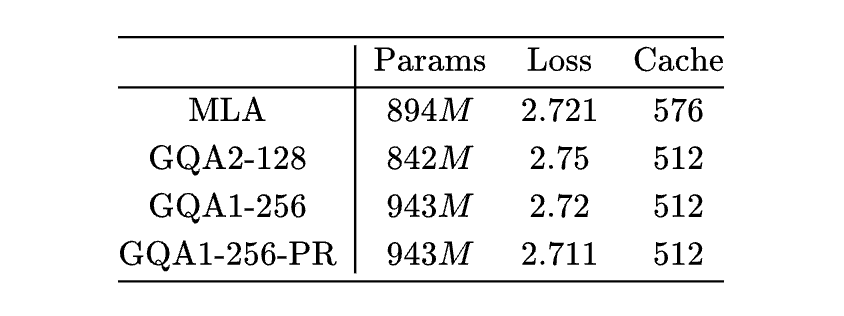
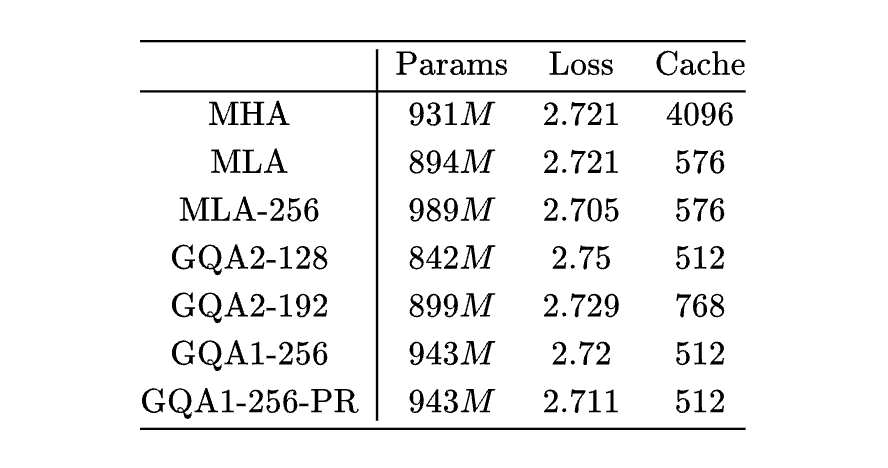
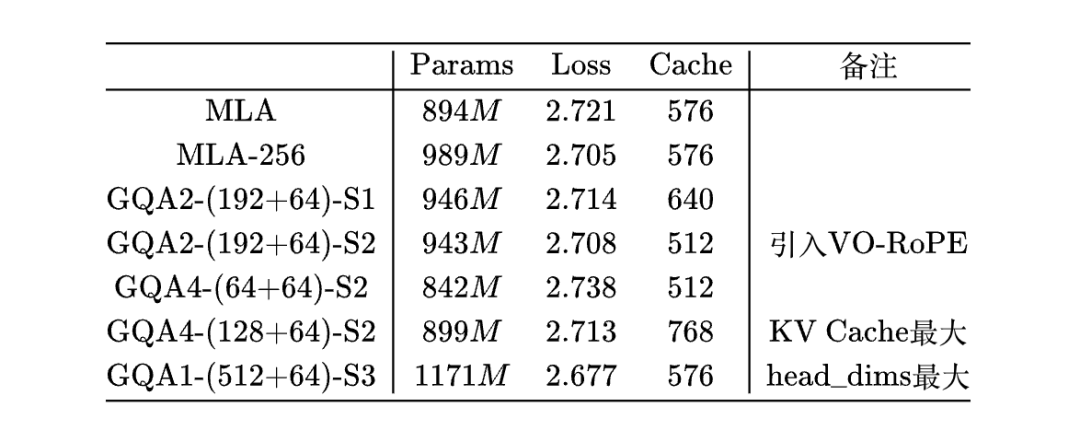
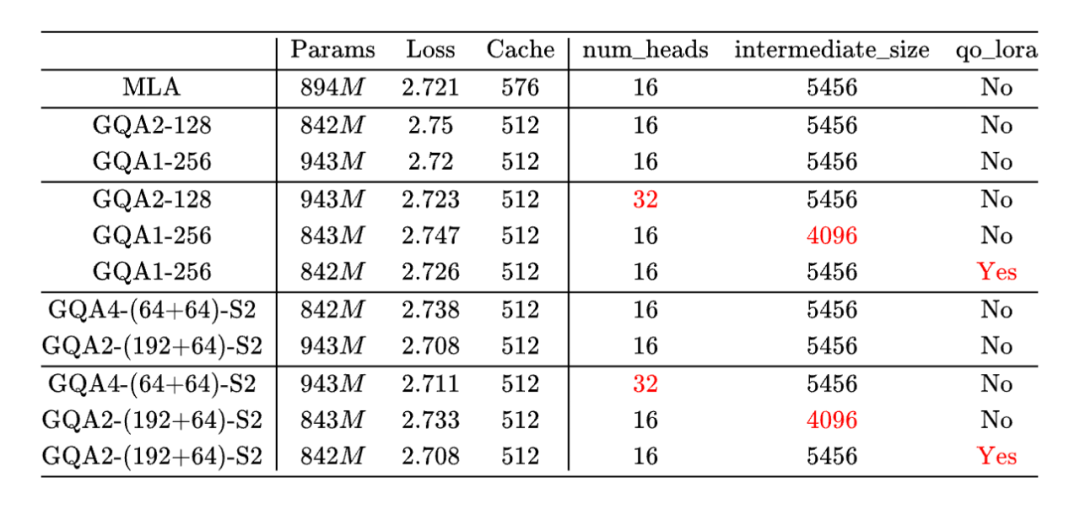
Transformer升级之路:多头潜在注意力机制(MLA)究竟好在哪里? 下午4时 2025/05/22 作者 PaperWeekly ©PaperWeekly 原创 · 作者 | 苏剑林 单位 | 科学空间 研究方向 | NLP、神经网络 自从 DeepSeek 爆火后,它所提的 Attention 变体 MLA(Multi-head Latent Attention)也愈发受到关注。 MLA 通过巧妙的设计实现了 MHA 与 MQA 的自由切换,使得模型可以根据训练和推理的不同特性(Compute-Bound or Memory-Bound)选择最佳的形式,尽可能地达到效率最大化。 诚然,MLA 很有效,但也有观点认为它不够优雅,所以寻找 MLA 替代品的努力一直存在,包括我们也有在尝试。 然而,经过一段时间的实验,我们发现很多 KV Cache 相同甚至更大的 Attention 变体,最终效果都不如 MLA。这不得不让我们开始反思:MLA 的出色表现背后的关键原因究竟是什么? 接下来,本文将详细介绍笔者围绕这一问题的思考过程以及相关实验结果。 观察 MLA 提出自 DeepSeek-V2 [1],本文假设读者已经熟悉 MLA,至少了解之前的文章缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA所介绍的内容,因此 MLA 自身的细节将不会过多展开。 MLA 的主要特点如下: 1. MLA 在训练阶段是一个 qk_head_dims=(128+64)、v_head_dims=128 的 MHA; 2. MLA 在解码阶段是一个 qk_head_dims=(512+64)、v_head_dims=512、KV-Shared 的 MQA; 3. MLA 的 [qc, qr]、[kc, kr] 拼接,可以理解为一种Partial RoPE。 猜测 MHA、GQA 常用的 head_dims 是 128,而对于 MLA 来说,不管是从训练看的 128+64,还是从推理看的 512+64,都要大于 128,再结合《突破瓶颈,打造更强大的 Transformer》[2] 的经验,我们有: 猜测 1:增大 head_dims 是 MLA 好的关键之一。 另外,KV-Shared 这个特性,可以在同等 KV Cache 大小下,增大 GQA 的 head_dims 或者 num_groups,所以有: 猜测 2:KV-Shared 是 MLA 好的关键之一。 最后,此前有一些理论和实验显示 Partial RoPE 可能会对效果有正面帮助(参考Transformer升级之路:RoPE的底数选择原则),所以有: 猜测 3:Partial RoPE 是 MLA 好的关键之一。 实验 现在我们通过实验逐一检验以上猜测。 设置 所有实验公共部分的超参数如下: 1. 类似 LLAMA3 的 Dense 模型; 2. hidden_size=2048,num_layers=12,num_heads=16; 3. 优化器是Muon,Attention 部分 per head 更新; 4. 训练长度为 4096,总 tokens 数为 16B,总训练步数为 16k; 5. 所有实验都是只改变 Attention,所以参数量不会严格对齐。 Part I MLA 的 KV Cache 大小是 512+64,约等于 GQA2-128(第一个数字是 num_groups,第二个数字是 head_dims),所以对比的 baseline 为 GQA2-128 和 GQA1-256。 为了验证 Partial RoPE,我们增加了 GQA1-256-PR,具体做法是将 Q、K 的 256 dims 分成 192+64 两部分,在 64 上加 RoPE,192 不加。 结果如下: 即: 初步验证了增大 head_dims 和 Partial RoPE 的作用。这样看来,MLA 的设计中,RoPE 和 NoPE 拼接这部分看似无奈的设计,极有可能是它效果优异的关键原因!原论文声称 MLA 甚至优于 MHA,大概率也是因为所对比的 MHA 的 head_dims 只有 128。 Part II 为了进一步验证增大 head_dims 的作用,我们另外跑了 MHA、GQA2-192、MLA-256 三个实验,MHA 是 head_dims=128 的常规 MHA,GQA2-192 是直接增大 GQA2 的 head_dims 到 192,MLA-256 是将 MLA 的 128+64 提升到 192+64,对照如下: 可以看到,MHA 总参数量更多,KV Cache 更是 7 倍于 MLA,但 Loss 才堪堪追平 MLA,这跟 DeepSeek-V2 里边的结论接近。 此外,GQA2-192 优于 GQA2-128,但不如 GQA1-256;MLA 的 head_dims 升到 (192+64) 后,相比 (128+64) 也还能进一步提升效果。这些现象都表明,增加 head_dims 远比增加 num_groups 更有效。 Part III 接下来我们验证 KV-Shared,即 K、V 共享全部或大部分 dims。这里我们主要考虑的替代品是 head_dims 不超过 256 的 GQA,并且控制 KV Cache 的总大小跟 MLA 接近,所以当 KV-Shared 时,我们可以至多可以考虑 GQA2-256。 由于 KV-Shared 跟 RoPE 不完全兼容,参考 MLA 的做法,我们将 256 分成 192+64 两部分,其中: 1. 192 部分不加 RoPE,在 K、V 间共享; 2. 64 部分加 RoPE,只用于 K; 3. V 另外再投影 64 dims,concat 到共享的 192 dims 上去。 这样一来,K、V 的 head_dims 都是 256,KV Cache 总大小是 (192+64+64)*2=640,略大于 MLA 的 512+64=576,这个版本我们简记为“GQA2-(192+64)-S1”,其实“S1”是“Shared-1”的缩写。 Part IV 另外一种 KV-Shared 的方案是: 1. 192 部分不加 RoPE,在 K、V 间共享; 2. 64 部分加 RoPE,同样在 K、V 间共享; 3. 做 Attention,由于 V 带 RoPE,此时是绝对位置编码效果; 4. 为了保证相对位置编码,将输出分成 192+64 两部分,64 部分再加一次逆向 RoPE。 这种做法是 K、V 完全共享,KV Cache 大小是 (192+64)*2=512,略小于 MLA。这个版本我们称为“GQA2-(192+64)-S2”,“S2”是“Shared-2”的缩写,背后的原理是笔者新提出的 VO-RoPE,参考Transformer升级之路:第二类旋转位置编码 [3]。 Part V 另外,根据同样思路补了几个 GQA4 和 GQA1 的实验。所有实验结果汇总如下: 这里“GQA1-(512+64)-S3”是按照 MLA 的推理形式实现的 MQA,形式介乎 S1 与 S2 之间,它的主要特点是 head_dims 大。 结果解读: 1. KV-Shared 的 GQA 自带 Partial RoPE; 2. KV-Shared 的 GQA2-256,也能超过 MLA; 3. VO-RoPE 的引入,似乎有利于效果(S1 ≲ S2); 4. 同等 KV Cache 下,head_dims 越大越好; 5. GQA2-(192+64)-S2 略微超过 GQA1-256-PR; 6. GQA4-(128+64)-S2 的 KV Cache 最大,但效果不是最优,再次表明 head_dims 更关键。 关于 KV-Shared,还有两点观察: 1. 训练过程中,GQA1-256-PR 前期是明显领先 GQA2-(192+64)-S2,但后期被追平甚至略微反先,猜测 GQA1-256-PR 可能有后劲不足的嫌疑; 2. 如果没有 KV-Shared,GQA 顶多是 GQA1-256,也就是说 head_dims 顶天了 256,但有 KV-Shared 的话,GQA 可以做到 GQA1-512-S,单纯从 head_dims 看,KV-Shared 天花板更高。 Part VI 由于没有严格对齐参数量,可能读者会有“到底是增加参数量还是增加 head_dims 更本质”的疑虑,所以这里补充几个对齐参数量的实验。 这里考虑的对齐参数量的方式有三种: 1. double-heads:以“GQA2-128 vs GQA1-256”为例,将 GQA2-128 的 num_heads 翻倍,可以让 GQA2-128 的参数量跟 GQA1-256 相同; 2. 缩减 MLP:缩小 MLP(SwiGLU)的 intermediate_size,也可以使得 GQA1-256 的参数量跟 GQA2-128 大致相同; 3. Q&O LoRA:GQA 的主要参数量来自 Query 和 Output 的投影矩阵,对这两个矩阵改用 LoRA,也可以降低 GQA1-256 的参数量。 实验结果如下: 结果主要分三块: 1. heads 翻倍相比 head_dims 翻倍,loss 稳定差 0.003 左右; 2. 缩小 MLP 比 head_dims 减半,loss 稳定优 0.004 左右; 3. Q&O LoRA 性能损失最小,可以实现 head_dims 翻倍但参数量不增,且 loss 明显降。 结论:如果从增加参数量角度看,增大 head_dims 可能是效果增益较大的方向,配合 Q&O LoRA 可以实现参数量几乎不增,但收益仍相当。 小结 初步结论是: 1. 增大 head_dims 收益最大; 2. Partial RoPE 对 Loss 也有一定帮助; 3. KV-Shared 应该也有一定作用。 这样看来,此前我们一直在 head_dims=128 下找 MLA 的替代品,感觉是起点就先天不足了,难怪一直比不上 MLA。要想追平 MLA,head_dims 应该要 192 起步了,并辅以 Partial RoPE。至于 KV-Shared,也可能有用,但应该还需要更大规模的验证。 意义 其实这里边的意义,就看我们换掉 MLA 的决心有多强。 假设 GQA2-(192+64)-S2 可以替代 MLA,但 MLA 也可以升到 256,目前看来 GQA2-(192+64)-S2 比不上 MLA-256 。那么换掉 MLA 的唯二好处是: 1. 结构更简单,可以方便加 QK-Norm; 2. 解码阶段的 head_dims 由 512+64 变成了 256,同时 num_groups 变为 2,可以 TP。 (文:PaperWeekly)