

极市导读
探讨DeepSeek-R1及其前身R1-Zero的训练方法和性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一、写在前面
在OpenAI o1刚放出来时,它有限的技术报告里,有2个内容格外抓人眼球:
-
Inference/test-time scaling -
RL

我一直是把这2者理解为两个独立的个体,在这个基础上,当时我给出了一些关于o1实现思路的猜想(https://zhuanlan.zhihu.com/p/773907223):
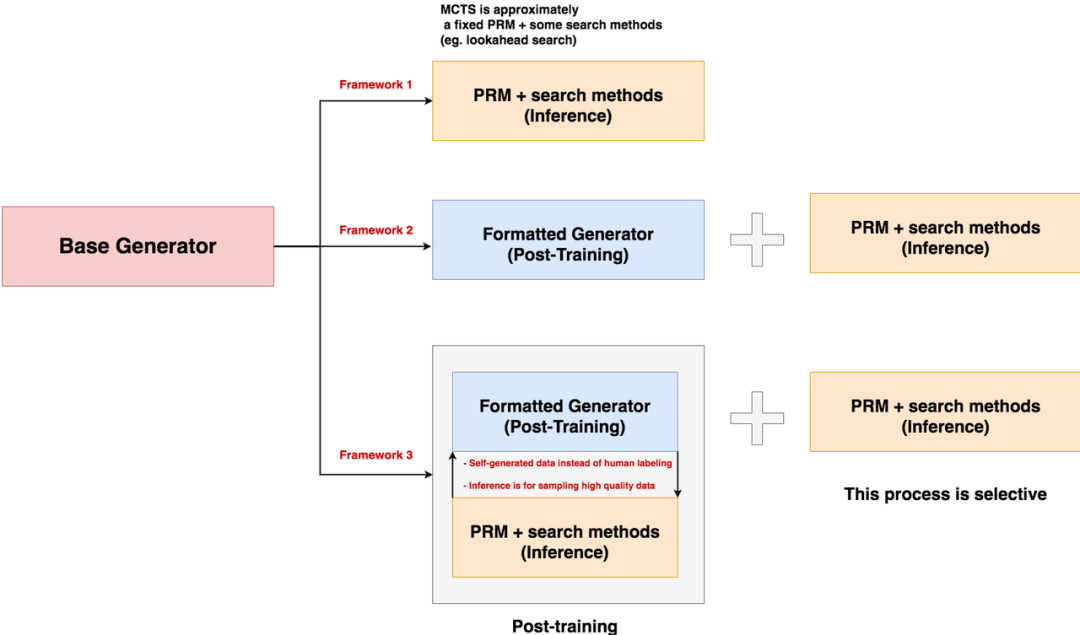
我认为o1走的可能是上述framework3的路线,总结来说:
-
Inference/test-time scaling:这一块的主要作用是为RL过程自动化地制造高质量数据集。包括用于format模型产生思考过程的long cot数据集,以及带preference labels的数据集。我把这一块的系统抽象为PRM + some search methods的形式。例如讨论度很高的MCTS,本质上也可理解为 fixed PRM + some search methods。 -
RL:这部分应该就是openAI自己惯有的一套RL流程。 -
在这样的训练框架下,最终推理时是否要再次引入inference-time scaling模块,就是一个可选项了。只要RL过程做得充分好,那么直接用训完的policy模型就可以,完全不需要再做优化。
那么,我为什么当时会认为 inference-time scaling 和 RL 应该是2个独立的过程呢?因为在我的认知里,我认为如果没有显式的引导,模型是不具备产生long cot(乃至带反思的cot)的能力的(在模型训练初期,这个能力是指formatting模型,让它知道要产出这种格式的回答;在训练过程中再来慢慢提升这种回答的质量)这个显示引导就是指诸如sft这样的过程。所以在这个认知里,上面的2个过程就应该是独立的。
而我第一次发现这样的认知可能有问题,是在我阅读红杉对openAI的访谈中,在这个万字长文里,有一句话格外引起我的兴趣,我当时把它划了出来:

这句话的意思是:没有人为的刻意为之,模型在某种训练过程中自发出现了反思的行为。而如果这一点都是能实现的,那是否意味着没有人为的刻意为之,模型本来也具备产生long cot的能力呢?
如果是这样的话,那么o1可能除了数据工程 + 惯常的RL技巧外,整个系统要比想的简单很多。可是我的水平有限,实在不知道除了显式引导外,模型怎么可能自发产生这样的能力呢?而直到前几天,又是蹭着热点读到了dpsk-r1的这篇技术报告,我这下才发现:原来单纯的RL就可以激发模型产出带有long cot(甚至是反思)的回复的能力!(可能在此之前已有很多研究发现了这点,是我对这一块的follow-up太少了,确实直到跟着热点读了dpsk-r1,才发现了这点)。这里单纯的RL是指:我并没有显式提供一些真正的long cot数据让模型去背去学,我只是在sys_msg里告诉模型先思考,再回答。接着通过RL一轮又一轮的训练,模型产出的responses越来越长,且在某个时刻出现了自我评估和反思的行为。这个实验探索就是dpsk-r1-zero在做的事情。
如果RL有这种能力,那么inference time scaling 和 RL 就可以不是2个独立的过程,而是在RL的过程里自发出现了inference time scaling的现象,而如果它们不再独立,那么类o1的训练架构也许就比我们想得要简单很多。
原本我只是抱着追热点的心态扫一下dpsk r1,我甚至没打算看完它的tech report。不过开头关于dpsk-r1-zero的实验结论一下吸引了我,所以把核心内容简单记录下,我会侧重训练流,略去评估。(这边的重点并不在于讨论什么路子是对的、什么是错的,只是对我来说发现一种可能)。
二、DeepSeek-R1-Zero
在dpsk r1的这篇报告里,提到了2个模型,分别是 DeepSeek-R1-Zero 和 DeepSeek-R1,总结来看:
-
zero算是一个实验性质的模型,在zero上不通过任何sft的方式,仅使用RL + 规则RM,就能激发模型产出带反思的long cot。这个重要的实验发现进一步启发了r1的训练。 -
r1是受到zero RL相关的实验结果启发,而新训的最终版的模型。zero所采用的RL方法(即什么样的RL能激发模型主动产出long cot,甚至是反思)将被 r1 参考。
下面简单记录下两者的训练细节。
2.1 强化学习方法
dpsk家的GRPO,不是文本关注的重点,暂略。
2.2 奖励模型-规则式RM
在训练DeepSeek-R1-Zero时,采用了基于规则的奖励系统,主要包括两种类型的奖励:
(1)准确性奖励(Accuracy Rewards) 用于评估模型responses的准确性。例如数学问题的答案是否正确,代码是否通过测试用例等。
(2)格式奖励(Format Rewards)
-
作用:除了准确性奖励模型外,还需要评估模型的输出是否遵从了一定的格式要求,以此规范模型的思维过程。 -
具体要求:要求模型将其思维过程放在‘’和‘’标签之间。这种格式化有助于明确模型的推理步骤。
(3)为什么不使用神经网络式的RM?
-
Reward Hacking -
训练资源与复杂性
2.3 RL数据的prompt设计
为了训练DeepSeek-R1-Zero,我们首先设计了一个简单的模板,指导基础模型遵循我们指定的指令:
-
从中可以看出,这个模版就是sys_msg + question,整体作为prompt -
这里不是说用sft,而是说直接用这个prompt喂给base模型(就是actor),同时由于RM是规则式的,不需要用数据训练了,所以接下来就可以正常走rlhf过程了。
模版如下:

2.4 关于zero的重要结论
和别的模型的性能比较这里略去,简单介绍一下对于R1 zero性能重要的几个结论:
-
r1 zero证明了无需sft,直接用base model做RL,已经可以取得强大的reasoning能力。
-
使用多数投票策略(例如对一条prompt采样多次,取出现次数最多的那个答案)可以进一步增强模型性能。
-
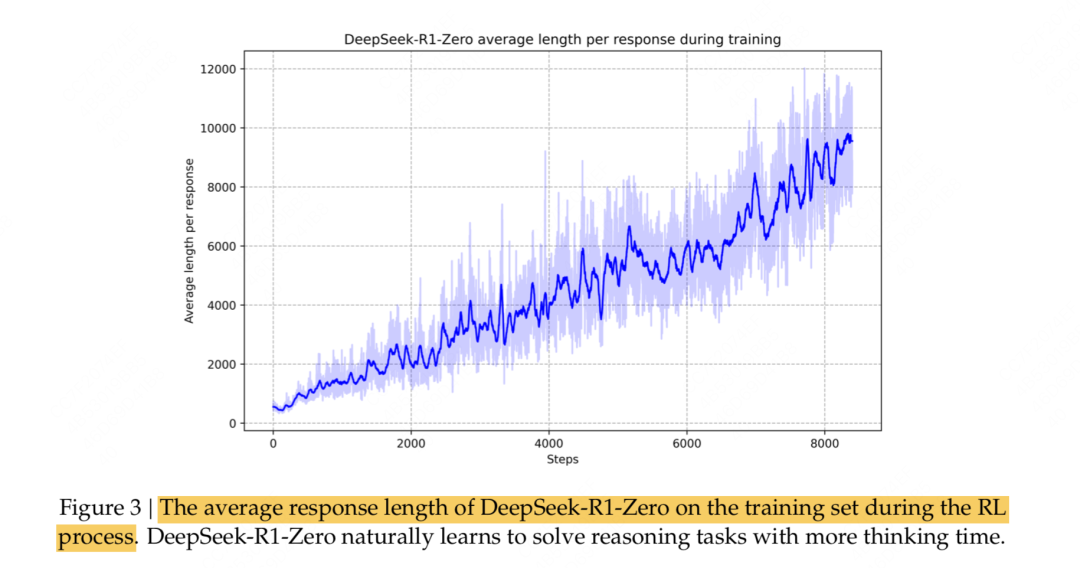
随着训练steps的增加,r1 zero倾向于产出更长的response(long cot),并且还出现了反思行为。这些都是在没有外部干预的情况下,r1 zero模型在训练中自我进化的结果。
-
response的长度随着训练时间增加而变长(思考得更多了)
-
r1 zero自然而然学会了重新评估和反思

2.5 zero的缺陷
-
可读性差 -
多种语言混合
所以接下来探索deepseek r1,这是独立于r1 zero的正式训练流程了。可以说,r1 zero的训练是一个探索性的过程,它验证了RL本身对于激励模型产生推理的能力。在这个探索结论上,开始正式进入r1的训练。
三、DeepSeek-R1
r1的训练总体训练过程如下:
-
从base模型开始:
-
使用量少、质量高的冷启动数据(cold data)来sft base模型,使得base模型可以有个良好的初始化 -
使用RL提升模型的推理能力 -
在RL阶段接近收敛时,用这个时候的checkpoint生成高质量的数据,将它们与现有的sft数据混合,创建新的sft数据集 -
再次从base模型开始:
-
使用新创建的sft数据集做finetune -
执行二阶段RL -
得到最终的r1
3.1 使用冷启动数据做sft
-
冷启动数据收集的方法如下(共收集约千条):
-
few_shot:用带有long cot的例子作为few_shot,引导模型生成回答(引导的是base模型)
-
直接在prompt中,要求模型生成带有反思和验证的回答(引导的也是base模型)
-
收集前面对r1 zero的部分结果
-
使用人工对数据做一些后处理
-
最后,我们要求冷启动数据遵从一定的数据格式:
|special_token|<reasoning_process>|special_token|<summary>
-
使用这千条冷启动数据,对base模型进行sft。
3.2 冷启动sft后的RL
-
RM衡量的内容有2方面(看样子也是规则式的):
-
语言混合问题:这里RM在打分时,也要对语言一致性进行打分(计算目标语言词汇的比例) -
答案的准确性 -
然后继续做类似于r1 zero的RL过程
3.3 创建新的sft数据集
这里新的sft数据集来自两个方面,一共约80w条。
1. 当前正在训练的模型产出的结果(reasoning data)
-
取RL接近收敛时的checkpoint -
构造prompt模版,使用拒绝采样的方式来筛选轨迹数据。在判断一条轨迹是否应该保留时,除了使用之前规则式的RM,还会引入deepseek v3作判断(比如这条轨迹所指向的答案和v3的结果是否一致)。引入多个判断标准的目的是为了更好扩展数据集,保证多样性(这是我猜的) -
最后在做一些过滤,这部分收集约60w条新sft数据集
2. 不是当前正在训练的模型产出的结果(no reasoning data)
-
已经有的高质量sft数据集(dpsk v3做sft的数据集) -
通过prompt引导deepseek v3产出的有cot的数据集等 -
这部分大约收集了20w
3.4 使用新的sft数据集继续finetune,并做RL
-
再次回到base模型上,首先用这80w的新数据对它做2个epoch的sft。
-
接着执行2个阶段的RL:
-
第1阶段RL:旨在增强模型推理方面的能力。采取类似r1 zero的RL方法,使用基于规则的RM,对模型进行RL训练,以提升模型在数学、代码和逻辑方面的推理能力。(这里用的数据集应该不是那80w,是类似于zero直接构建prompt) -
第2阶段RL:旨在针对模型的helpfulness和 harmlessness,类似于dpsk v3的训练pipeline
3.5 为什么还有sft的过程
当你观察上面对r1的两个阶段训练时,你会发现它们依然用到了sft,表现在:
-
在第1阶段,使用千条冷启动数据做sft,这千条冷启动数据都是带有long cot的reasoning data -
在第2阶段,使用约80w条新的数据做sft,这里有60w reasoning data和20w general data。
那么你看可能会有这样的疑问:如果还用sft,那前面zero的实验是不是白做了? 既然得到了RL本身就有激发模型做long cot和反思的能力,那要sft干嘛?这岂不是和开头所说的RL中实现inference time scaling有矛盾吗?
这里谈一下我的理解:
-
首先,总体来看,sft的作用是为了让模型拥有一个好的训练起点。 -
具体来说,在冷启动阶段,你只是用了千条数据做sft而已;在第2阶段,虽然使用了80w这一较多数量的数据,但这波数据的使用是一次性的,你不需要让这个过程贯穿在RL on-policy训练的每个step。而且相比于设计一个复杂独立的inference系统,它的生成是容易的。这里做的事情不过是让模型拥有强壮的训练起点。 -
而在拥有这个起点之后,更强的推理和反思能力,则是靠RL来做,这正是受到zero的启发。
四、蒸馏dense模型
使用以上80w数据,对llama和qwen系的部分dense模型做sft,然后检测这些模型的推理能力。
结论:对于小模型,不需要依然RL,只用蒸馏就可以使得其推理能力得到显著提升(对于大模型会是怎么样的,这里没有提)

(文:极市干货)
卧槽!这也太强了吧!RL不仅能激励生成长思考过程,还能自动添加反思功能,这不就是人工智能的终极形态吗?