

作者 | 是念
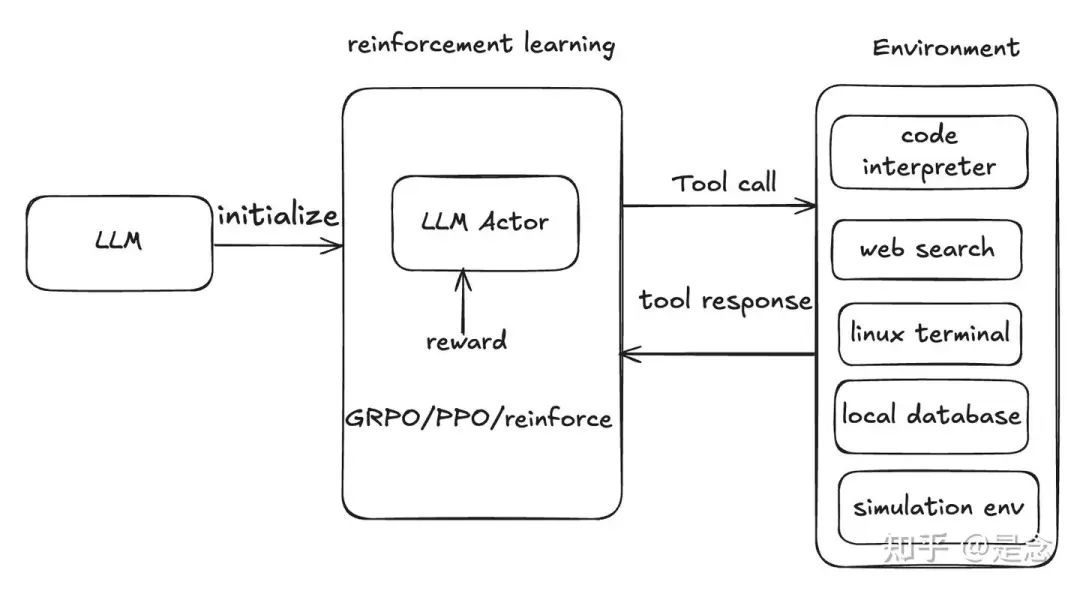
DeepSeek R1带火基于GRPO的强化学习技术后,agentic tool use learning也开始用上了GRPO,Reinforce++, PPO, policy gradient等各种算法了(以前是SFT+DPO,需要大量的标注数据来cover bad case,当时标注高质量数据都把我标哭了),想让大模型学会使用code interpreter, web search等工具来增强现有模型的数学和推理能力, 单轮就是调用一次tool,多轮就是调用多次tools, 多轮tool use更难一点,主要是数据难以获取和建模方式(MDP这种只考虑当前状态的训练模式,还是使用full history,考虑所有的状态的模式)不清晰,tool-use rl也算是一个新的研究方向了,潜力还有待挖掘。
最近的工作还是集中设计这个multi turn tool-use的prompt template,以及训练的时候需要设计rule based reward(correctness reward, format reward, tool execcution rewad等), 训练的tool output的mask操作,sampling的时候加入异步并行,融入megatron的pipeline parallel,加入多模态信息等等,训练的范式基本是先收集一波expert trajectory做sft,然后使用rl训练(例如ReTool),或者直接应用RL(例如TORL,ToolRL,OTC等),目前还没有出现一个真正为agent rl设计的方法,都是复用现有的基建(比如verl, open-rlhf, trl, ms-swift),做了一些拓展。
最近在tool-use的基础上还出现了一个tool integrated reasoning, 跟cot的区别就是在推理的过程中会使用工具,这样推理过程动态的添加了search,code,各种定制化的API的输入,推理能力得到了进一步的增强。市面上对这个方向的文章比较少,我结合自身阅读论文和实践的经历,分享一下,共同推动这个领域的研究。
有的人会好奇,这个agent的tool use的prompt该怎么写,如下示例,这是一个包含了chat template的tool prompt,具体包括chat template, tool schema, tool call, tool response等等, system prompt一般写tool schema信息,assistant是模型的响应,thinking过程包含在<think></think>中,tool调用的参数包含在</tool_call>中,tool执行的response放在user响应中,包括在</tool_response>标签中:
<|im_start|>system
In this environment you have access to a set of tools you can use to assist with the user query. You may perform multiple rounds of function calls. In each round, you can call one or more functions. Here are available functions in JSONSchema format:
\```json
tool_schema
\```
In your response, you need to first think about the reasoning process in the mind and then conduct function calling to get the information or perform the actions if needed. The reasoning process and function calling are enclosed within <think> </think> and <tool_call> </tool_call> tags. The results of the function calls will be given back to you after execution, and you can continue to call functions until you get the final answer for the user's question. Finally, if you have got the answer, enclose it within \boxed{} with latex format and do not continue to call functions, i.e., <think> Based on the response from the function call, I get the weather information. </think> The weather in Beijing on 2025-04-01 is \[ \boxed{20C} \].
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call><|im_end|>
<|im_start|>user
User 1 wants to return all books by Jane Doe they have checked out. Each book is 5 days overdue, what is the total late fee?
<|im_end|>
<|im_start|>assistant
<think> First, I need to find out which books by Jane Doe the user has checked out. Then, I will calculate the late fee for each book based on the number of days it is overdue. </think>
<tool_call>
{"name": "get_user_checked_out_books", "arguments": {"user_id": 1}}
</tool_call>
<tool_call>
{"name": "search_books_by_author", "arguments": {"author": "Jane Doe"}}
</tool_call>
<|im_end|>
<|im_start|>user
<tool_response> {"name": "get_user_checked_out_books", "arguments": {"user_id": 1}}
['Python Basics', 'Advanced Python', 'Data Structures']
</tool_response>
<tool_response> {"name": "search_books_by_author", "arguments": {"author": "Jane Doe"}}
[{'title': 'Python Basics', 'author': 'Jane Doe', 'copies_available': 3}, {'title': 'Advanced Python', 'author': 'Jane Doe', 'copies_available': 0}]
</tool_response>
<|im_end|>
<|im_start|>assistant
<think> ... ...agents rl的兴起让很多做基于agents做落地应用的人看到了希望,说一下agents rl的优点:
-
• 可以直接通过tool交互获取外部知识,进一步提升模型的准确率。 -
• DPO是一个数据驱动的方法,需要大量的数据进行训练,DPO吸收了对比学习的一些思想,所以训练好很不容易。PPO系列的方法是一个online-rl的方式,每次通过sampling的方式生成样本,然后进行训练提升,需要的数据量比DPO要小很多。
说了一下agents rl的优点,我也聊一下agents rl的不足。
-
• 真正复杂的任务可能需要几十个步骤才能完成,受限于LLM处理长序列效果下降,长序列后计算效率低等原因,现有的rl框架还是集中在10个step左右就能完成的任务,真实的任务往往需要30-100个step才能解决,所以距离真正能解决复杂的问题还有一段的距离。 -
• grpo虽然是rule based的方法,简化了流程,但还是需要标注数据,加上精心设计reward,最后还要调参,调数据才能得到一个不错的效果。 -
• rl需要依赖环境进行训练,一般是一些仿真环境,它的速度肯定不如gpu的计算速度快,能够加速env,跟得上rl训练的步伐也是一个需要值得考虑的问题。 -
• agent rl研究的单一的工具居多,比如code interpreter-only, web search-only等等,多个工具混合多轮调用研究的少一点。
有人会对这几个rl算法分不清,我来简要的梳理一下:
-
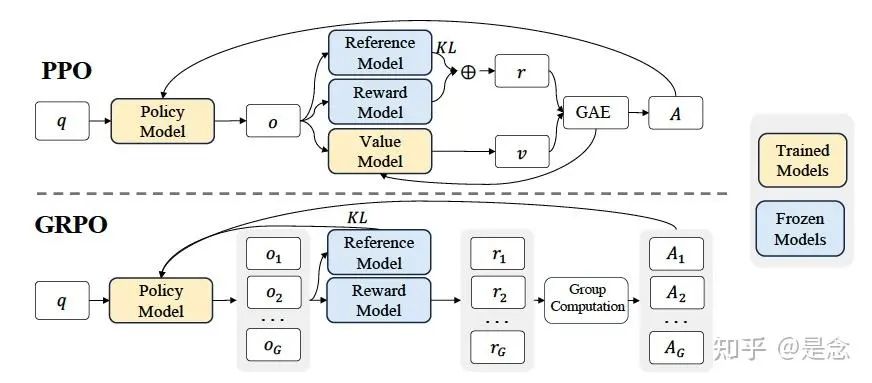
• PPO :把生成的每个token当成一个”action”,对模型的每个输出进行监督,这个过程使用的是value model/critic model完成的,loss上加上了裁剪机制限制策略的更新幅度,避免模型”学偏”. -
• GRPO :GRPO是PPO的改进版,不依赖于value network,通过生成同一个样本的多个输出,然后计算每个输出的奖励与组内平均奖励的差值,然后使用KL散度来约束模型与reference model的偏离程度。 -
• REINFORCE++ : 在基础的REINFORCE基础上增加”历史基线”机制,比如用过去多个batch的average reward作为当前的基线,避免单一的batch的波动的影响。
此外还有RLOO,REMAX, policy gradient等算法,有兴趣的话可以相关的资料学一下,RL有个特点,理论都比较长,晦涩难懂,放到代码里面就几行简单的代码。
DeepSeek 技术分析
说到RL技术,不得不提一下前段时间很火的deepseek底层技术,效果也比较惊艳,比如deepseek v3在大部分指标上超过了闭源模型gpt-4o,deepseek-r1也在大部分指标上超过了o1,开源模型能做到这么优秀,简直不可思议,还打乱了许多AI公司的闭源路线的规划,辛苦构建的壁垒,一夜就没了。我总结了一下DeepSeek-R1和V3所用到的技术:
-
• Mixture-of-Experts: 降低了训练成本并提高了推理效率。 -
• Multi-Head Latent Attention: 减少了注意力部分的 KV 缓存. Low rank。 -
• Multi-Token Prediction: 提高了模型的性能(准确性)。 -
• DualPipe: 提高了大规模GPU集群的计算与通信比率和效率。 -
• FP8 Training: 通过采用这种低精度训练进一步降低了训练成本。 -
• DeepSeek-R1强化学习GRPO与多阶段训练
这些技术就不详细展开了,市面上解读这些论文的文章也有一大堆,其中GRPO带火了RL的技术路线,它跟PPO的区别就是advantage(降低方差用的)是sampling过程产生的样本的reward,求均值,方差得到的, 因为跟ppo差别很小,所以在开源的代码在实现ppo的时候,顺带GRPO就实现了,GRPO虽然只需要rule-based reward,但是你需要根据经验设计这个reward,对于喜欢调参的人员当然是好事,对于想偷懒的人士就不太友好:
TORL: Scaling Tool-Integrated RL
论文:https://arxiv.org/abs/2503.23383
代码:https://github.com/GAIR-NLP/ToRL这篇论文介绍了ToRL(工具集成强化学习),这是一个用于训练大型语言模型(LLM)的框架,通过强化学习自主使用计算工具。与监督微调不同,ToRL允许模型探索和发现工具使用的最佳策略。
Qwen2.5-Math模型的实验显示了显著的改进:ToRL-7B在AIME~24上的准确率达到43.3%,比没有工具集成的强化学习高14%,比现有的最佳工具集成推理(TIR)模型高17%。进一步的分析揭示了新兴行为,如策略工具调用、无效代码的自我调节以及计算和分析推理之间的动态适应,所有这些行为都纯粹是通过奖励驱动的学习产生的。
训练使用VERL, GROP算法,rollout batch size 128, 16 samples, 未使用KL loss, temperature为1. Qwen2.5-7B模型。

TORL在数据集的构造中使用了LIMR,抽取高质量的样本,均衡难样本的分布,本来有75,149,筛选后得到28,740条数据,为了使模型能够使用代码块自动输出推理,TORL使用了如下所示的prompt。
在模型的推出过程中,当检测到代码终止标识符(“output”)时,系统会暂停文本生成,提取最新的代码块以供执行,并将结构化执行结果以“output\nOBSERVATION\n”格式插入上下文中,其中OBSERVATION是执行结果。然后,系统继续生成后续的自然语言推理,直到模型提供最终答案或生成新的代码块。
值得注意的是,当代码执行失败时,故意向LLM返回错误消息,因为假设这些错误诊断增强了模型在后续迭代中生成语法和语义正确代码的能力。
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.\nUser:Please integrate natural language reasoning with programs to solve the problem above, and put your finalanswer within \boxed{}.\nprompt\nAssistant:Design Choices of ToRL
Tool Call Frequency Control : rollout期间的工具集成会引入大量GPU空闲时间,rollout速度与工具调用频率成反比。为了保持合理的训练效率,本文引入了一个超参数C,表示每次响应生成允许的最大工具调用次数。一旦超过此阈值,系统将忽略进一步的代码执行请求,迫使模型切换到纯文本推理模式。
Execution Environment Selection : 为了平衡培训效率和有效性,我们寻求一个稳定、准确和响应迅速的代码解释器实现。经过调研和测试,最终选择了Sandbox Fusion2,它提供了一个隔离的执行环境。尽管延迟稍高,但它为持续训练操作提供了卓越的稳定性。
Error Message Processing : 实施了特定的错误处理优化,以提高训练效果。当Sandbox Fusion遇到执行错误时,它会生成包含不相关文件路径信息的详细回溯。为了减少上下文长度并仅保留相关的错误信息,只提取最后一行错误消息(例如,NameError: name ‘a’ is not defined)。
Sandbox Output Masking : 在损失计算过程中,从sandbox environment中屏蔽了OBSERVATION输出,通过防止模型试图记忆特定的执行输出而不是学习可推广的推理模式,显著提高了训练稳定性。
Reward Design : 实现了一个基于规则的奖励函数,正确答案获得1的奖励,错误答案获得-1的奖励。此外,代码解释器自然会提供关于代码可执行性的反馈。基于成功执行代码和解决问题准确性之间的相关性,引入了一种基于执行的惩罚:包含不可执行代码的响应会减少-0.5的奖励。更多详细内容请参考论文:
ToolRL: Reward is All Tool Learning Needs
论文:https://arxiv.org/abs/2504.13958当前的大型语言模型 (LLM) 通常需要进行监督微调 (SFT) 来获得工具使用能力。然而,SFT 难以推广到不熟悉或复杂的工具使用场景。强化学习 (RL) 领域的最新进展,尤其是类似 R1 的模型,已经展现出良好的推理和泛化能力。然而,针对工具使用的奖励设计面临着独特的挑战:多个工具可能以不同的参数调用,而粗粒度的奖励信号(例如答案匹配)无法提供有效学习所需的细粒度反馈。
在本研究中,ToolRL全面研究了 RL 范式中工具选择和应用任务的奖励设计。系统地探索了各种奖励策略,分析了它们的类型、规模、粒度和时间动态。基于这些见解,我们提出了一种针对工具使用任务量身定制的原则性奖励设计,并将其应用于使用组相对策略优化 (GRPO) 的 LLM 训练。
在不同基准测试中的实证评估表明,ToolRL能够实现稳健、可扩展且稳定的训练,相比基础模型提升了 17%,相比 SFT 模型提升了 15%。这些结果凸显了精心设计的奖励机制在提升 LLM 的工具使用能力和泛化性能方面的关键作用。
为了确定最佳奖励策略,探索了四个关键维度的各种奖励配置:
-
• 1 奖励类型(奖励哪些方面) -
• 2 奖励尺度(奖励多少) -
• 3 奖励粒度(奖励信号的详细程度) -
• 4 奖励动态(奖励如何随时间演变)。
通过大量的实验确定了最符合主体工具使用情况的奖励设计,并揭示了奖励对于调用工具的 LLM 而言“有用”的原因。论文得出的核心见解总结如下:
-
• 推理轨迹越长并不一定越好,而且过长的奖励可能会降低性能。 -
• 动态奖励尺度有助于模型从简单行为平稳过渡到复杂行为。 -
• 细粒度的奖励分解可实现更稳定、更有效的学习。
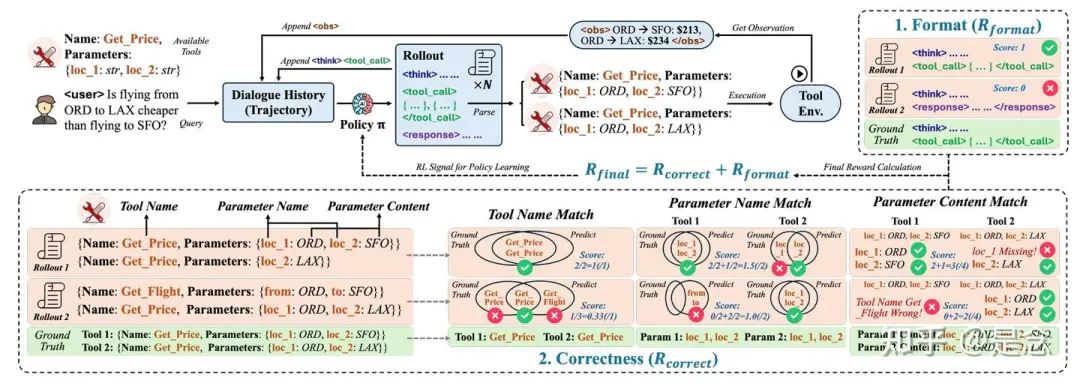
基于规则的奖励机制已展现出强大的实证效果,并被广泛采用。ToolRL同样采用了一种结合结构性和基于正确性的奖励公式,这与先前的研究一致。具体而言,格式奖励评估模型输出是否符合预期的结构,包括想法、工具调用和响应;而正确性奖励则评估工具调用的准确性。形式上,整体奖励 R final(·) 分解为两个部分:R format + R correct,每个部分的具体描述如下:
Format Reward : 奖励格式 Rformat ∈ {0, 1} 检查模型输出是否按照基本事实指定的正确顺序包含所有必需的特殊token:

Correctness Reward : 正确性奖励 Rcorrect ∈ [−3, 3],用于评估预测的工具调用 P = {P1, …, Pm} 与真实调用 G = {G1, …, Gn}。它包含三个部分:ToolName Matching, Parameter Name Matching, Parameter Content Matching, 具体就不详细展开了,都是一些格式检查的评判细则,贴了主要的公式.
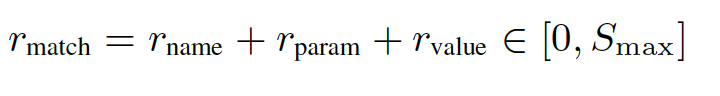
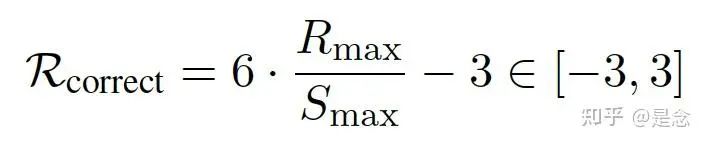
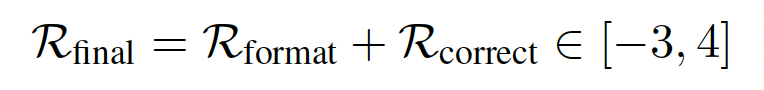
训练采用的是GRPO的方法,verl训练框架,基座模型使用的是llama3.2和qwen模型,详细就不展开了,有兴趣请参考论文。
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
论文:https://arxiv.org/abs/2504.20073
代码:https://github.com/RAGEN-AI/RAGEN将大型语言模型 (LLM) 训练为交互式智能体面临着独特的挑战,包括长期决策以及与随机环境反馈的交互。虽然强化学习 (RL) 在静态任务中取得了进展,但多轮智能体 RL 训练仍未得到充分探索。
论文提出了 StarPO(状态-思考-行动-奖励策略优化),这是一个用于轨迹级智能体 RL 的通用框架,并介绍了 RAGEN,一个用于训练和评估 LLM 智能体的模块化系统。本研究有三个核心发现。
首先,智能体 RL 训练呈现出一种反复出现的“回声陷阱”模式,其中奖励方差出现断崖式下降,梯度出现峰值;使用 StarPO-S 来解决这个问题,这是一个稳定的变体,具有轨迹过滤、评价器合并和解耦裁剪功能。
其次,多样化的初始状态、中等交互粒度和更频繁的采样将有利于 RL 部署的形成。
第三,如果没有细粒度的、推理感知的奖励信号,agent推理就很难通过多轮 RL 出现,并且它们可能会表现出浅薄的策略或幻觉的想法。
分析了agents学习的三个关键维度,并总结了以下发现,揭示了稳定agent RL 训练的核心挑战和设计原则:
多轮强化学习中的梯度稳定性是稳定训练的关键。多轮强化学习训练经常导致一种反复出现的不稳定模式,即“echo trap”,即agent过拟合局部奖励推理模式,其特征是奖励方差崩溃、熵下降和梯度尖峰。为了缓解这种失效模式,本文提出了 StarPO-S,它通过基于方差的轨迹过滤、Critic 基准测试和解耦裁剪来提高学习鲁棒性。
部署频率和多样性塑造自我进化。在基于强化学习的agent训练中,LLM 自生成的部署轨迹被用作核心训练材料。确定了agent强化学习稳定训练的关键部署因素:
-
• (1) 确保部署来自多样化的提示集,每个提示有多个响应; -
• (2) 每轮执行多个操作,以在固定的轮次限制内改善交互范围; -
• (3) 保持较高的部署频率,以确保在线反馈反映当前策略。
新兴智能体推理需要细致的奖励信号。仅仅鼓励动作形式的推理并不能保证推理行为的发生。即使通过 StarPO 进行轨迹级优化,模型被提示进行推理(例如,使用“<think>”标记),如果推理没有带来明显的奖励优势,它们也常常会退回到直接动作选择。推测这是由于 MDP 中的动作空间简单,浅层策略就足够了。
此外,当奖励仅反映任务成功时,模型会产生幻觉推理,从而揭示思维与环境状态之间的不匹配。这些问题凸显了强化学习中对细粒度、推理感知的奖励信号的需求,以便进行长远智能体训练。
如下图,先前的方法侧重于非交互式任务,例如数学或代码生成。RAGEN 实现了 StarPO,这是一个通用的agent强化学习框架,支持多轮部署、轨迹级奖励分配和策略更新,适用于需要多轮随机交互的agents任务。
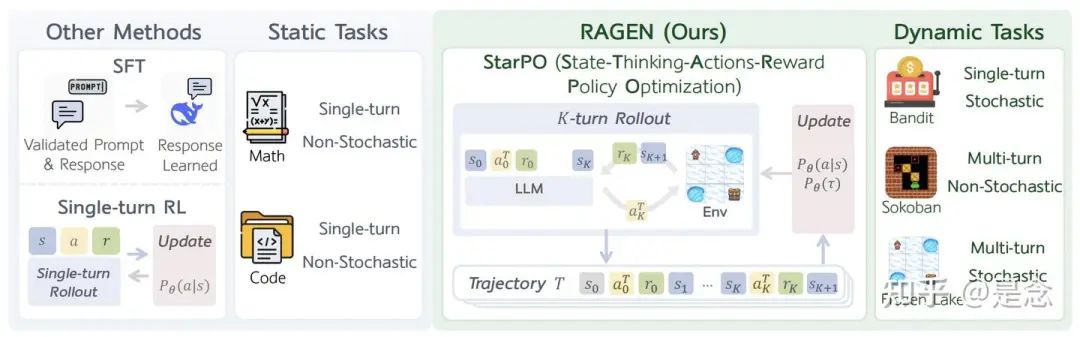
如下图,状态-思考-行动-奖励策略优化 (StarPO) 框架。LLM 为与环境的多轮交互生成推理引导的动作,并累积轨迹级奖励,这些奖励经过归一化后用于更新 LLM 策略。
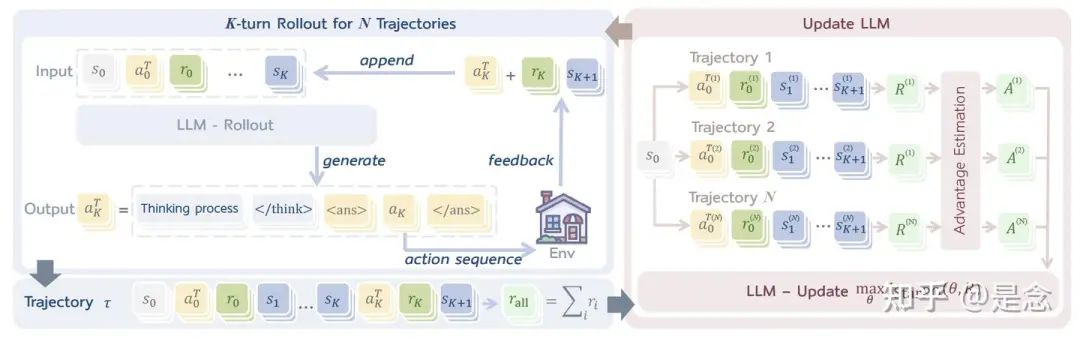
StarPO(状态-思考-行动-奖励策略优化是一个通用的强化学习框架,旨在优化 LLM agent的完整多轮交互轨迹。与以往针对静态任务单独处理每个动作的方法不同,StarPO 将整个轨迹(包括观察、推理轨迹、行动和反馈)视为一个连贯的单元,用于部署和模型优化。其目标是最大化预期轨迹奖励:

在每次训练迭代中,agent从初始状态 0开始,并生成 条轨迹。在每一步 ,agent都会生成一个推理引导的结构化输出
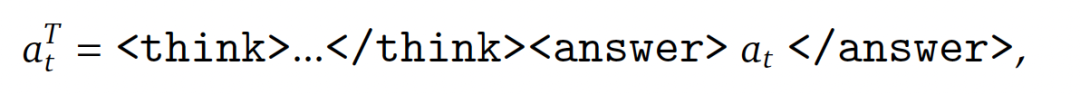
其中 是包含中间推理的完整动作输出, 是环境可执行的子动作。环境随后返回下一个状态 +1 和奖励 。rollout 阶段生成完整轨迹 = { 0, 0, 0, 1, …, −1, −1, },其中每个组件均由 LLM 生成或由环境诱导,并将进行联合优化。
StarPO 交错执行 rollout 和更新步骤。新的 rollout 可以使用 基于策略生成,也可以从 old 下的重放缓冲区中采样。每个训练循环包含 个初始状态 0,每个状态生成 条轨迹,并以批量大小 执行更新,总共 次循环。这导致总梯度步数 = · · / 。
算法使用的是PPO和GRPO,模型使用的是qwen-0.5b-instruct,用的是verl框架,为了将 StarPO 付诸实践,构建了RAGEN,这是一个用于在受控环境中训练 LLM agent的完整系统。RAGEN 支持结构化部署、可自定义的奖励函数,并可与多轮随机环境集成。它既可以作为 StarPO 的执行后端,也可以作为研究推理agent训练过程中稳定性、泛化能力和学习动态的平台。
RAGEN 的设计具有模块化和可扩展性:新的环境、奖励方案或部署策略可以轻松插入到训练循环中,为基于强化学习的agents训练分析奠定基础。论文还在实验部分采用了DAPO提到的稳定性方法,clip-higher和remove kl term,在Sokoban and Frozen Lake两个任务上做的实验(不太常见的任务)。想了解更多信息,请参考论文:
OTC: Optimal Tool Calls via Reinforcement Learning
论文:https://arxiv.org/abs/2504.14870工具集成推理 (TIR) 增强了大型语言模型 (LLM) 的能力,使其能够调用外部工具(例如搜索引擎和代码解释器),从而解决纯语言推理能力所无法解决的任务。虽然强化学习 (RL) 已展现出通过优化最终答案正确性来提升 TIR 的潜力,但现有方法往往忽视了工具使用相关的效率和成本。这可能导致行为不理想,例如过度调用工具会增加计算和财务开销,或使用工具不足会影响答案质量。
本文提出了基于最优工具调用控制的策略优化 (OTC-PO),这是一个简单而有效的基于强化学习的框架,它鼓励模型以最少的工具调用生成准确的答案。OTC引入了一种工具集成奖励机制,该机制同时考虑了正确性和工具效率,从而提高了工具的生产力。
框架实例化的 OTC-PPO 和 OTC-GRPO在多个 QA 基准测试中使用 Qwen-2.5 和 Qwen-Math 进行的实验表明,在保持相当准确率的同时,将工具调用次数减少了高达 73.1%,并将工具效率提高了高达 229.4%。
OTC-PO是一种简单而有效的基于强化学习 (RL) 的方法,它使大型语言模型 (LLM) 能够学习对外部工具使用的精确且自适应的控制。OTC-PO 训练模型以优化达到正确解决方案所需的工具调用次数,从而在不牺牲准确性的情况下降低训练和推理成本。为了实现这一目标,本文引入了一种工具集成奖励机制,它通过一个反映工具效率的缩放系数来调节传统的奖励信号(例如正确性)。这鼓励模型优先考虑需要较少工具调用次数的正确答案。
OTC-PO将优化目标从单纯的正确性转变为工具生产力,后者定义为任务收益(例如答案准确率)与工具使用成本(例如工具调用次数)之间的比率。 OTC-PO 轻量级且应用广泛,只需对标准强化学习流程进行少量修改(仅需几行代码),即可轻松应用于现有系统。在两种常用工具模式下做了实验:网页搜索和代码执行。使用多个 LLM(包括 Qwen-2.5-3B/7B-Base 和 Qwen2.5-Math-1.5B/7B-Base),OTC-PO 显著减少了推理轨迹过程中的工具调用次数,同时保持了与传统方法相当的准确率。论文提到的贡献如下:
-
• 率先实现了以下目标:i) 系统地通过强化学习解决工具效率问题,而这个问题在先前的研究中往往被忽视;ii) 识别了LLM的TIR中的认知卸载现象;iii) 引入了工具生产力的概念来衡量TIR的有效性和效率。 -
• 提出了一种简单、可扩展且可泛化的OTC-PO算法,以鼓励模型使用最优工具调用来解决问题并最大化工具生产力。该算法建立在一个基本观察之上,即每个问题和模型对都存在一个最优的工具调用次数。该算法与各种强化学习算法兼容,并且只需少量代码更改即可轻松实现。 -
• 将OTC-PPO和OTC-GRPO作为两种典型方法实现,同时保持了其适应性和泛化能力。在多个基准测试和基线上的实验结果表明,在保持域内和域外评估的大部分准确率的同时,工具调用成本显著降低。
grpo和ppo都比较常规,看一下reward的设计,使用的是余弦函数,还挺特别的,OTC-PPO的tool reward的设计:
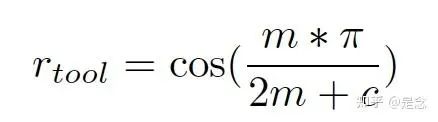
OTC-GRPO的tool reward的设计:
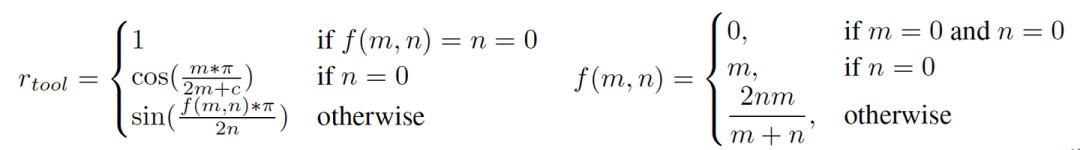
Tool-integrated Reward Design.
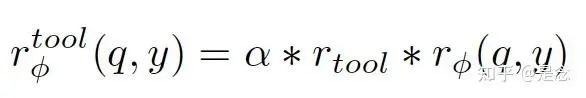
论文的主要目标是减少tool call的调用,并不是刷sota,有点可惜,其他细节就不详细展开了,有这个需求的读者可以参考论文。
SkyRL-v0: Train Real-World Long-Horizon Agents via Reinforcement Learning
https://novasky-ai.notion.site/skyrl-v0
https://github.com/NovaSky-AI/SkyRL大多数现有的强化学习框架都针对涉及短期无状态交互的任务进行了优化,例如搜索增强推理或简单的代码执行。相比之下,像 SWE-Bench 中所示的真实世界任务,则受益于在有状态的动态环境中进行长期规划。这给基础设施和训练算法都带来了新的挑战。
强化学习的最新进展使语言模型能够成为主动 agents。近期的开源框架,例如 Search-R1 和 ToRL(基于 VeRL 构建),在这方面取得了令人瞩目的进展,实现了多轮强化学习,并能够交叉使用单一工具(例如搜索或代码执行)。这些系统为工具增强推理奠定了重要的基础。然而,诸如 SWE-Bench、WebDev 和 Web 浏览等复杂的现实世界任务需要高级agents能力,其中模型需要调用多个工具、编写和运行测试、响应环境反馈并执行长期规划。
虽然这些更先进的智能体标志着令人兴奋的进化,但在它们上运行在线强化学习却极具挑战性。首先,高效的训练框架需要快速的环境执行和高效的环境交互部署。其次,有效的训练需要强大的long horizon算法(而非本博客的重点)。总而言之,这使得问题比训练先前的工具增强推理LLM复杂得多。
本文引入了 SkyRL——在 VeRL 和 OpenHands 之上构建的、用于在复杂环境中执行长期任务的多转工具使用 LLM 的 RL 训练流程,包括 SWE-Bench。SkyRL 功能:
-
• 支持训练 LLM agent,使其能够执行具有复杂环境交互的多步骤计划。 -
• 通过异步并行运行,在轨迹之间重叠计算密集型和环境交互密集型阶段,实现高吞吐量生成(相比基准实现,速度提升 4-5 倍)。 -
• 预填充(并扩展)的 RL 算法,方便快速入门。
SkyRL建立在VeRL之上,继承了其对学习算法的丰富支持。SkyRL通过引入agents层扩展了VeRL:(1)高效的异步多轮rollouts,(2)通用工具使用,以及(3)通用和可扩展的环境执行。
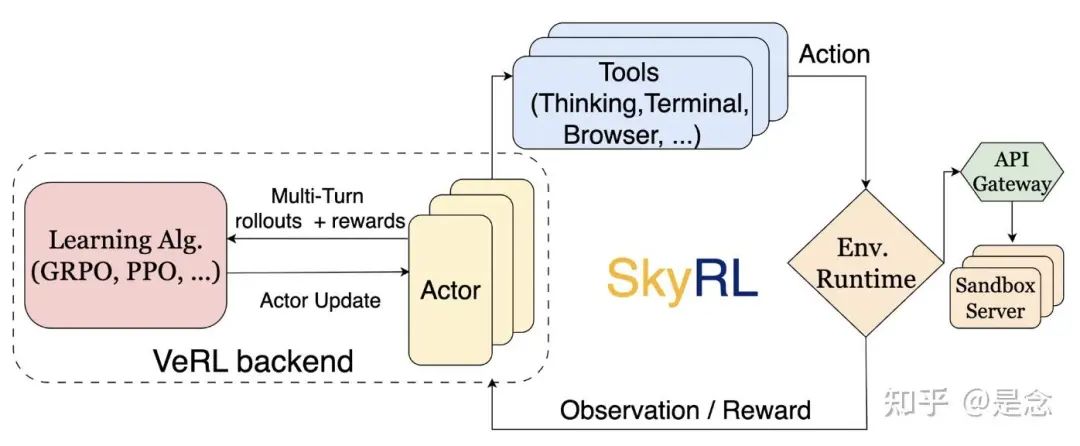
Group-in-Group Policy Optimization for LLM Agent Training
基于群组的强化学习 (RL) 的最新进展推动了大型语言模型 (LLM) 在数学推理等单轮任务中的应用。然而,它们在长期 LLM agent训练中的可扩展性仍然有限。与静态任务不同,agents与环境的交互会跨越多个步骤展开,并且通常会产生稀疏或延迟的奖励,这使得跨各个步骤的信用分配变得更加具有挑战性。
本研究提出了一种新颖的强化学习算法——群组策略优化 (GiGPO),它能够为 LLM agents实现细粒度的信用分配,同时保留了基于群组的强化学习的诸多优势:无评判、低内存和稳定收敛。GiGPO 引入了一种用于估计相对优势的两级结构:
-
• (i) 在episode级别,GiGPO 基于完整轨迹组计算宏观相对优势; -
• (ii) 在步骤级别,GiGPO 引入了一种锚定状态分组机制,该机制通过识别跨轨迹的重复环境状态来追溯构建步骤级别的组。
源自同一状态的操作被分组在一起,从而实现微观相对优势估计。这种分层结构能够有效地捕捉全局轨迹质量和局部步骤有效性,而无需依赖辅助模型或额外的部署。GiGPO使用 Qwen2.5-1.5B-Instruct 和 Qwen2.5-7B-Instruct,在两个具有挑战性的agents基准测试 ALFWorld 和 WebShop 上对 GiGPO 进行了评估。
至关重要的是,GiGPO 提供了细粒度的每步信用信号,并且在 ALFWorld 上实现了 > 12% 的性能提升,在 WebShop 上实现了 > 9% 的性能提升,相比 GRPO 基准测试,GiGPO 的性能提升同样显著:同时保持相同的 GPU 内存开销、相同的 LLM 部署,并且几乎不产生额外的时间成本。
如下图,agents与一组以相同状态初始化的环境交互,以生成一组轨迹 {τi}Ni=1。相同颜色的状态代表相同的环境状态。GiGPO 执行二维组计算(episode level AE 和step level AS),以产生用于指导细粒度策略优化的分层相对优势。
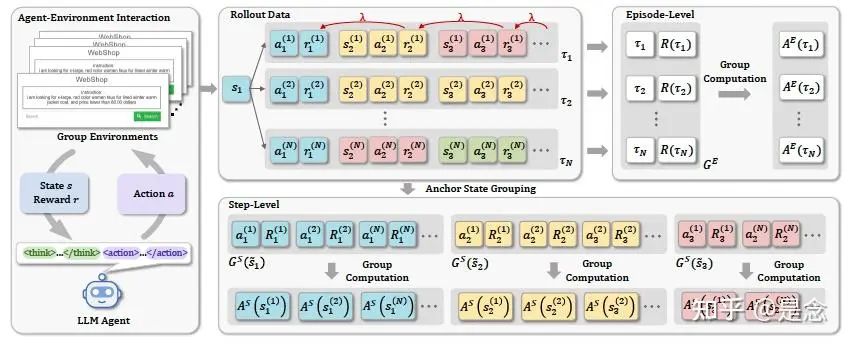
具体细节我就不展开了,就是在rollout阶段做了一些细粒度的优化,不过作者开源了基于verl的代码,有兴趣可以试一下。
论文:https://arxiv.org/abs/2505.10978
代码:https://github.com/langfengQ/verl-agentNemotron-Research-Tool-N1: Tool-Using Language Models with Reinforced Reasoning
利用外部工具赋能大型语言模型已成为将其功能扩展到文本生成任务之外的关键策略。先前的研究通常通过以下方式增强工具的使用能力:应用监督微调 (SFT) 来确保工具调用的正确性,或从更强大的模型中提炼推理轨迹以实现 SFT。然而,这两种方法都存在不足,要么完全忽略推理,要么产生限制泛化的模仿推理。
受 DeepSeek-R1 通过基于规则的强化学习成功引出推理的启发,本文提出了 Nemotron-Research-Tool-N1。Nemotron-Research-Tool-N1 并非严格监督从更强大的模型中提炼出的中间推理轨迹,而是通过二元奖励进行优化,该奖励仅评估工具调用的结构有效性和功能正确性。这种轻量级的监督机制使模型能够自主地内化推理策略,而无需带注释的推理轨迹。
在 BFCL 和 API-Bank 基准上进行的实验表明,基于 Qwen-2.5-7B/14B-Instruct 构建的 Nemotron-Research-Tool-N1-7B 和 Nemotron-Research-Tool-N1-14B 取得了最先进的结果,在两项评估中均优于 GPT-4o。
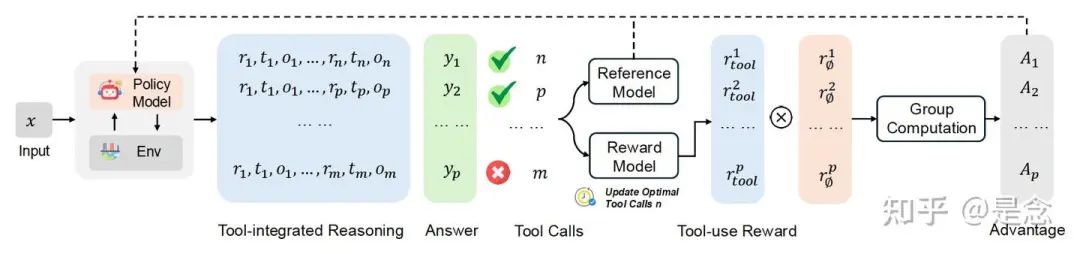
Nemotron-Research-Tool-N1(Tool-N1)训练流程概览如下图。从包含用户query和候选工具的标准SFT工具调用数据开始,训练LLM,使其使用GRPO算法中的二元奖励函数进行结构化推理和工具调用。由于监督仅针对格式和工具调用的正确性,因此训练过程不需要精心策划的推理轨迹。
Data Preparation
过滤掉包含无效工具调用的样本(特别是那些涉及候选工具列表中缺失工具的样本), 标准化数据集。从系统提示中提取可用工具,并将候选工具和真实工具调用解析为结构化字典格式。JSON 解析失败或包含格式不一致的实例将被丢弃。这种预处理过程生成了一个干净且一致的数据集,适用于强化学习。对于来自 ToolACE 子集的多轮数据,进一步将每个轨迹细分为多个单步预测实例(把多轮拆成多个单轮,复用现有的infra),其中每个实例包含一个目标工具调用,并将前面的步骤视为上下文。使用GRPO训练,根据这些上下文信息和提供的工具来预测每个工具调用步骤。
Thinking Template
采用轻量级的提示模板来从 LLM 中引出工具调用,如下图所示。该提示明确指示模型在 <think>…</think> 标签内生成中间推理,然后在 …</tool_call> 标签内进行工具调用。此模板背后的设计理念是尽量减少对过于严格的格式规则的依赖,从而降低过度拟合特定提示模式的风险。通过赋予模型更大的推理表达灵活性,目标是促进模型在不同工具使用场景中实现更稳健的泛化。此外,在训练过程中使用这种轻量级的提示设计,使生成的模型能够更容易地与更复杂的提示策略集成。

Reward Modeling
Formate Checking :训练过程中加入了格式检查,以验证模型的输出是否符合预期的结构规范——具体来说,推理过程是否包含在 <think>…</think> 标签中,工具调用是否正确包含在 …</tool_call> 标签中。这种结构约束鼓励模型在工具调用之前进行明确的推理,而不是快速得出最终答案。通过强制遵循格式,旨在培养模型的内在推理能力,这可能有助于提升泛化能力——尤其是在处理分布外的输入时。
Tool-Calling Checking : 检查工具调用本身的正确性。工具调用输出被解析为字典,以便与真实调用进行精确匹配。这包括检查预测的工具名称是否与真实调用匹配,以及所有必需的参数是否都具有正确的值。这种严格的匹配标准确保模型能够学习生成功能精确且可执行的工具调用。与 SFT 中的下一个标记预测逻辑相比,这种基于字典的匹配带来了更大的灵活性。它允许参数顺序变化而不会受到惩罚,从而鼓励模型专注于工具调用的底层语义,而不是停留在表面记忆。这种设计有助于更深入地理解工具的使用,并支持更好的泛化。
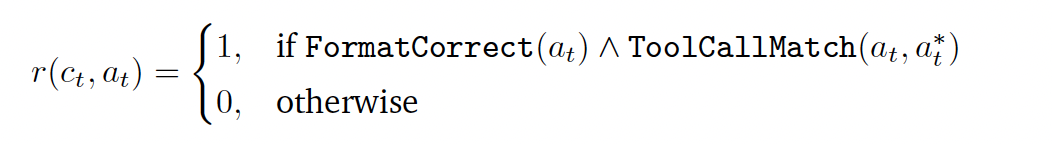
很好的一篇来自nvidia的实践文章,详细信息请参考论文:
https://arxiv.org/abs/2505.00024Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
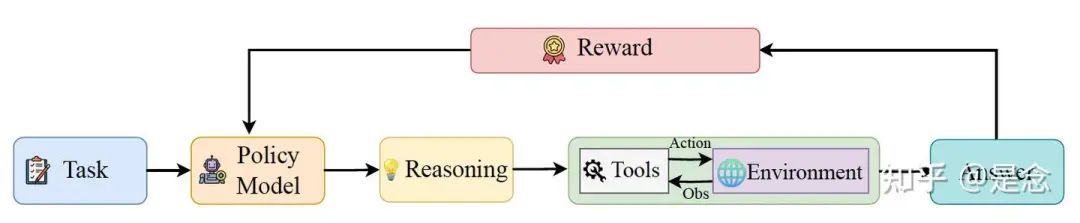
大型语言模型 (LLM) 在复杂推理任务中取得了显著进展,然而,它们仍然受到对静态内部知识和纯文本推理的依赖,这从根本上限制了它们的发展。现实世界的问题解决通常需要动态、多步骤推理、自适应决策以及与外部工具和环境交互的能力。
本文引入了 ARTIST(自改进 Transformers 中的agent推理和工具集成),这是一个统一的框架,它将agentic推理、强化学习和 LLM 的工具集成紧密结合在一起。ARTIST 使模型能够自主决定在多轮推理链中何时、如何以及调用哪些工具,利用基于结果的强化学习来学习强大的工具使用和环境交互策略,而无需步骤级监督。
在数学推理和多轮函数调用基准测试中进行的大量实验表明,ARTIST 的性能始终优于最先进的基线模型,与基础模型相比,其绝对性能提升高达 22%,并且在最具挑战性的任务中取得了显著的进步。详细的研究和指标分析表明,agentic强化学习训练能够带来更深层次的推理、更高效的工具使用和更高质量的解决方案。
在 ARTIST 中,rollout 在模型生成的推理步骤和工具输出之间交替进行,从而捕捉agents与外部工具和环境的交互。统一应用 token 级损失会导致模型模仿确定性工具输出,而不是学习有效的工具调用策略。
为了防止这种情况发生,ARTIST采用了一种损失掩蔽策略:在损失计算过程中,工具输出中的 token 会被掩蔽,确保梯度仅通过模型生成的 token 传播。这将优化重点放在agent的推理和决策上,同时避免来自确定性工具响应的虚假更新。
ARTIST 架构图如下。通过交织基于文本的思维、工具查询和工具输出来实现agentic推理,从而在统一框架内实现推理、工具使用和环境交互的动态协调。
ARTIST 方法论概述如下图。该框架阐述了推理如何在内部思考、工具使用和环境交互之间交替进行,并以基于结果的奖励来指导学习。这使得模型能够通过强化学习迭代地完善其推理和工具使用策略。
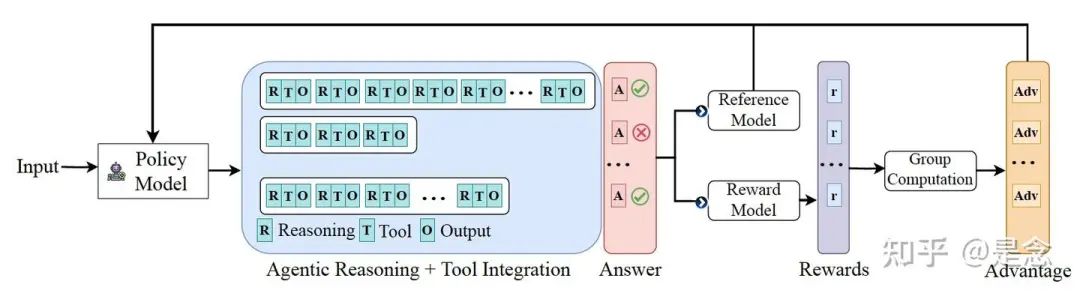
Rollouts in ARTIST
在 ARTIST 中,rollout 的结构设计为在内部推理和与外部工具或环境的交互之间交替进行。与仅由模型生成的 token 组成的标准 RL rollout 不同,ARTIST 采用迭代框架,其中 LLM 将文本生成与工具和环境查询交织在一起。 Prompt Template: A RTIST 使用结构化的提示模板,将输出分为四个部分:
-
• (1) 内部推理 (<think>…</think>) -
• (2) 工具或环境查询 (…</tool_name>) -
• (3) 工具输出 (<output>…</output>) -
• (4) 最终答案 (<answer>…</answer>)
发出工具查询后,模型会调用相应的工具或环境,附加输出,并继续推理循环,直到得出答案。 Rollout Process: 每次rollout都由这些结构化片段组成,策略模型在每个步骤中决定是进行内部推理还是与外部资源交互。
工具调用可能包括代码执行、API 调用、Web 搜索、文件操作或在交互环境(例如 Web 浏览器或操作系统)中的操作。这些交互的输出会被重新整合到推理链中,从而实现基于反馈的迭代改进和自适应策略调整。
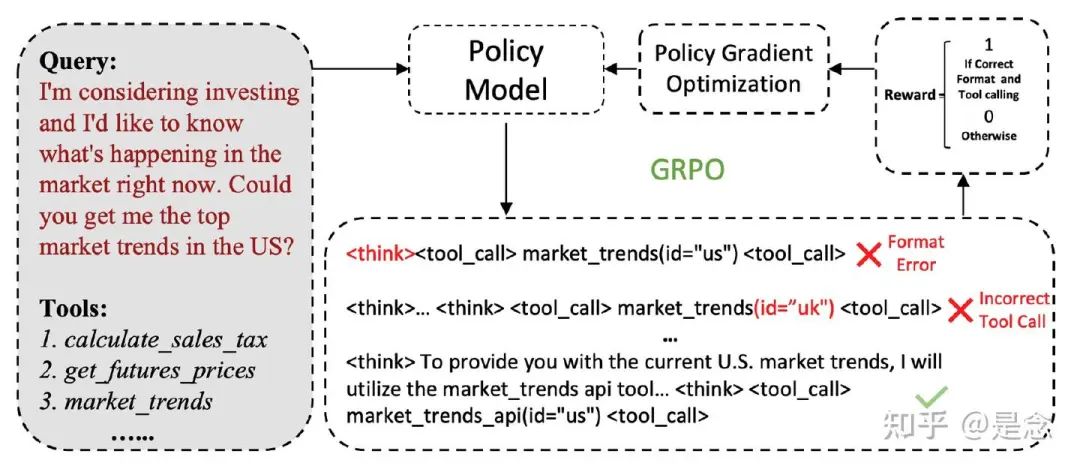
Reward Design
精心设计的奖励函数对于有效的强化学习训练至关重要,因为它提供了优化信号,引导策略朝着理想的行为发展。在 GRPO 中,基于结果的奖励已被证明既高效又有效,无需密集的中间监督即可支持稳健的策略改进。然而,ARTIST 为奖励设计带来了新的挑战:除了得出正确的最终答案之外,模型还必须以连贯可靠的方式构建其推理、工具使用和环境交互。
为了解决这个问题,ARTIST使用了一种复合奖励机制,可以为每次部署提供细粒度的反馈。ARTIST 中的奖励函数由三个关键部分组成:
Answer Reward : 当模型生成正确的最终答案(如 <answer>…</answer> 标签中所示)时,该组件会分配正向奖励。答案奖励直接激励模型正确解决任务,确保推理过程的最终目标得以实现。
Format Reward : 为了促进结构化和可解释的推理,ARTIST引入了格式奖励,鼓励遵守规定的提示模板。该奖励检查两个主要标准:
-
• (1) 在整个部署过程中,执行顺序——推理 (<think>)、工具调用 () 和工具输出 (<output>) 是否保持正确; -
• (2) 最终答案是否正确地包含在 <answer> 标签中。格式奖励有助于模型学习以一致且易于解析的方式组织其输出,这对于可靠的工具调用和下游评估至关重要。
Tool Execution Reward : 在每次工具交互过程中,模型的查询可能格式正确或可执行,也可能不正确。为了鼓励稳健有效的工具使用,ARTIST引入了工具执行奖励,定义为成功工具调用的比例:
Tool Exection Reward = Tool success / Tool total其中 Tool success 和 Tool total 分别表示成功调用工具的次数和总调用次数。此奖励确保模型学习生成语法正确且可在目标环境中执行的工具查询。
ARTIST使用的是GRPO方法训练,模型用的是Qwen2.5 7b和14b, 框架用的是verl,然后分别针对复杂数学推理和多轮function calling设计了reward函数,详细请参考论文:
https://arxiv.org/abs/2505.01441Agent RL Scaling Law: Spontaneous Code Execution for Mathematical Problem Solving
大型语言模型 (LLM) 通常在需要精确、可验证计算的数学推理任务中举步维艰。虽然基于结果的奖励的强化学习 (RL) 可以增强基于文本的推理能力,但理解智能体如何自主学习利用代码执行等外部工具仍然至关重要。本文研究了基于结果的奖励的强化学习,并将其应用于工具集成推理 (ZeroTIR) 训练基础 LLM,使其能够在没有监督工具使用示例的情况下自发生成并执行用于数学问题的 Python 代码。
具体而言,训练步数的增加会导致自发代码执行频率、平均响应长度以及至关重要的最终任务准确率的提高。这表明,投入到训练中的计算工作量与有效的工具增强推理策略的出现之间存在可量化的关系。实现了一个具有解耦代码执行环境的稳健框架,并在标准 RL 算法和框架中验证了我们的发现。实验表明,ZeroTIR 在具有挑战性的数学基准测试中显著超越了非工具 ZeroRL 基线。
基于现有工具功能,基于微调模型的强化学习会掩盖一些重要的发现。与基于 SFT 之后模型的强化学习类似,很难观察到响应长度与性能之间的关系。本文旨在提供更全面、更清晰的分析,以促进社区研究和“agent rl scalling law”的复现。展示了使用主流社区框架(Open-Reasoner-Zero、OpenRLHF)和流行的强化学习算法(PPO、Reinforce++ )以及环境服务器进行的详尽实验。研究了从基础模型初始化的 LLM 如何通过强化学习自发学习利用 Python 代码执行环境。
论文的核心假设是,利用这种工具的学习过程遵循可识别的模式,将其称为“Agent RL Scaling Law”。
-
• 识别并描述了新的 Agent RL 扩展定律,该定律控制着 ZeroTIR 中自发代码执行技能的自主习得,用于数学推理。 -
• 提出并实现了一个有效的框架 ARL,用于训练基础 LLM,以自发地利用代码执行,该框架可以在社区主流的 RL 训练框架上快速启用。 -
• 实证验证表明使用 ZeroTIR 训练的 ZTRL 模型在具有挑战性的数学基准测试和基于 SFT 的 TIR 方法上显著优于非工具性 ZeroRL 基线。
ZeroTIR 通过强化学习训练基础 LLM,使其能够自主利用 Python 代码执行环境进行数学问题求解。主要采用策略梯度算法,例如 PPO 和 REINFORCE 变体,例如 Reinforce++。
首先,ZeroTIR引入了重放缓冲区过滤机制,以增强稳定性并集中学习。针对同一提示生成的多个响应被分组,并计算其最终答案准确率(基于结果奖励)。过滤掉准确率高于高阈值 0.8 或低于低阈值 0.2 的组,优先考虑学习梯度可能最有利的中间范围内的样本。
其次,ZeroTIR实现了一种高效的交互机制,用于在部署期间自发执行代码,如图 3 所示,该方法利用动态停止token(例如,“python”,“”)来迭代管理推理、代码生成、与外部代码环境的交互以及执行反馈的集成。这种状态机方法比生成完整序列然后进行事后解析以提取代码的效率显著提高。
该机制还通过计算已完成的执行周期 (n calls) 来管理工具交互频率。为了进行实验控制,尤其是在管理计算资源的初始运行中,强制设置最大调用次数 (N max)。达到此限制后,会在最终恢复生成之前向上下文中注入一条通知(“工具调用次数已用尽。您无法再调用该工具。”),以确保agents此后能够依靠内部推理。
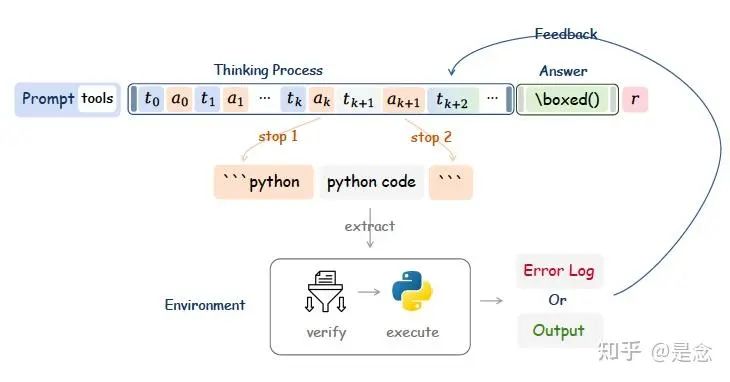
论文:https://arxiv.org/abs/2505.07773
代码:https://github.com/yyht/openrlhf_async_pipline总结
还有一些跟search相关的工作,比如R1-Searcher,ReSearch, Search-R1,DeepResearcher等,有兴趣可以看看。
总体上,agents的训练拓展还是基于现有的rl基础设施,做了一些修改,谈不上是巨大的创新,但是这个领域逐渐活跃起来了,说不定大家卷来卷去发现了一条百试百灵的路径,让rl和agents更完美的融合,门槛进一步降低,支持更复杂的场景。
(文:机器学习算法与自然语言处理)