


极市导读
本文介绍了国防科大提出的一种名为SceneTracker的长时场景流估计方法,该方法能在线捕捉3D点轨迹,适用于机器人、自动驾驶等领域,还构建了真实世界数据集LSFDriving,实验表明其在遮挡和深度噪声处理上表现卓越。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Part1 论文信息
标题:SceneTracker: Long-term Scene Flow Estimation Network
作者:Bo Wang,Jian Li,Yang Yu,Li Liu,Zhenping Sun,Dewen Hu
机构:国防科技大学
原文链接:https://arxiv.org/abs/2403.19924v4
代码链接:https://github.com/wwsource/SceneTracker
Part2 论文简介
在时间与空间组成的4D时空中,精确、在线地捕捉和分析长时且细粒度的物体运动,对机器人、自动驾驶、元宇宙、具身智能等领域更高水平的场景理解起到至关重要的作用。
本研究提出的SceneTracker,是第一个公开的(2024.03) 有效解决在线3D点跟踪问题或长时场景流估计问题(LSFE)的工作。其能够快速且精确地捕捉4D时空(RGB-D视频)中任意目标点的3D轨迹,从而使计算机深入了解物体在特定环境中的移动规律和交互方式。本工作现已发表在人工智能顶级期刊《IEEE Transactions on Pattern Analysis and Machine Intelligence》(IF=20.8)上。
SceneTracker是一个新颖的基于深度学习的LSFE方法,它采用迭代的方式逼近最优轨迹。同时其动态索引和构建表观相关性特征和深度残差特征,并利用Transformer挖掘和利用轨迹内部和轨迹之间的远程联系。通过详细的实验,SceneTracker在处理3D空间遮挡和抗深度噪声干扰方面显示出卓越的能力,高度符合LSFE任务的需求。同时,本研究构建了第一个真实世界的LSFE评估数据集LSFDriving,进一步证明了SceneTracker在泛化能力上的优势。
Part3所提方法介绍
我们的目标是跟踪一个3D视频中的3D点。我们形式化该问题如下:一个3D视频是一个帧的RGB-D序列。估计长时场景流旨在生成已知初始位置的个查询点的相机坐标系下的3D轨迹。我们方法的整体架构如图1所示。
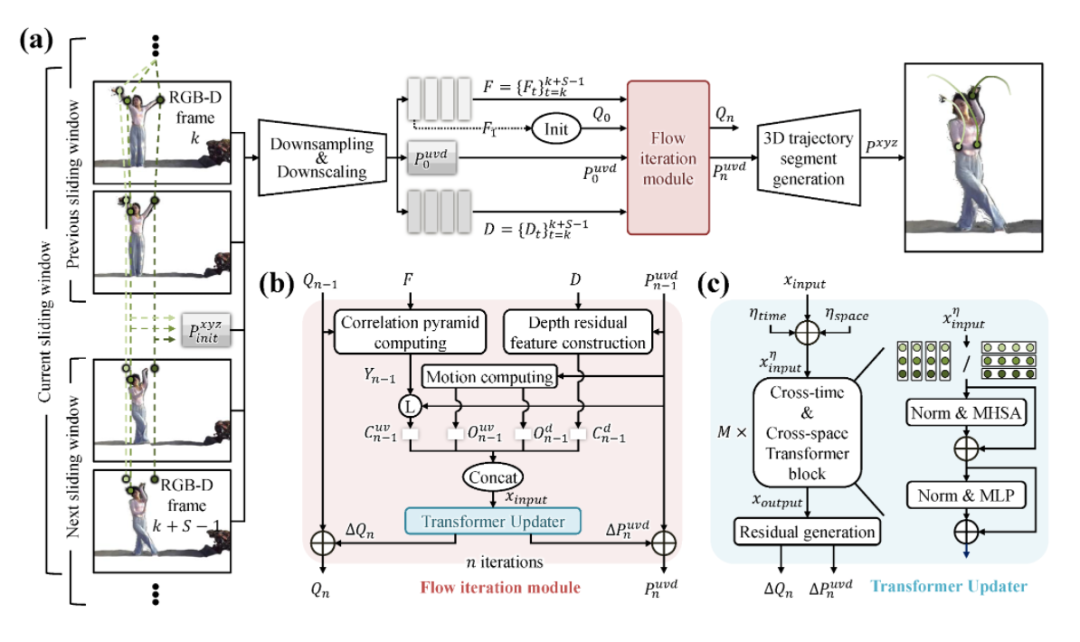
1.轨迹初始化
初始化的第一步是将整个视频划分为若干滑动窗口。我们以长度、滑动步长进行划分。如图1左侧所示,我们需要跟踪个查询点,以三个绿色点为例。对于第一个滑动窗口,轨迹会被初始化为查询点的初始位置。对于其他滑动窗口,其前帧会根据前一个滑动窗口的后帧的估计结果进行初始化,而其后帧会根据前一个滑动窗口的最后一帧估计结果进行初始化。以任意一个滑动窗口为例,我们得到相机坐标系下的初始轨迹。进一步的,我们结合相机内参将其转换为坐标系下的初始轨迹。
2.降采样和降尺度
我们网络推理在的粗分辨率上。这里是一个降采样系数。首先我们使用一个编码器网络来提取图像特征。编码器网络是一个卷积神经网络,包括8个残差块和5个下采样层。无需特征提取,我们直接对帧的原始深度图进行间隔为的等间隔采样,从而得到降采样的深度图。进一步的,我们在维度上对初始轨迹进行倍的降尺度操作,得到初始降尺度轨迹
3.模板特征和轨迹的更新
在流迭代模块(FIM)中,我们迭代式地更新查询点的模板特征和降尺度轨迹。当处理第一个滑动窗口的第一帧时,我们使用查询点的坐标在特征图上进行双线性采样,从而获得第一帧的模板特征。然后我们将该特征在时间维度上复制次,获得所有后续滑动窗口的初始模板特征。所有滑动窗口都有一个统一的和独立的。经过FIM的次迭代后,它们会被更新为和。
4.轨迹输出
我们首先将更新后的降尺度轨迹放大得到当前滑动窗口的3D轨迹片段,以匹配原始输入分辨率。然后我们结合相机内参,将其转换为相机坐标系下的3D轨迹片段。最后我们将所有滑动窗口生成的轨迹片段链接起来形成完整的3D轨迹。其中相邻窗口中重叠部分采用后一个窗口的结果。
Part4 所提数据集介绍
给定一个自动驾驶数据的序列,我们的目标是构建一个帧的RGB-D视频以及第一帧中感兴趣点的3D轨迹。具体地说,我们会分别从静态背景、移动的刚性车辆以及移动的非刚性行人上采样感兴趣点。
1.背景上的标注
首先,我们利用相机内参和外参来提取第一帧的LiDAR点,这些点可以被正确地投影到图像上。然后我们使用2D目标检测中的包围框来过滤掉所有前景LiDAR点。以一个LiDAR点为例,我们根据车辆位姿将其投影到剩余的帧上。正式地,在时刻的投影点为:
这里,是时刻从车体到世界坐标系的转换矩阵。
2.车辆上的标注
与背景不同,车辆具有自己独立的运动。我们引入3D目标跟踪中的3D包围框来提供时刻从世界到包围框坐标系的转换矩阵。我们使用3D包围框来过滤出所有车辆的LiDAR点。以一个LiDAR点为例,在时刻的投影点为:
3.行人上的标注
行人运动的复杂性和非刚性决定了其标注的困难性,这从现有场景流数据集不包含该类数据中可以进一步验证。我们使用双目视频来间接地解决该挑战。首先,我们准备一段帧的矫正双目视频。然后我们采用一个半自动的标注框架来高效且准确地标记左右目视频中感兴趣点的2D轨迹。框架的第一步是标记感兴趣点,我们开发了一个定制化的标注软件并标记第一帧左目图像中感兴趣点的2D坐标。第二步是计算粗左目轨迹,我们利用CoTracker来计算左目视频的粗轨迹。第三步是计算粗右目轨迹,我们利用LEAStereo来逐帧计算感兴趣点的视差,从而推导出粗轨迹。第四步是人工细化阶段,左右粗轨迹会在标注软件中显示,其中所有低质量的标注都会被人类标注师修正。最后,我们结合细化后的左轨迹和视差序列来构造3D轨迹。图2展示了行人的LSFE标注过程。

Part5实验结果
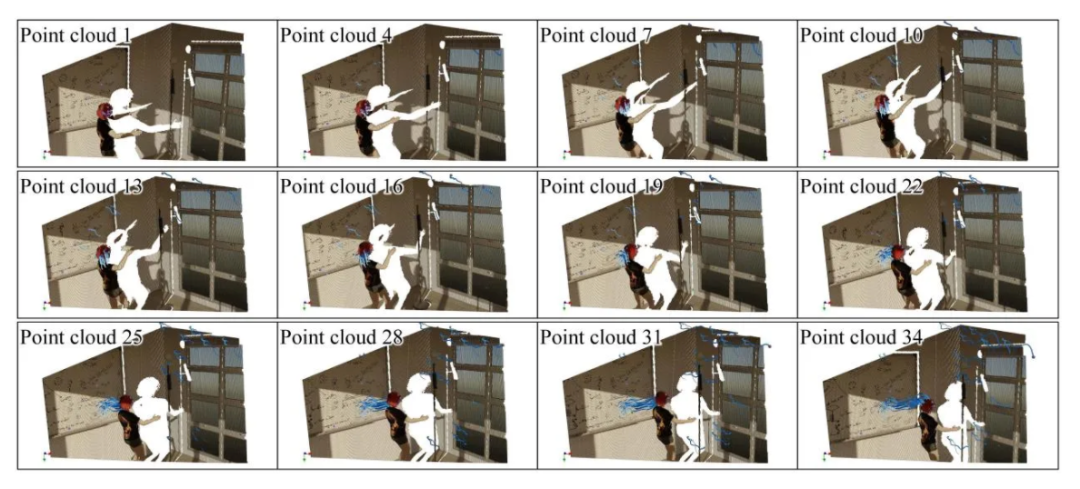
1.所提数据集LSFDriving示例
图3为所提LSFDriving数据集在三种类别(背景、车辆、行人)上的示例。

2.所提方法SceneTracker估计效果
图4为所提方法SceneTracker在LSFOdyssey测试集上的估计效果示例。我们等间隔地展示了40帧视频中的12帧点云。方法估计出的轨迹用蓝色显示在对应点云上。从图4可以看出,面对相机和场景中动态物体同时进行的复杂运动,我们方法始终能够输出平滑、连续且精确的估计结果。
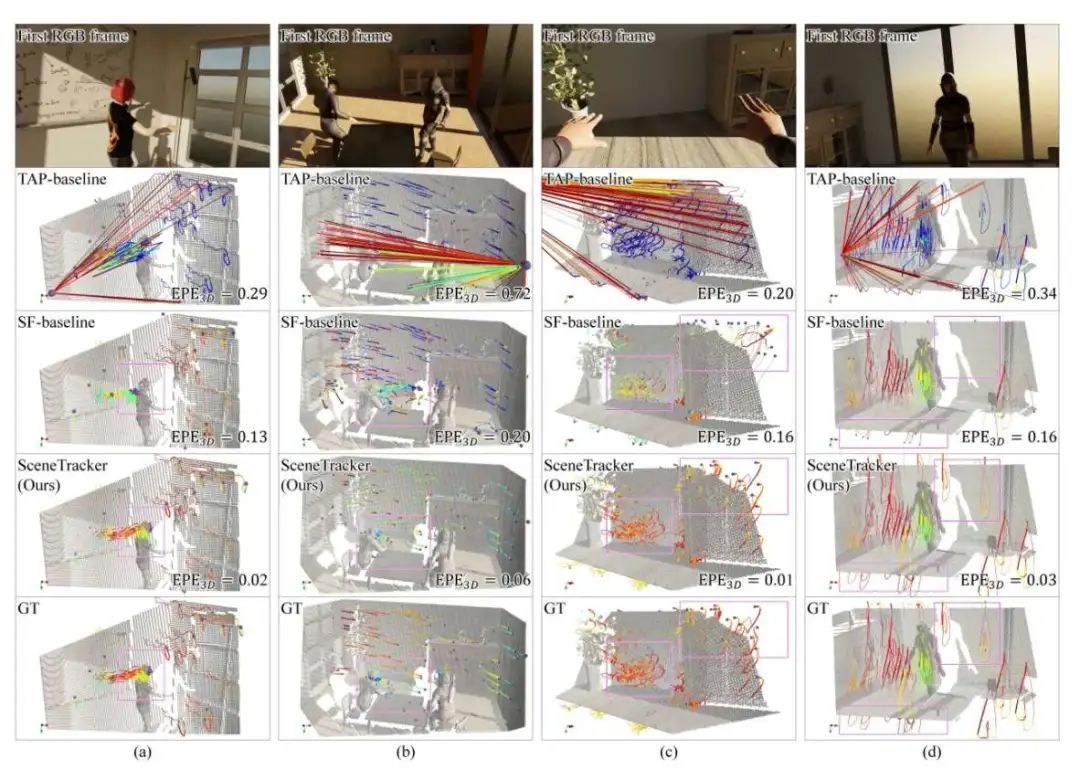
3.与SF、TAP方法的定性比较
图5是我们方法与scene flow基线、tracking any point基线方法在LSFOdyssey测试集上的定性结果。我们可视化了最后一帧的预测和真值轨迹。轨迹使用jet着色。实线框标记了SF基线由于遮挡或超出边界导致的显著错误区域。从图5可以看出,相比其他方法,我们方法能够估计出厘米级别精度的3D轨迹。
4.与SF、TAP方法的定量比较
表1为在LSFOdyssey测试集上3D指标的定量结果。所有数据均来自于Odyssey训练流程。从表1可以看出,我们方法在所有数据集指标上均显著超越其他方法。

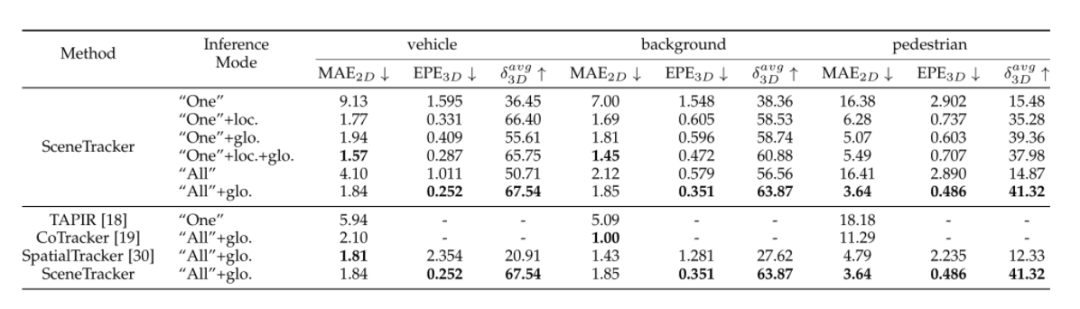
5.在真实场景数据集LSFDriving上的表现
表2为不同推理模式下我们方法在LSFDriving上的评估结果以及与近期相关方法的比较。从表2可以看出,在仅依赖合成数据进行训练的条件下,我们方法具有真实场景中高泛化能力的优势。

(文:极市干货)