
RL

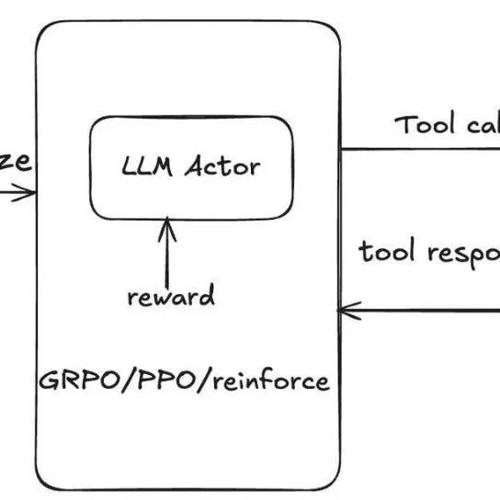
MCP技术总结及推理大模型强化学习机制分析

今日记录了MCP相关进展及语音大模型和推理大模型的最新情况,包括Kimi开源语音模型、关于推理能力实证分析的研究,以及Model Context Protocol (MCP) 的综述等内容。

Awesome-Slow-Reason-System:深度探索慢思考推理系统的前沿进展与实践
Awesome-Slow-Reason-System介绍了一种慢思考推理系统的前沿进展与实践,涵盖了50多篇最新研究成果,涉及多种技术如MCTS、RL等,并提供复现资源。
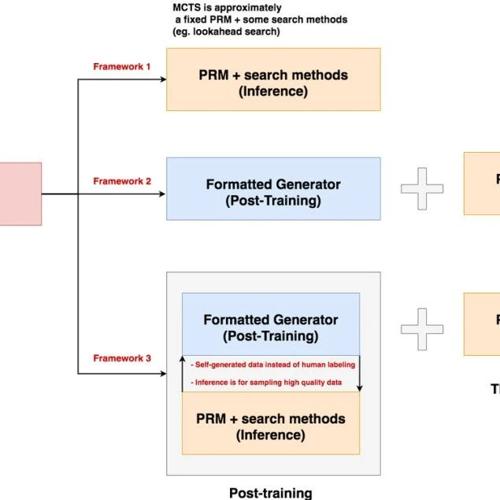

RL「误人」?LeCun 在技术路线上又有何战略摇摆?

Karpathy 认为强化学习早期决策是一个错误,并认为 LeCun 对强化学习的态度一直正确。LeCun 历年推崇的关键技术有无监督学习、自监督学习、Energy-Based SSL 和 Objective-Driven AI,他认为强化学习存在局限性,不适合作为实现人类水平智能的主要方法。