


极市导读
在ImageNet 256×256 生成上实现了最佳 (SOTA) 性能,FID得分为1.35,同时在短短64个epoch内就达到了2.11的FID得分,展现了卓越的训练效率——与原始DiT相比,收敛速度提高了21倍以上。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
在训练 VAE 的时候使用 REPA 方法。
本文是一篇研究 VAE 的文章。VAE 现在广泛用在了 Latent diffusion model 架构里面,用来去生成高保真图像。但是,最近一些研究发现这种两阶段设计存在优化困境:增加 tokenizer 的 feature dimension 可以提高重建 (Reconstruction) 质量,但会损害生成 (Generation) 能力,这就需要更大的扩散模型和更多的训练才能达到相当的生成能力。
因为这个优化困境的问题,现在的系统通常要么由于 tokenizer 内的信息丢失而产生视觉伪影,要么因为计算成本的问题而无法完全收敛。本文认为这种困境源于:VAE 在训练的时候,如果把 feature dimension 开得比较高,那么高维度 latent space 在优化的时候缺乏约束,因而学好这个特征就比较困难。
本文提出的解决方案 VA-VAE 的做法是:在训练 Tokenizer 的时候把特征对齐 Vision foundation model。其实就是相当于把 REPA 用在了 VAE 的训练上,使 DiT 在高维 latent space 收敛更快。
为了利用 VA-VAE 的全部潜力,作者构建了一个增强的 DiT baseline,改进了训练策略和架构设计,称为 LightningDiT。在 ImageNet 256×256 生成上实现了最先进的 (SOTA) 性能,FID 得分为 1.35。同时,仅 64 个 Epoch 就可以达到 2.11 的 FID 分数,展现出显著的训练效率提升:与原始 DiT 相比,表现出 21 倍收敛速度。
本文目录
1 VA-VAE:解决 LDM 重建 vs. 生成的优化困境
(来自华中科技大学)
1 VA-VAE 论文解读
1.1 VA-VAE 研究背景
1.2 VA-VAE 方法介绍
1.3 边际余弦相似度损失函数
1.4 边际距离矩阵相似性损失函数
1.5 自适应权重
1.6 LightningDiT:改进的 Diffusion Transformer
1.7 实验设置
1.8 实验结果
1 VA-VAE:解决 LDM 重建 vs. 生成的优化困境
论文名称:Reconstruction vs. Generation:Taming Optimization Dilemma in Latent Diffusion Models (CVPR 2025)
论文地址:
http://arxiv.org/pdf/2501.01423
代码链接:
http://github.com/hustvl/LightningDiT
1.1 VA-VAE 研究背景
Latent diffusion model (LDM) 通常是利用一个连续的 variational autoencoder (VAE) 或者 visual tokenizer 来压缩视觉信号,从而减少高分辨率图像生成的计算需求。visual tokenizer 的性能,特别是它们的压缩和重建能力,对于整体系统的有效性起至关重要的作用。
一种直接增强重建能力的方法是增加 visual tokenizer 的 feature dimension,可以有效地扩大 latent 表征信息的能力。
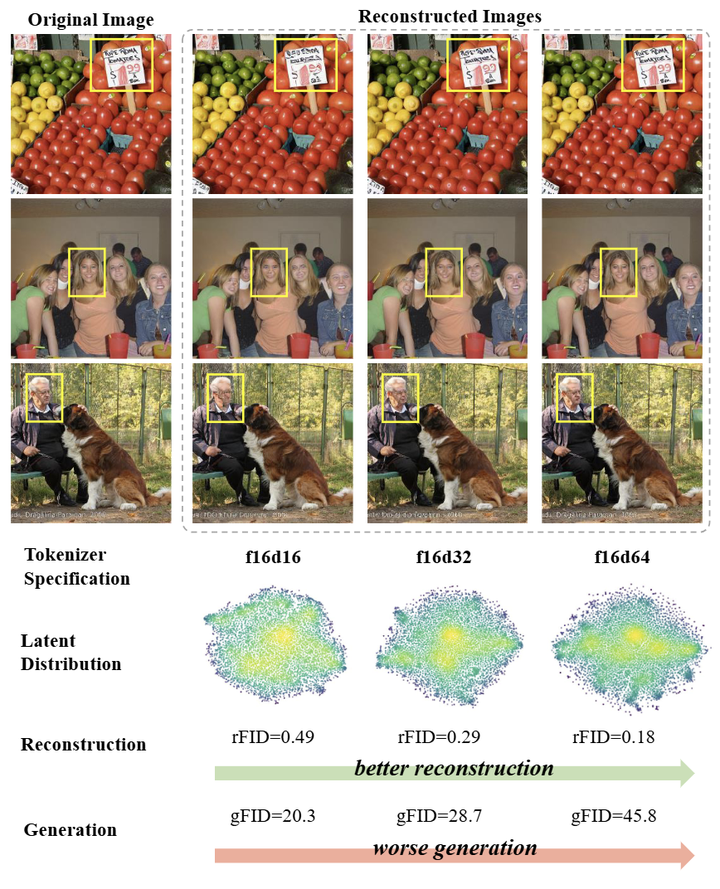
随着研究的先进,latent diffusion model 的重建和生成性能之间出现了优化困境:虽然增加 feature dimension 可以提高 tokenizer 的重建精度,但它显着降低了生成性能,如图 1 所示。目前,存在两个常见的策略来解决这个问题:
-
增加模型参数,比如 Stable Diffusion 3。这表明高维 tokenizer 可以以更大的模型容量实现更强的生成性能。但是,这种方法需要更多的训练计算,这使得它在大多数实际应用中非常昂贵。
-
故意限制分词器的重构能力,例如 Sana、W.A.L.T,为了更快地收敛扩散模型训练。但是,这种受损的重建质量会固有地限制了生成性能的上限,导致生成结果中的视觉细节不完善。
这两种方法都涉及固有的权衡,并没有提供对底层优化困境的有效控制。
本文提出一种简单而有效的方法来解决这种优化困境。
作者从 Auto-Regressive (AR) 生成中汲取灵感,即:增加 discrete VAE 的 codebook 大小会导致 codebook 利用率变低。通过可视化不同 feature dimension 的 latent 空间分布 (图 1),作者观察到高维 tokenizer 的分布可视化中更集中于高强度区域。这个分析表明,优化困境源自学习没有约束的高维 latent 空间是比较困难的。
为了解决这个问题,本文在 LDM 中为连续 VAE 开发了一种 vision model 引导的优化策略。结果表明,在保留其原始重建能力的同时,学习视觉 vision model 引导的 latent 表征显著提高高维 tokenizer 的生成能力 (图 2)。

1.2 VA-VAE 方法介绍
VA-VAE 是一种通过 vision foundation model 训练视觉 tokenizer 的方法,具体是通过 REPA 的表征对齐策略。VA-VAE 利用基础模型的特征空间来约束 tokenizer 的 latent 空间,来增强其对生成任务的适用性。
如图 3 所示,VA-VAE 的架构和训练过程主要遵循 LDM,使用具有连续 latent 空间的 VQGAN 架构,受 KL Loss 约束。VA-VAE 的主要贡献是设计了 Vision Foundation model 对齐的 Loss:VF Loss,在不改变模型架构或 training pipeline 的情况下大大优化了 latent 空间,高效地解决了优化困境。
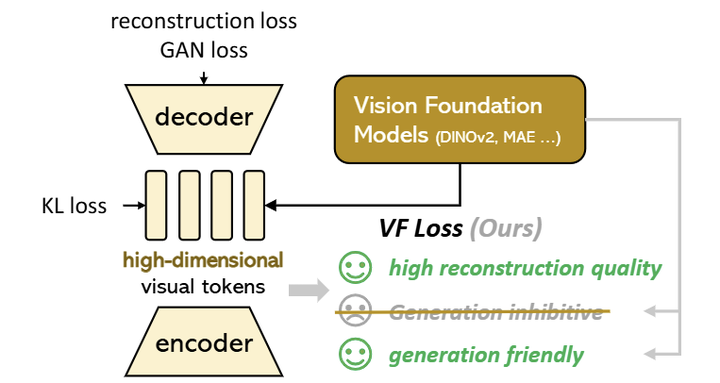
VF 损失由两部分组成:边际余弦相似度损失函数 (marginal cosine similarity loss) 和边际距离矩阵相似性损失函数 (marginal distance matrix similarity loss)。这些组件是一个可以即插即用的模块,与 VAE 架构解耦。
1.3 边际余弦相似度损失函数
在训练期间,给定的图像 由视觉 tokenizer 的 Encoder 和冻结的 vision foundation model 处理。Encoder 输出图像 latent ,视觉基础模型输出视觉表征 。如式 1 所示,使用线性变换投影 来匹配 的维度,其中 ,得到 :

如式 2 所示,损失函数 力求各空间位置 的特征矩阵 和 对应特征 和 之间的相似度差距最小。对于每一对,计算余弦相似度 并减去一个 margin 函数确保只有相似度低于 的才会对损失函数起作用。这里的意思是希望损失函数聚焦在相似度低于 的项。最终损失在 的所有位置进行平均。
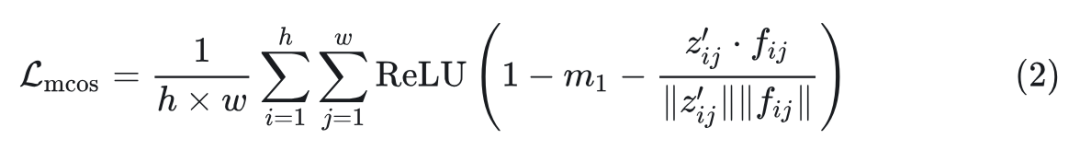
1.4 边际距离矩阵相似性损失函数
损失函数 聚焦的是 Encoder 的输出 和视觉表征 点对点的相似度。作者还期待特征内的相对分布距离矩阵尽可能相似。边际距离矩阵相似性损失函数就是为了实现这一目的。
如式 3 所示,边际距离矩阵相似性损失函数对齐特征矩阵 和 的内部分布。式中, 表示特征图中的元素总数。对于每个对 ,计算特征矩阵 和 中对应向量之间的余弦相似度差的绝对值,从而促进其相对结构的更紧密对齐。类似地,减去 margin 来放松约束。ReLU 函数确保只有差异超过 margin 的项才有助于损失。
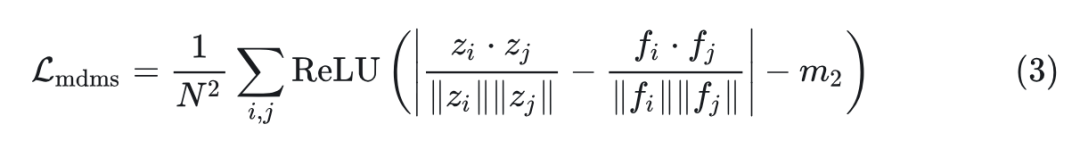
1.5 自适应权重
在图 3 中,Reconstruction Loss 和 KL Loss 都是加和性质的 Loss,这样一来,VF Loss 就变成了不同量级的值,使得调整权重以进行稳定训练具有挑战性。作者采用了自适应加权机制。在反向传播之前,计算 和 对 Encoder 最后一个卷积层的梯度,如式 4 所示。自适应加权设置为这两个梯度的比例,确保 和 对模型优化的影响相似。这种对齐显着减少了 VF 损失的调整范围。
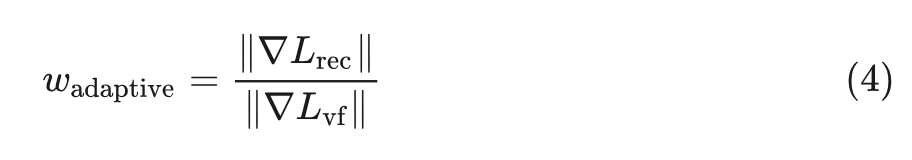
具有自适应加权的 VF Loss 如式 5 所示。自适应加权的目的是快速对齐不同 Loss 的尺度。在此基础上,仍然可以使用手动调整的超参数来进一步提高性能。
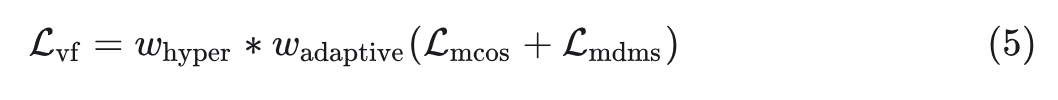
1.6 LightningDiT:改进的 Diffusion Transformer
在这一节中,作者探索了 DiT 架构和训练策略的优化,希望看看 DiT 能力的边界。作者使用 SD-VAE (f8d4),DiT-XL/2 模型作为验证。实验结果如图 4 所示。
对于 Diffusion 优化,作者使用 Rectified Flow、logit normal distribution (lognorm) 采样和 velocity direction loss。在模型架构级别,应用了常见的 Transformer 优化,包括 RMSNorm、SwiGLU 和 RoPE。在训练期间,观察到一些加速策略不是正交的。例如,梯度裁剪仅在单独使用时有效,但在使用 lognorm sampling 和 velocity direction loss 后会损失性能。
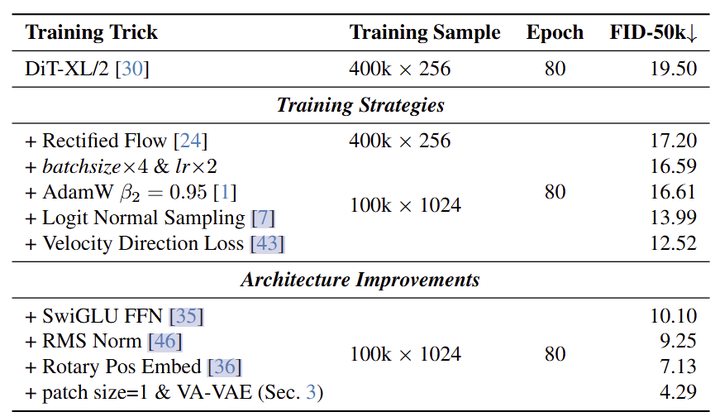
优化后的模型 LightningDiT 在 ImageNet class-conditional 生成上达到了 7.13 (cfg=1),SD-VAE 在 80 Epoch 左右,仅为原始 DiT 和 SiT 模型 6% 的训练时间 (1400 Epoch)。这些结果表明,即使没有任何复杂的 training pipeline,DiT 仍然可以实现非常有竞争力的性能。
1.7 实验设置
对于 visual tokenizer,本文主要遵循 LDM 的架构和策略。具体来说,作者利用 VQGAN 网络结构,省略量化并应用 KL Loss 来调节连续的 latent 空间。作者训练了 3 个不同的 tokenizer:一个没有 VF Loss,一个使用 VF Loss(MAE),另一个使用 VF Loss(DINOv2)。这里 表示下采样率, 表示 latent 维度。根据经验,设置 。生成模型直接采用 LightningDiT。
从 tokenizer 中提取所有 latent 特征,并在 ImageNet 上训练各种版本的 LightningDiT,分辨率为 256。将 DiT 的 patch size 设置为 1,确保整个系统的下采样率为 16。这种方法与 DC-AE 中提出的策略一致,即所有压缩步骤都由 VAE 处理。
1.8 实验结果
基础模型改善收敛
图 5 显示了对8种不同 tokenizer 的重建和生成的评估,所有生成模型在 ImageNet 上训练了 160 Epoch (LightningDiT-B) 或 80 Epoch (LightningDiT-L 和 LightningDiT-XL) 。有以下发现:
结果突出了 LDM 的优化困境。蓝色突出显示的结果说明了重建性能 (rFID) 和相应的生成性能 (FID)。可以观察到,随着 tokenizer 维度的增加,rFID 减小,而相应的生成 FID 增加。
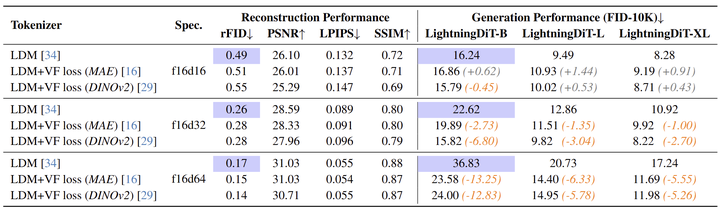
VF Loss 可以有效提高高维 tokenizer 的生成性能。在 f16d32 和 f16d64 部分中,VF Loss (DINOv2) 和 VF Loss (MAE) 都显着提高了 DiT 在不同尺度上的生成性能。这使得实现具有更高重建性能和更高生成性能的系统成为可能。然而,值得注意的是,低维 tokenizer (比如 f16d16) 不需要 VF Loss。作者认为这是因为低维空间可以在不需要额外的监督信号的情况下学习更合理的分布。
此外,作者在图 6 (a) 和 (b) 中展示了 FID 相对于训练时间的收敛图。在 f16d32 和 f16d64 上,VF Loss 分别加速了 2.54 和 2.76 倍的收敛,表明 VF Loss 可以显著提高高维 tokenizer 的生成性能和收敛速度。
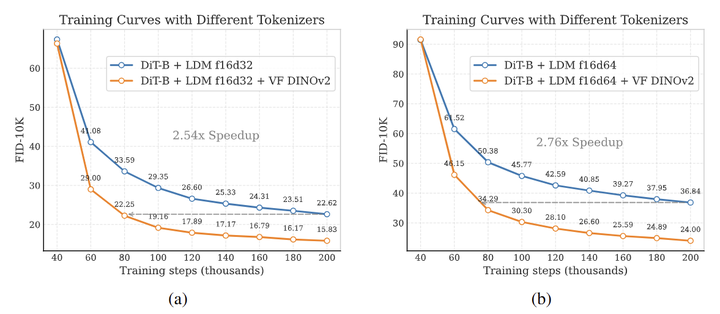
基础模型改善缩放性能
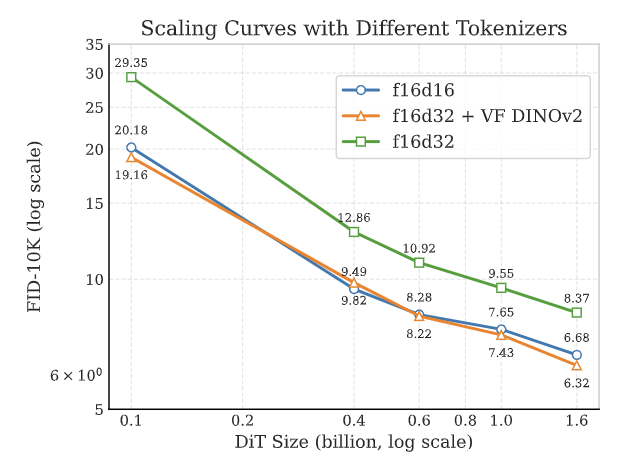
增加模型参数量是提高高维 tokenizer 生成性能的方法之一。
作者用大小从 0.1B 到 1.6B 的 LightningDiT 模型来评估 3 个不同的 tokenizer 的生成性能。采用对数标度。
可以观察到到随着参数量的增加,蓝线和绿线之间仍然存在显着差距。这意味着即使在 1.6B 的参数量级,高维 f16d32 tokenizer 对生成的负面影响也没有完全缓解。而 1.6B 的参数量对于 ImageNet 而言已经很大。作者发现 VF Loss 可有效弥合了这一差距。当模型规模超过 1B 时,f16d32 + VF DINOv2 的性能逐渐与 f16d16 拉开差距,展示出可扩展性。
收敛速度
作者发现 VF Loss (DINOv2) 在生成性能方面带来了最显著的改进。因此,作者扩展了 tokenizer 的训练时间,并采用渐进式训练策略来训练 LDM VF Loss (DINOv2) 125 Epoch。训练 LightningDiT-XL 800 Epoch。具体来说,在 480 Epoch 时禁用 lognorm 参数,以使接近收敛的网络能够在所有噪声区间中更有效地学习。在采样过程中,使用 250-step Euler integrator。为了提高采样性能,采用类似于 FLUX 的 cfg interval 和 timestep shift。
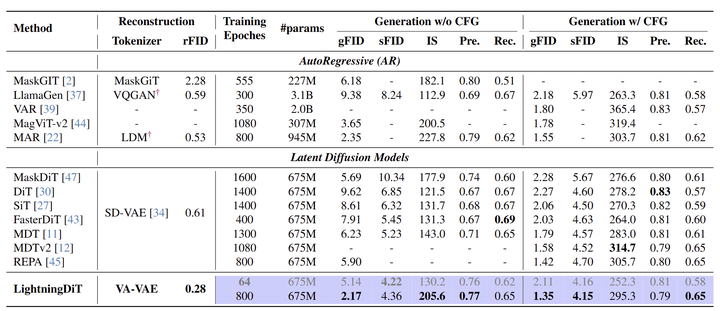
实验结果如图 9 所示,本文模型训练了 800 Epoch 之后,模型实现了最先进的性能,FID 为 1.35。此外,模型在不使用 cfg 生成方面表现出卓越的性能,实现了 2.17 的 FID,超过了许多使用 cfg 的方法的结果。
本文也展示出了很快的收敛速度:在 64 Epoch 时,实现了 2.11 的 FID,与原始 DiT 相比,实现了超过 21 倍的加速。
(文:极市干货)