
GPU内存不够用?PyTorch让你事半功倍!

随着AI模型规模的不断扩大,显存不足已成为制约研究的一大瓶颈。但是,PyTorch的最新技术让我们看到了突破这一限制的希望。
PyTorch研究员Thien Tran最近在Twitter上分享了一项重大进展:通过巧妙的内存优化技术,他们成功在16GB显存的GPU上完整微调了Llama3-8B模型。
这意味着,即使是普通的消费级显卡,也有可能训练起大规模语言模型了。
那么,PyTorch团队是如何实现的呢?
全新的内存管理策略
Thien Tran介绍了他们的核心思路:通过CPU与GPU之间的数据流动优化,来突破显存限制。

具体来说,他们采用了以下几个关键技术:
-
参数扁平化:将同一层的所有参数连接成一个大张量,减少内存碎片。
-
双缓冲预取:在前向传播时预取下一层参数,反向传播时预取上一层参数,同时将梯度卸载到CPU。
-
CPU上的优化器步骤:将优化器状态保存在CPU内存中,减少GPU显存占用。
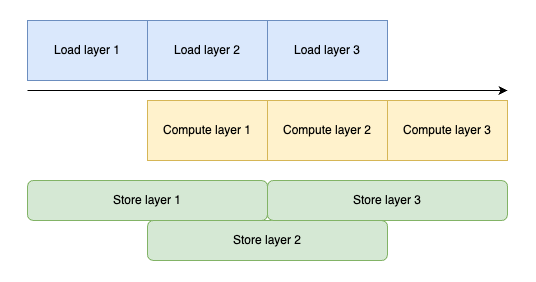
这种策略使得模型训练过程变成了一个精心编排的数据流动:当GPU在处理当前层时,CPU已经开始准备下一层的数据。
这种流水线式的处理大大提高了内存利用效率。
性能表现如何?
对于Llama3-1B模型,使用相同配置,这种CPU卸载方法仅比完全在GPU上运行慢不到1%。

令人兴奋的是,由于可以增加批量大小,实际每秒处理的token数甚至可能超过不使用卸载的情况!

然而,当扩展到8B参数规模时,虽然仍能正常工作,但速度会显著下降。
Thien Tran推测,这可能是因为PyTorch在可用显存很少时需要进行一些「内务处理」,触发CUDA同步,从而阻止了优化器步骤与反向传播的重叠执行。

未来计划
为了解决8B模型上的性能下降问题,Thien Tran 称将计划实现一个在GPU上执行优化器步骤的CPU卸载版本。
代码见:
https://gist.github.com/gau-nernst/9408e13c32d3c6e7025d92cce6cba140
(文:AGI Hunt)