
近日UC Berkeley大学研究人员提出了一套名为VideoMimic的框架,该框架通过日常生活中的视频,自动生成类人机器人的控制策略。该方法不需要依赖复杂的传感器数据或手工设计的奖励函数,而是通过观看普通的单目视频(如智能手机拍摄的日常视频),将视频中的人类动作和环境信息转化为机器人执行的行为。通过这种方法,机器人能够在事先没有学习具体任务的情况下,根据周围环境的后续做出适当的动作。
▍VideoMimic核心框架概述
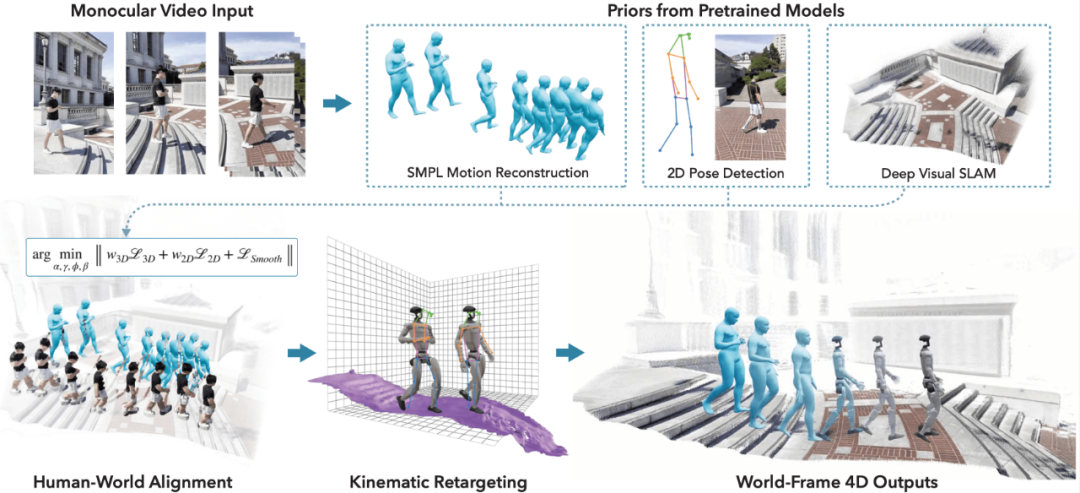
VideoMimic的核心思想在于,它能将基于普通视频的训练成果,最终转化为一种既适用于仿真环境,又能迁移到真实机器人上的控制策略。这一过程涵盖从视频中重建人类动作、提取环境信息,并借助强化学习(RL)训练出能够在不同环境中执行多样化任务的机器人控制策略。
首先,系统从单目视频中提取人体的三维关节位置,并利用结构光或深度学习方法重建周围环境。通过联合优化技术,将人体的三维运动轨迹与环境几何信息恢复至全局坐标系中,确保二者的一致性,以适配不同的仿真与物理引擎。
接着,系统将重建的运动数据与环境信息转化为类人机器人可执行的动作,并在仿真环境中进行训练。通过采用DeepMimic风格的强化学习方法,机器人学习如何在不同环境中模仿人类视频中的动作。
在仿真训练阶段,机器人通过多样化环境的历练,学会了根据环境上下文做出恰当动作。最终,系统将多个视频中的动作数据整合为一个统一控制策略,使机器人能仅凭自身运动状态与环境信息(如动作高度图和根方向指令)执行复杂全身运动。
▍VideoMimic的强化学习与仿真设计
在整个训练过程中,VideoMimic采用强化学习算法,通过近端策略优化(PPO)来训练机器人控制策略。强化学习的目标,是让机器人能在不同环境下做出最优决策,通过观察自身身体状态、姿态高度图和目标指令,选择最合适的动作。例如,机器人能通过判断地面楼梯或上方位置,决定是向前跨步、爬楼梯还是坐下。
强化学习的奖励设计以数据驱动的跟踪任务为主,奖励信号源自关节位置、速度、脚接触信号等,而非人工设计的奖励函数。这种设计减少了手工奖励工程的需求,让机器人能直接从人类演示中学习。
整个训练过程分为多个阶段,在动作捕捉预训练,系统利用运动捕捉数据对机器人进行预训练。目的是让机器人在接触噪声增大的视频数据之前,先从高质量的运动捕捉数据中学习基本的运动模式。

预训练之后,系统引入环境高度图的感知,使机器人能在不同位置执行任务。此时,机器人的控制策略开始适应真实世界,会根据地面、目标位置等因素选择合适的动作。
策略训练的最后阶段,系统通过调整方法,将一个复杂的控制策略简化成更通用的策略,让机器人能在各种不同环境和任务中灵活反应。
策略调整后,系统进行强化学习微调,确保机器人在没有目标关节角度或根方向指令的情况下,仍能自适应地执行任务。
▍实验结果与验证
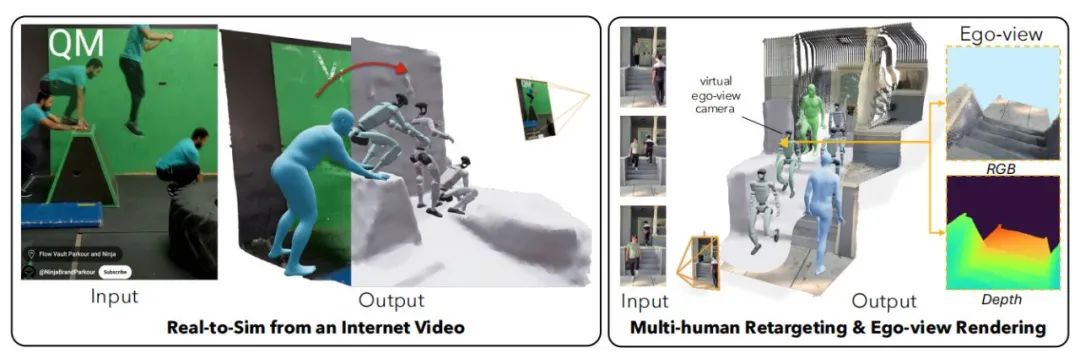
在实验环节,VideoMimic的控制策略先在仿真环境中展开了广泛测试。结果显示,机器人借助学习日常视频里的人体动作,成功完成了多种复杂任务,像爬楼梯、蹲下与站立、跨越障碍物等。实验还表明,机器人在不同环境下执行任务时,展现出了高度的鲁棒性与目标指向性。
随后,该系统的控制策略被部署到一台Unitree G1类人机器人上,并在现实环境中接受检验。机器人能够在不同场景下执行与仿真环境中相同的动作,取得了令人满意的效果。这一实验不仅验证了VideoMimic框架从仿真到现实的迁移能力,也充分证明了该方法在真实环境中的应用潜力。
与现有的其他机器人控制方法相比,VideoMimic的优点在于,它能够从普通的单目视频中学习并生成适应不同环境的控制策略,且无需依赖复杂的传感器数据或手工设计的奖励函数。在与DeepMimic、SfV等方法对比时,VideoMimic不仅在处理多种环境下的任务时展现出更强的适应能力,还能显著减少对高分辨率训练数据的需求。
▍结语与未来:
VideoMimic通过将日常视频中的人类动作与环境信息转化为机器人的控制策略,展示了一种全新的类人机器人训练方式。这种方法不仅减少了对传统运动捕捉数据和人工奖励设计的依赖,还能让机器人在无需标签的情况下,通过学习环境背景来执行复杂任务。为类人机器人在动态环境中的应用提供了一定的参考价值。
来源:具身智能大讲堂
(文:机器人大讲堂)