


随着大模型能力持续增强,仅通过观测各个 Benchmark 上的得分来判断一个模型是否真的聪明、值得信赖,可能远远不够。
你是否知道:
-
评估一个大模型完整跑完一套标准测试(如 HELM),可能耗时超过 4000 GPU 小时、成本上万美元;
-
工业界中的模型评估甚至要大量人类专家参与标注/评判;
-
很多 Benchmark 中的题目质量可能并没有我们想象中那么可靠;
-
即使模型准确率高达 99%,我们依然很难回答:它是靠实力答对的?题目太简单?还是训练时见过原题?
传统的大规模“刷题式”评估方式,已经难以满足如今通用人工智能的评估需求,尤其是认知能力的评估。
最近在 ICML 2025 会议上,一项由中国科学技术大学认知智能全国重点实验室、加州大学伯克利分校、美国教育考试服务中心 ETS 共同发布的立场论文(Position),基于上世纪就出现的心理测量学理论,提出一种 AI 评估的新思路:用评估人类的方式,来评估 AI 模型的能力。

论文标题:
Position: AI Evaluation Should Learn from How We Test Humans
论文链接:
https://arxiv.org/abs/2306.10512

当前 AI 评估方式面临的困境
为了追求全面的评估,目前 AI 模型面对的是越来越大的“试卷”,Google BIG-bench 超过 200 个任务、HuggingFace Open LLM Leaderboard 更是包括 6 个场景下 29k 个题目。
目前主流的 AI 评估方案,简单直接:准备一个庞大全面的测试集,模型答题后按准确率等各类指标打分。但这种评估范式实际应用中却问题重重:
-
成本:尤其针对大模型,评估涉及大量的计算成本、人工成本、时间成本;
-
可靠性:大量题目存在重复/冗余、题目质量良莠不齐;
-
安全性:很多测试题被模型“见过”或者“记住”了;
-
可解释性:只观测到“做对多少题”,但不知道“能力强在哪儿”“能力有多强”。

心理测量学启发:用自适应测试精准测 AI 能力
在人类的 GRE、TOEFL 等考试早已采用基于心理测量学(Psychometrics)的自适应测试。这类测试认识到:每道题的重要性和信息价值都不同,可估计出每个题目的难度、区分度、猜测概率等统计特征,并且系统会根据考生表现动态分发题目,更精准评估能力。
换句话说,自适应测试关注的,不是模型答对了多少题,而是其它真正的能力边界。本立场论文提出:心理测量学这种起源于 20 世纪针对人类的测评技术,可以帮助解决如今 AI 评估的困境,重构能力评估机制。

用心理测量学重构 AI 测评
3.1 能力导向:测出 AI 真正的“能力值”
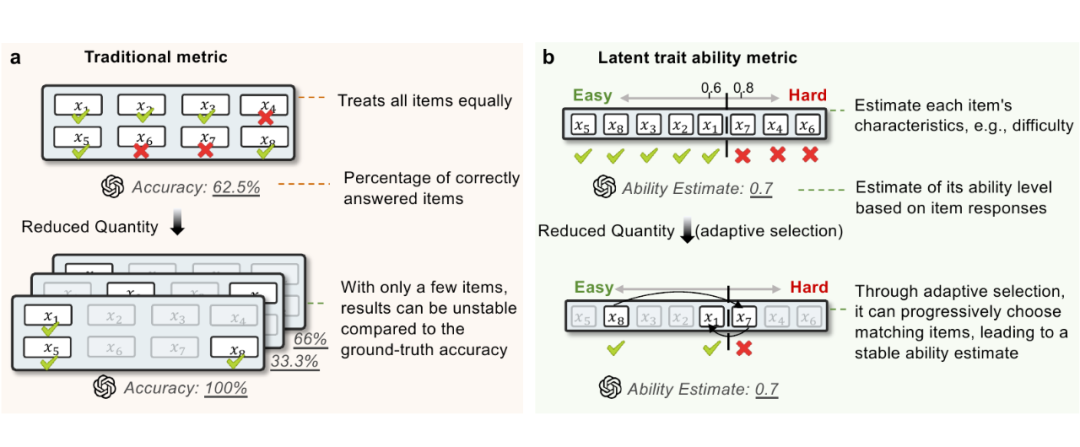
传统的评估范式是分数导向(score-oriented)而自适应测试则是能力导向(ability-oriented),不是数对了多少题,而是构建 AI 能力分布模型,给出统计意义上的能力估计。具体优势为:
-
高效性:精准选择高信息量题目,研究者发现可用不足 3% 的题量,即可还原完整 Benchmark 上的成绩(上图)
-
可解释:建模模型能力与题目特征间的关联,如相同能力下难度越低答对概率越大,可解释分数背后的原因;认知诊断模型还支持建模AI的多维能力
-
捕捉不确定性:模型行为可能受温度参数或 prompt 微小变化影响(例如人类考试时也会收到环境、心情波动等影响)
-
可比较性:在统一尺度上对模型能力进行统计比较,甚至可跨 Benchmark 统一评估(如人类的 GRE 不同场次分数具可比性)
因此,心理测量可以将 AI 模型的表现映射为“能力参数”,进而分析模型擅长/薄弱在哪、稳不稳定、不确定性高不高。
3.2 不是所有的题目都是同样重要

很多人默认 Benchmark 中的测试题目是“准确、可靠、有价值”,但事实往往不是这样。不是所有题都值得出现在测试集中。心理测量学能够估计每个题目的特征,如难度(),区分度(),猜测系数()。
-
Benchmark 中每个题目的价值/重要性是不一样的,上图(a)展示 SSTB 情感分类数据集中两个题目估计出的难度差异,简单的题目中有明显的情感偏向词汇。
-
Benchmark 中可能出现低质量甚至是标注错误的题目,如上图(b)所示,在 SQuAD 阅读理解数据集中,有些题目的区分度极低,分析发现其参考答案甚至存在错误。
-
部分题目易被“猜对”,无法真实考察能力。如上图(c)中 MedQA 医疗问答数据集的某题,即便模型缺乏医学知识,也可能仅凭常识猜对,这些题目的高猜测系数削弱了其评估价值。
3.3 大模型“偷看”过题目?数据污染识别

如今的大语言模型训练数据动辄覆盖全网,来源复杂,这带来了一个严重的问题:测试数据,很可能被模型在训练阶段“看”过。这被称之为数据污染(Data Contamination):模型在“考试”时,恰好碰上自己训练中“背过”的原题。这会造成什么影响?模型行为异常好,但并非出于理解,而是记忆;测试分数被大幅抬高,误判模型的真实水平;Benchmark 信用下滑,无法反映模型的泛化能力…
这就像,一场考试中,有考生提前拿到了原题,自然不能作为依据来判断他的水平。和人类教育体系一样,心理测量学中已经发展出一系列检测作弊或泄题的统计方法,已被证明能有效发现异常模式,并且现有很多针对 LLM 的污染检测方法也是基于如下思想(上图)。比如:
-
高难题答对,低难题却答错,这是典型的表现异常
-
模型频繁在“不可能答对的题”上答对,很可能就是“见过题”;
-
IRT 中的猜测系数异常偏高,说明模型无需理解也能答对,可能也说明是题目泄露。
此外,自适应测试还有一个天然优势:每个模型做的题不同,完整的测试集没有完全暴露,进一步降低了数据污染风险。这正是 GRE 等人类考试采用自适应测试机制的重要原因之一。

应用前景:建立 AI 时代的“心理测评框架”
该工作跨越人工智能、认知科学和标准化测评三大领域,试图为 AI 评估系统带来结构性优化。从能力评估,到偏好倾向、决策逻辑、稳定性与公平性,我们是否可以不再追求“大而全的测试集”,而是细致建模题目特征差异,洞察模型的表现与内在结构。它不仅适用于 Benchmark 构建与维护,也可能为未来AI部署前的风险评估、服务适配、安全验证等环节的提供支持。
这种“考 AI 方式与考人方式趋同”的变化,启发一种可能性:是否可以构建一个新学科方向——机器心理测量学(Machine Psychometrics)?
总之,AI 模型越来越聪明,评测方法也要变得更聪明。我们用考察人类的方法,来考察 AI,用已被验证的科学理论重建评估系统,为通用人工智能时代建立精准且公正的能力测量范式。
(文:PaperWeekly)