上下文而陷入困境,导致模型表现受限。
为攻克这一难题,来自微软和清华的研究团队提出了 DIFF Transformer,一种基于差分注意力机制的创新基础模型架构。

-
论文标题:Differential Transformer
-
论文链接:https://openreview.net/pdf?id=OvoCm1gGhN
-
代码链接:https://aka.ms/Diff-Transformer
其核心思想是通过计算两组 Softmax 注意力图的差值来放大对关键上下文的关注,同时消除注意力噪声干扰。DIFF Transformer 具备以下显著优势:
DIFF Transformer 的特性使其在自然语言处理领域具有广阔的应用前景,有望成为推动语言模型发展的新动力。此外,已有跟进研究初步验证方法在视觉、多模态等领域中的有效性,显示出其跨模态通用的潜力。该研究已被 ICLR 2025 接收,并获选为 Oral 论文(入选比例 1.8%)。
方法
本文提出了一种名为 Differential Transformer(DIFF Transformer) 的基础模型架构,旨在解决传统 Transformer 在长文本建模中对无关上下文过度分配注意力的问题。该方法通过差分注意力机制(Differential Attention)放大对关键上下文的关注,同时消除注意力噪声,从而显著提升模型在多种任务中的性能。
差分注意力的数学表达如下:
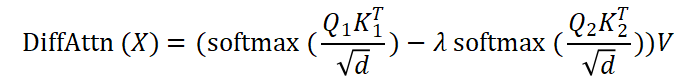
其中,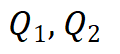 和
和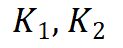 分别是两组查询和键向量,
分别是两组查询和键向量,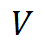 是值向量,
是值向量,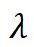 是一个可学习的标量参数,用于调节两组注意力图的权重。计算过程如图 1 所示。
是一个可学习的标量参数,用于调节两组注意力图的权重。计算过程如图 1 所示。
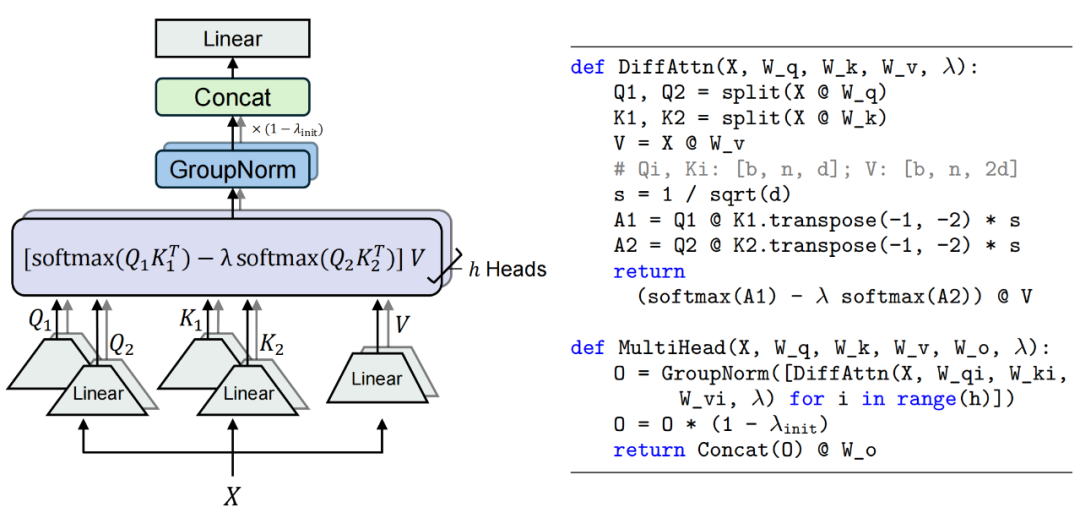
图 1. 差分注意力机制图示与伪代码
为了同步学习速率,将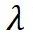 重参数化为:
重参数化为:
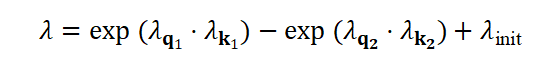
其中,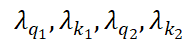 是可学习的向量,而
是可学习的向量,而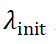 是用于初始化的常数。
是用于初始化的常数。
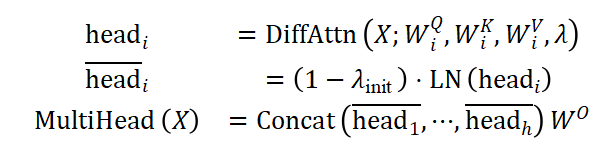
其中 是注意力头的数量,
是注意力头的数量,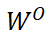 是输出投影矩阵。为了保持与 Transformer 梯度一致,DIFF Transformer 在每个头的输出后应用了独立的归一化层,采用 RMSNorm 实现。
是输出投影矩阵。为了保持与 Transformer 梯度一致,DIFF Transformer 在每个头的输出后应用了独立的归一化层,采用 RMSNorm 实现。
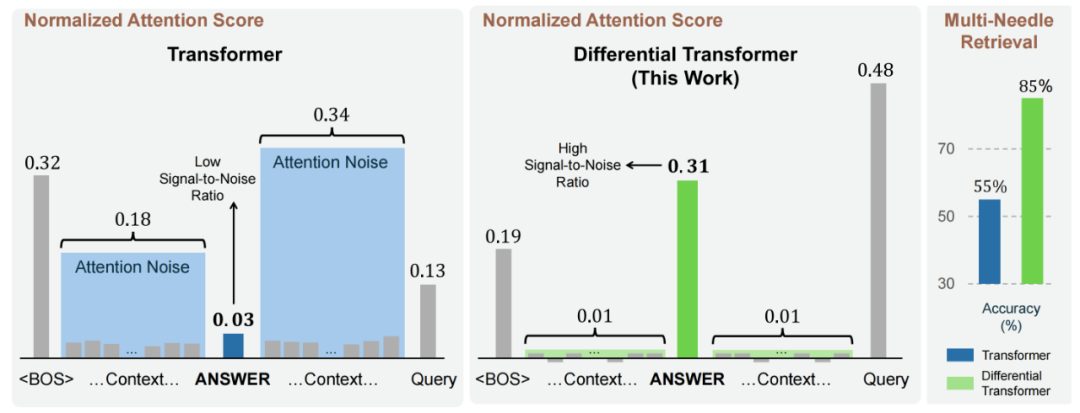
图 2. Transformer 与 DIFF Transformer 注意力分数分布可视化
实验
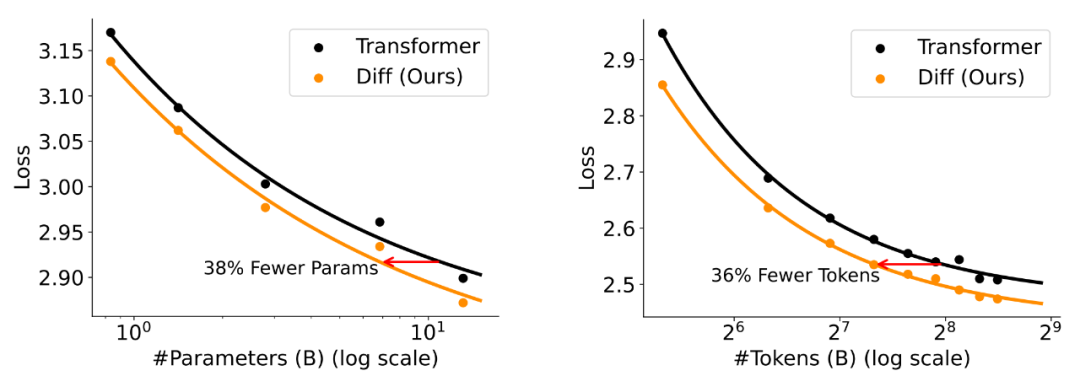
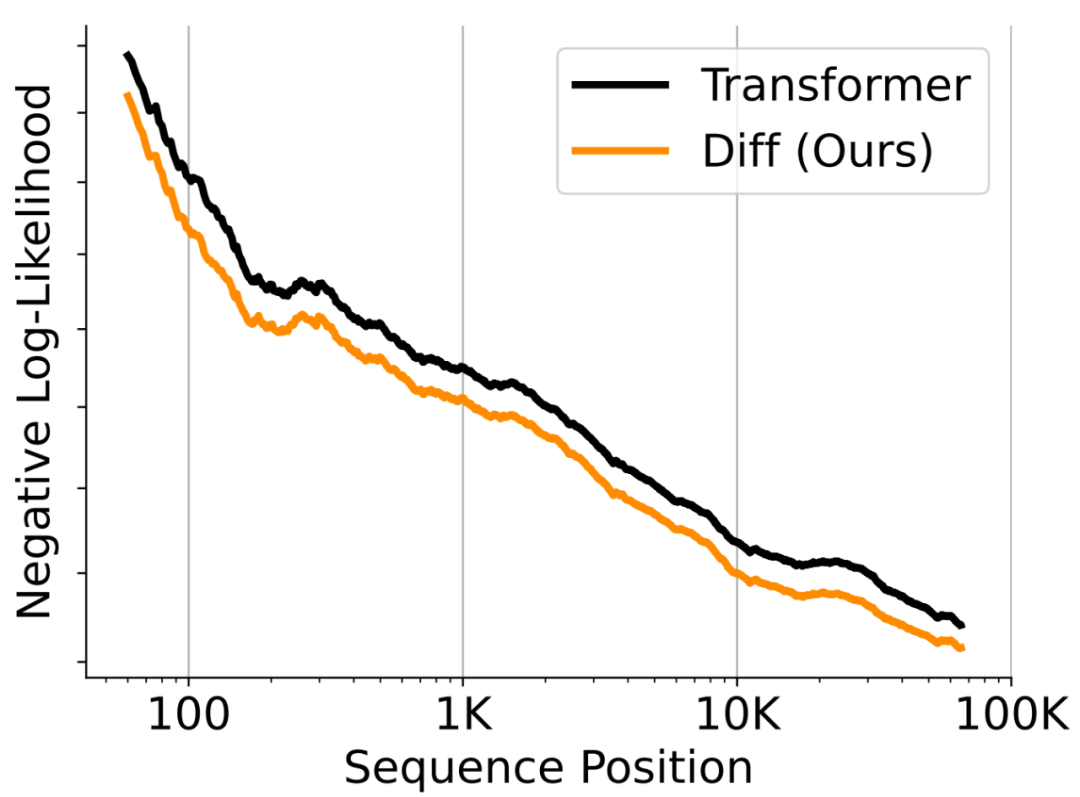
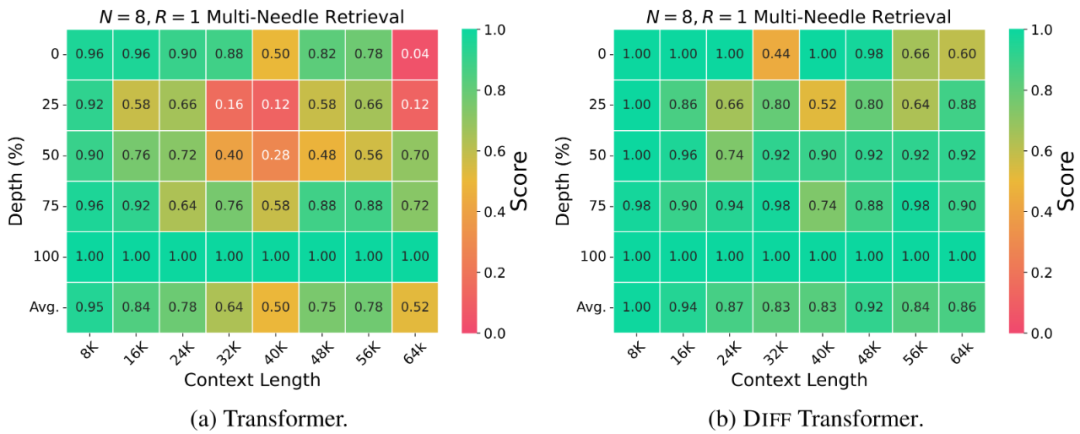
作者通过一系列实验验证了 DIFF Transformer 在多个方面的卓越性能,证明了其在大语言模型中应用的独特潜力与优势。
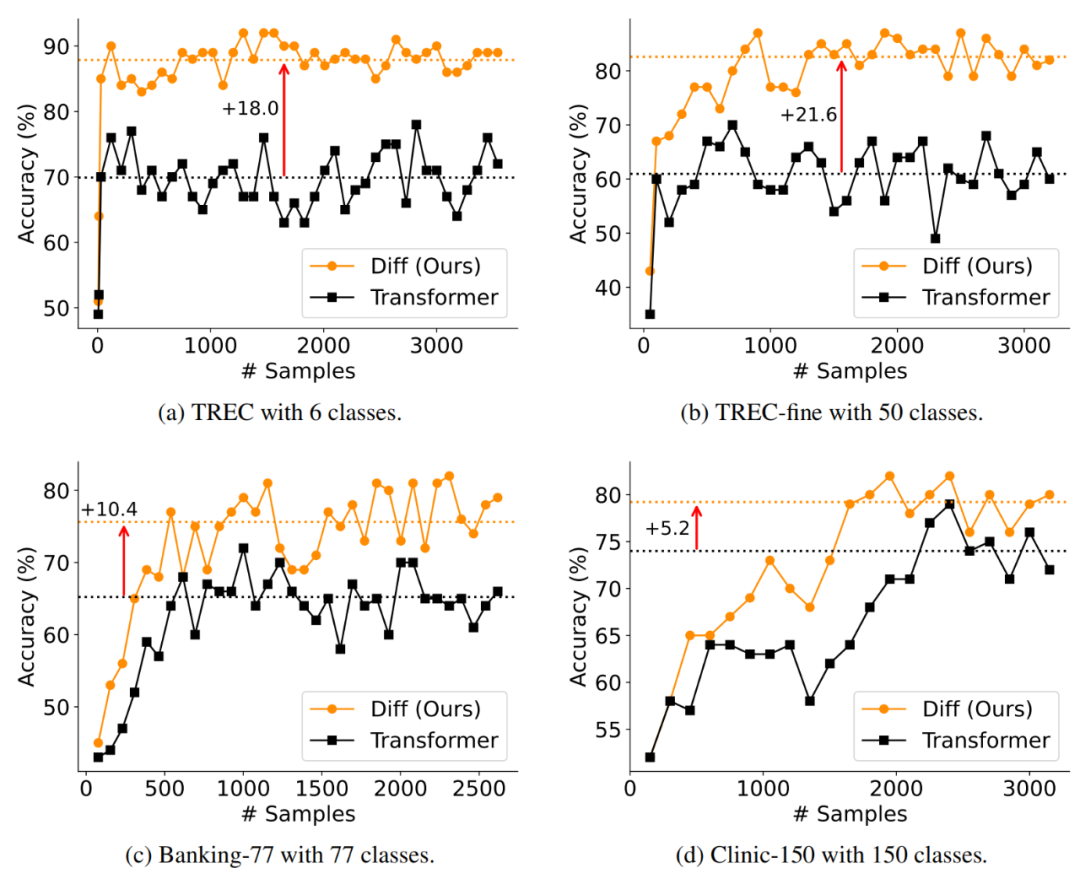
在鲁棒性测试中,作者通过打乱示例顺序的方式评估了模型的性能稳定性。如图 7 所示,DIFF Transformer 在不同示例排列下的性能方差显著低于 Transformer,表明其对输入顺序的敏感性更低,具有更强的鲁棒性。
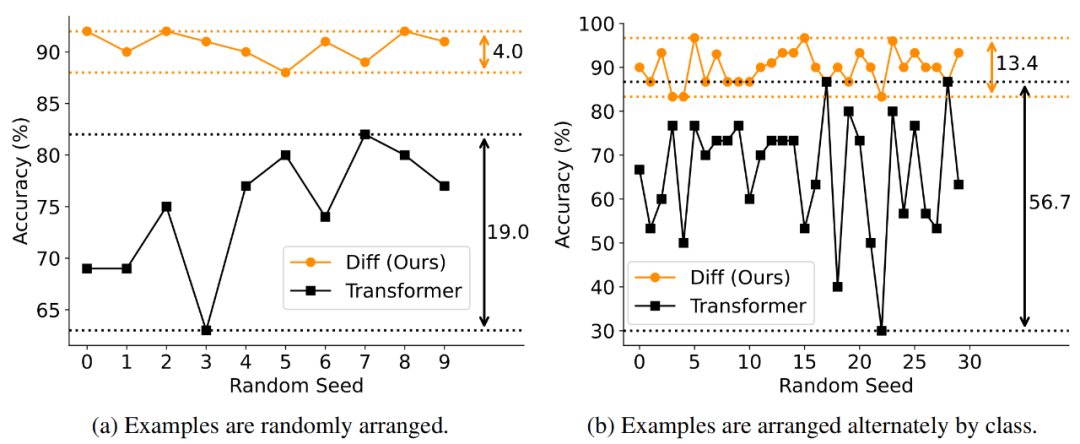
图 7. 样本顺序鲁棒性测试

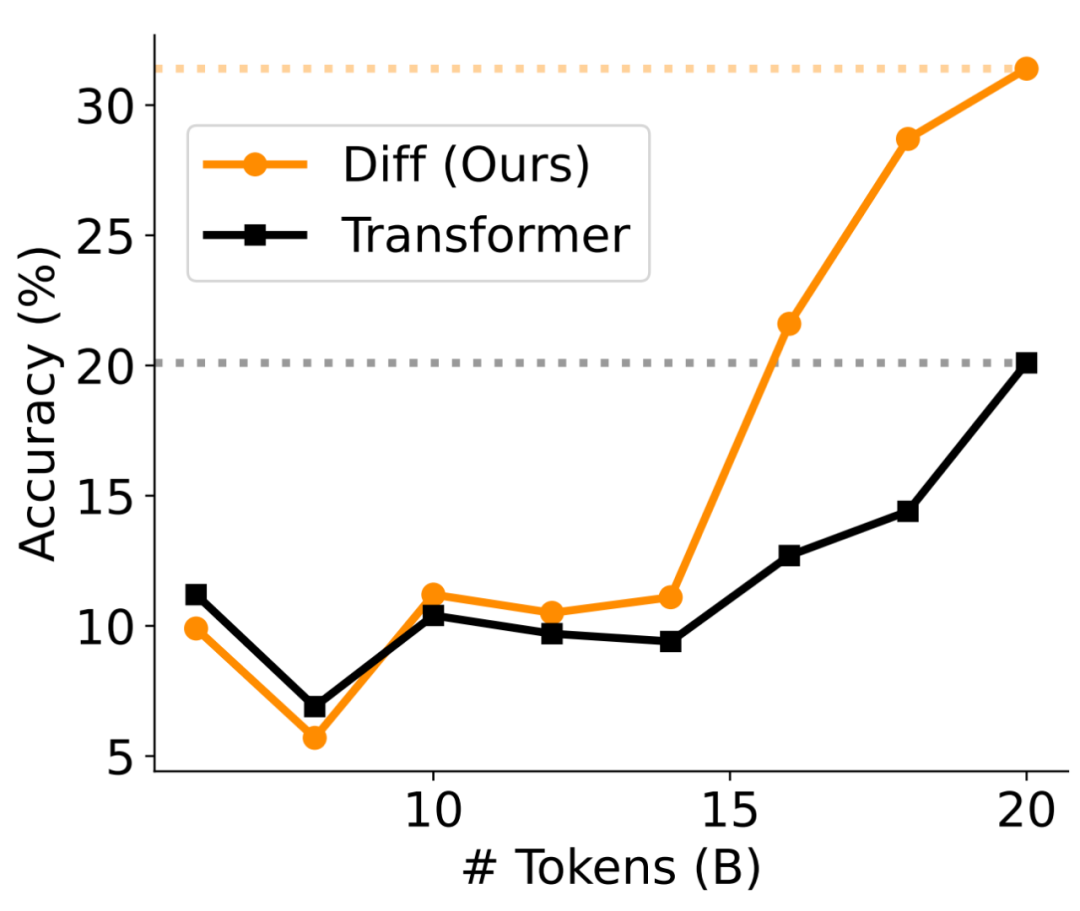
在第二阶段,作者利用 Deepseek-R1 输出所构造的数据集 OpenThoughts-114K-Math 对模型进行蒸馏,使模型更强大的深度推理能力。如图 11 所示,在 8 个数据集上,DIFF Transformer 相较 Transformer 均有不同程度的提升,平均准确率提升了 7.5%,这表明差分注意力机制更强大的上下文建模能力在推理任务中也至关重要。
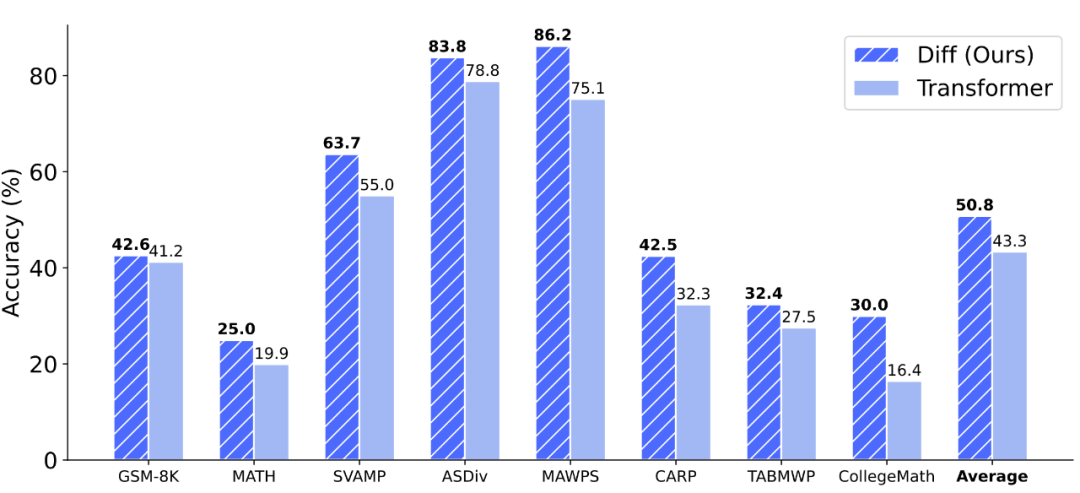
图 11. 第二阶段深度推理能力评测
讨论与未来工作
DIFF Transformer 自发布以来获得了较大关注与讨论。作者在 Hugging Face 论文讨论平台、alphaXiv 平台上与社区开展了深入的探讨。在 X 平台(原 Twitter)上,Google DeepMind 高级研究科学家(Senior Staff Research Scientist)Petar Veličković 与作者就文章中的理论分析展开讨论,ViT 核心作者 Lucas Beyer 也在阅读文章后撰写了一篇深入的论文总结,相关发帖已获得数十万浏览。目前 DIFF Transformer 也已集成至 Hugging Face 的 transformers 库中。
-
Hugging Face:https://huggingface.co/papers/2410.05258
-
alphaXiv:https://www.alphaxiv.org/abs/2410.05258v1
-
Petar Veličković:https://x.com/PetarV_93/status/1874820028975267866
-
Lucas Beyer:https://x.com/giffmana/status/1873869654252544079
-
transformers库:https://github.com/huggingface/transformers/tree/main/src/transformers/models/diffllama
未来工作方面,作者认为可以利用 DIFF Transformer 的性质设计低比特注意力算子,以及利用差分注意力的稀疏特性进行键值缓存(key-value cache)的剪枝。此外,将 DIFF Transformer 应用在除语言以外的其他模态上也值得探索。近期工作 DiffCLIP 将差分注意力扩展至视觉、多模态领域,揭示了 DIFF Transformer 在不同模态任务中的更多结构特性与应用潜力。
-
DiffCLIP:https://arxiv.org/abs/2503.06626
总结
本文的贡献主要在两个方面:
(1)DIFF Transformer 通过创新的差分注意力机制,有效解决了传统 Transformer 在处理文本时受到噪声干扰、注意力分配不准确的问题;
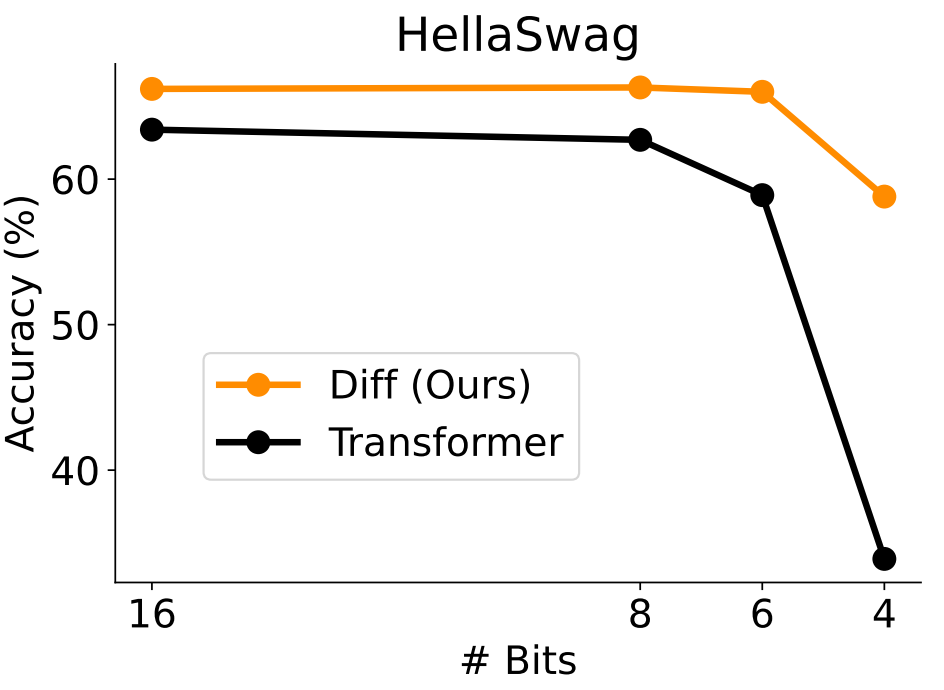
(2)凭借对关键信息的关注和对噪声的抵御能力,DIFF Transformer 在语言建模、长文本建模、关键信息检索、数学推理、对抗幻觉、上下文学习、模型激活值量化等任务中表现出色,有望在自然语言处理、多模态等领域作为基础模型架构。

©
(文:机器之心)