


本文作者均来自中兴通讯无线研究院「大模型深潜」团队。团队重点攻关方向包括「推理模型构建:蒸馏与强化学习方法」、「无线通信故障定位与根因分析推理模型」、「多模态推理模型」和「推理加速技术」。核心成员毕业于中国科学技术大学、中国科学院软件研究所等知名高校与科研院所。
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。
中兴通讯无线研究院「大模型深潜团队」从 「数据静态经验流」 的角度切入,首创 「LLM 自适应题目难度蒸馏」 方法,一举将高质量 CoT 语料的生产效率与效果同步拉满。

-
论文标题:Rethinking the Generation of High-Quality CoT Data from the Perspective of LLM-Adaptive Question Difficulty Grading
-
论文链接:https://arxiv.org/pdf/2504.11919
开源链接如下:
-
代码数据:https://huggingface.co/datasets/ZTE-AIM/32B_LLM_AdaptiveCode_data
-
数学数据:https://huggingface.co/datasets/ZTE-AIM/32B_LLM_AdaptiveMath_data
-
代码模型:https://huggingface.co/ZTE-AIM/LLM-Adaptive-ZCode-model-32B
-
数学模型:https://huggingface.co/ZTE-AIM/LLM-Adaptive-ZMath-model-32B
研究动机:小模型也想有「长链思考」
大模型优势鲜明,部署困难
随着 DeepSeek-R1(671B 参数)模型的发布,长思维链(CoT)推理技术在基础大模型和工业应用中快速普及。DeepSeek-R1 虽然推理能力强大,但 600+B 参数量的模型难以在边缘设备、实时系统中使用。
小模型亟待「加持」
这促使业界对参数量低于 70 亿的小型模型开展持续研究,尤其聚焦在复杂数学解题和代码生成等长链推理场景。值得注意的是,借助 DeepSeek-R1 的推理过程,可构建高质量的思维链(CoT)数据,从而显著增强小模型的推理能力。但目前几十亿到百亿参数级别的小模型,在多步骤推理任务(如复杂数学问题和编程题)上仍存在明显瓶颈,难以充分满足此类应用需求。
现有 CoT 数据的困局
基于 DeepSeek-R1 生成 CoT 数据的研究大体分为两条技术路线:
1. 海量数据驱动(Labs 2025;Team 2025c):通过堆叠超大规模 CoT 语料来提升推理能力,但计算与标注成本高、效率低。
2. 精品数据驱动(Ye et al. 2025;Muennighoff et al. 2025):依靠少量高质量样本激活模型潜能,然而受规模限制,性能增益难以持续。
尽管已有工作(Wen et al. 2025a)引入课程学习和拒绝采样以优化训练流程,上述方法普遍忽视了「模型能力 — 数据难度」之间的动态匹配。
这直接引出了两个核心问题:
1、高质量 CoT 语料应如何定义?
2、如何从既有数据中提炼可迁移的「静态经验流」?
全新方法:模型自适应难度分级蒸馏
近期,强化学习之父 Richard Sutton 提出「经验」是下一代超级数据源的思想,将大模型强化学习的本质定义为是一种数据的动态经验流挖掘。基于此,我们团队从数据静态经验流建设的角度出发,提出基于模型自适应问题难易度蒸馏 CoT 语料的方法,显著提升了长 CoT 语料的质量。
该方法围绕「模型 – 数据动态匹配」提出了一条完整的 CoT 构建流程,具有四大创新点:
1. 基于模型的固有推理能力,建立题目难度分级体系,形成可复用的「静态经验」。
2. 依照难度标签,构建覆盖全梯度的自适应题库。
3. 设计符合课程学习思想的难度分布采样策略,确保训练数据与模型能力实时对齐。
4. 借助 DeepSeek-R1,在数学推理与代码生成两大场景批量生成高质量 CoT 语料。
在相同计算预算下,该自适应方案可持续提升不同规模模型的推理性能 —— 以 AIME24 数学竞赛数据集为例,各参数档模型的准确率相比传统「非适配」策略提高 6.66 %–26.7 %(见图 1)。
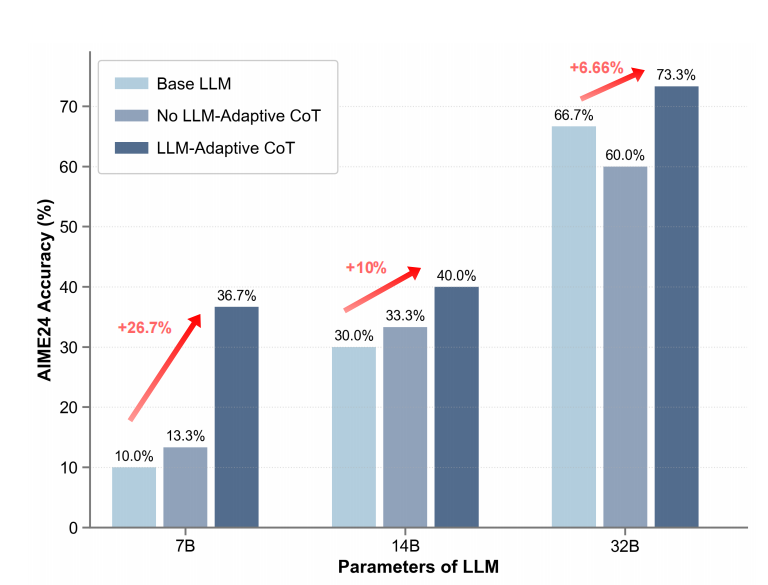
图 1:基于 LLM 自适应题目难度分级的 CoT 数据构建效果对比
对于不同参数规模的 LLM,采用问题自适应难度分级方法构造的 COT 数据训练的推理模型(左)在数学竞赛数据集 AIME24 上的推理性能始终优于非自适应方法(右)。说明了前者构建的 CoT 数据质量更高,并且找到了适配于模型的静态数据经验流。
这一方法有效地挖掘了 CoT 数据中的静态经验流,并且该静态经验流与模型本身是密切相关的。
方法框架,一图看懂
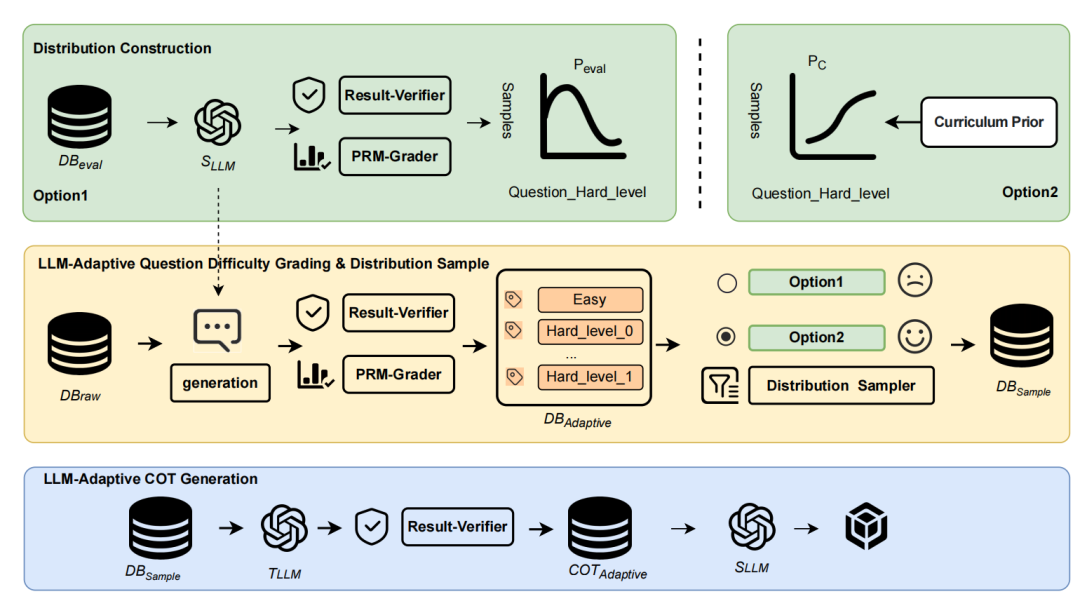
图 2:基于 LLM 自适应题目难度分级的 CoT 数据生成框架
框架包含三个核心组件:分布构建、LLM 自适应题目难度分级与分布采样,以及 LLM 自适应思维链(CoT)生成。
1. 分布构建(Distribution Construction)
构建两种难度分布策略,作为后续采样的依据:
Option1:基于模型实际表现的分布(Pₑᵥₐₗ)
通过基础 LLM(Sₗₗₘ)在评估数据集(DBₑᵥₐₗ)上的表现动态生成难度分布:
-
正确回答的题目:标记为「简单」(Easy)。
-
错误回答的题目:通过 PRM-Grader(过程奖励模型)进一步分级,根据模型生成答案的推理轨迹质量(0-1 分)映射到 5 个难度等级(分数越低,难度越高)。
Option2:基于课程学习的先验分布(P₆)
人工定义五级难度,遵循「易题多、难题少」的分布原则,权重随难度递增递减:
例如,难度级别 1 的样本数最多,级别 5 最少。
2. LLM 自适应题目难度分级与分布采样
步骤 1:构建自适应题库(DBₐdₐₚₜᵢᵥₑ)
从开源数据集收集原始题目(DBᵣₐw),利用 Sₗₗₘ生成回答并记录推理轨迹。
验证答案正确性:
-
数学推理任务:直接对比模型答案与标准答案。
-
代码生成任务:通过测试用例执行验证代码正确性。
难度分级:
正确题目标记为「简单」,加入题库。
错误题目通过 PRM-Grader 细分为 5 级难度(1-5 级,1 级最难),加入题库。
步骤 2:分布采样(DBₛₐₘₚₗₑ)
根据构建的分布(Pₑᵥₐₗ或 P₆),从自适应题库中按难度比例采样题目
3. LLM 自适应 CoT 生成
-
生成阶段:将采样题目(DBₛₐₘₚₗₑ)输入教师模型(Tₗₗₘ,即 DeepSeek-R1)生成详细推理链(CoT)。
-
验证阶段:通过 Result-Verifier 严格筛选正确 CoT 数据(与步骤 2 的验证方法一致),最终形成高质量数据集 COTₐdₐₚₜᵢᵥₑ。
-
模型训练:利用 COTₐdₐₚₜᵢᵥₑ对基础模型(Sₗₗₘ)进行监督微调(SFT),得到优化后的推理模型(Rₗₗₘ)。
方法的关键创新点:
-
模型自适应难度适配:基于模型实际能力调整题目难度分布,避免「一刀切」的主观分级,构建真正与模型密切绑定的静态数据经验流;
-
轻量化流程:无需复杂课程学习或拒绝采样,仅通过分级与采样即可提升数据质量;
-
多任务兼容性:支持数学推理与代码生成任务,验证方法灵活(答案对比 / 测试用例)。
实验效果:惊喜不断
为了研究我们提出的 CoT 数据的质量效果,我们在不同尺寸和性质的模型上均进行了详细的验证,涵盖的任务包括数学推理任务和代码生成任务。
以下是重要实验结果的详细介绍:
数学推理(MATH500、AIME24/25、GPQA)
-
在 MATH500、AIME24/25、GPQA 等数学基准测试中,采用 2k 自适应 CoT 数据训练的 ZMath 系列模型显著优于基线模型。
-
ZMath-32B 在 MATH500 上达到 94.6% 准确率,超过 DeepSeek-Distill-32B(89.8%)和 Sky-32B-Preview(90%);在 AIME24 上提升至 73.33%(基线为 66.67%)。
-
ZMath-14B 在 AIME24 上准确率为 50%,远超 phi4-14B(30%),并在 GPQA 上达到 63.13%(phi4-14B 为 54.55%)。
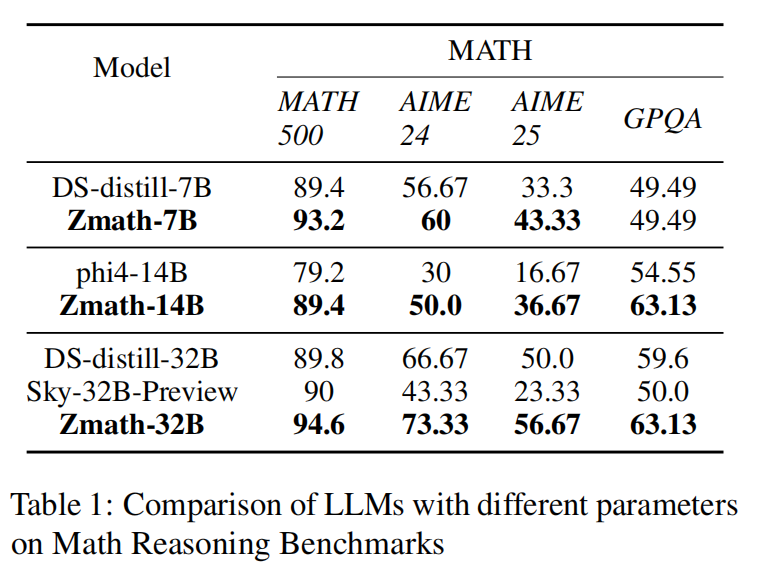
图 3:数学推理实验结果
代码生成(LiveCodeBench)
-
ZCode-32B 在 Easy、Medium、Hard 三个难度级别上分别达到 96.06%、75.53%、31.85%,全面优于 DeepSeek-Distill-32B(92.11%、74.92%、30%)。
-
ZCode-14B 在 Easy 难度上以 89.96% 显著领先 phi4-14B(72.4%),表明小参数模型通过自适应数据训练也能取得竞争力表现。
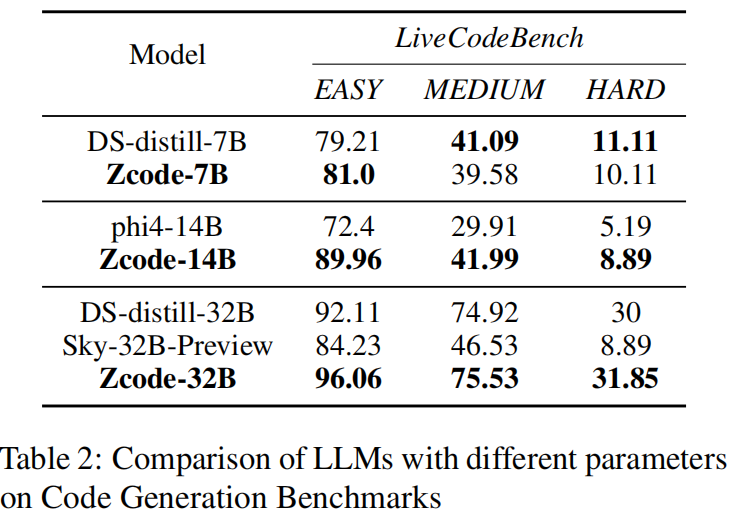
图 4:代码生成实验结果
消融实验&分布迁移
当把 32B 模型的难度分布直接套用到 7 B 模型时,后者在 MATH500 数据集上的准确率仅为 92%,低于采用自身难度分布训练得到的 93.2%。结果说明:难度分布必须与目标模型能力动态匹配,自适应分布才是性能提升的关键;同时也表明,静态经验流中真正有价值的经验应当与具体模型紧密对应,而非「一刀切」地跨模型迁移。
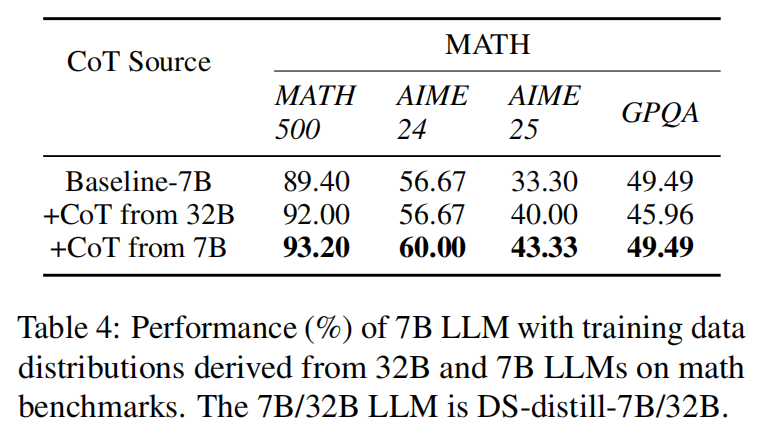
图 5:代码生成实验结果
总结与展望
论文提出了一套基于 LLM 自适应难度分级的高质量 CoT 数据生成框架,并通过系统实验验证了其效率、有效性与泛化能力。核心结论如下:
-
高效数据生成
先动态评估模型当前推理能力,再构建匹配的自适应题库,仅凭约 2 k 条高质量 CoT 样本即可显著提升性能,显著降低数据与算力成本。
-
跨任务与参数泛化
在数学推理(AIME 系列)与代码生成(LiveCodeBench)两大场景中均取得领先表现;对 7 B–32 B 不同规模模型均能带来稳定增益。
-
方法论贡献
构建了一套系统化的 CoT 数据生成与评估流程,为资源受限环境下的小参数 LLM 提升链式推理能力提供了新路径,也为「静态经验流」挖掘给出了可复用范式。
未来工作:进一步结合强化学习挖掘深层推理能力,并扩展至通信故障诊断等更复杂的跨领域任务。
©
(文:机器之心)