

极市导读
本文提出一种兼具可交互性和可扩展性的世界模型架构 iVideoGPT,基于视频的压缩标记化和自回归 Transformer,支持在百万条人类和机器人操作轨迹上预训练,并适配到动作条件视频预测、视觉规划和基于模型的强化学习等多种控制相关任务。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

作者:吴佳龙,尹绍沣,冯宁亚,和煦,李栋,郝建业,龙明盛
链接:https://arxiv.org/pdf/2405.14369
主页:https://thuml.github.io/iVideoGPT
代码 & 预训练模型:https://github.com/thuml/iVideoGPT
1. 引言
近年来,以Sora为代表的视频生成模型,能够生成逼真的长视频,产生了广泛的应用。这引发了人们对于构建世界模型的设想:
视频生成模型是世界模型吗?
我们的回答是还不是。
-
从任务的视角,世界模型需要具备可交互性。它使得智能体能够在虚拟世界中根据当前观测产生候选动作,推演动作产生的后果,并根据想象的观测再次执行动作,如此往复,逐步找到解决问题的途径,相比于在真实世界中尝试更加高效和安全。 -
从数据的视角,世界模型需要具备可扩展性。它需要能够建模足够复杂的真实世界转移,而不仅仅局限在视觉简单的游戏上;更进一步地,我们希望世界模型能够从来自互联网的超大规模数据中学习世界演变的通用知识,从而能够泛化或快速迁移到特定任务场景。 -
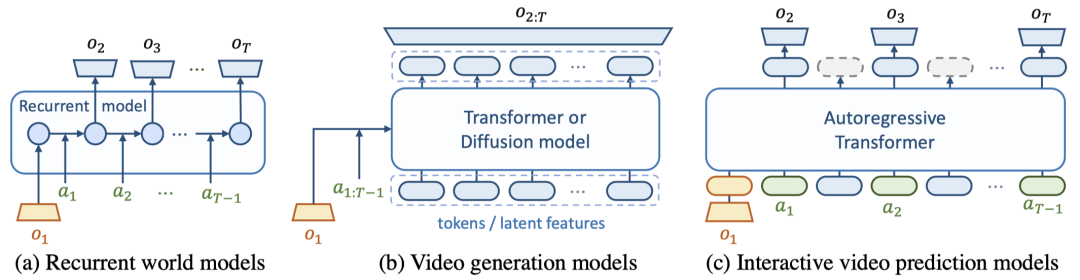
然而,从模型的视角,在本文的工作开展时,主流的模型并没有同时满足交互性和扩展性的高要求:基于循环网络的世界模型缺乏高可扩展性,而视频生成模型则缺乏高可交互性(展开讨论见下文)。因此,本文的核心研究问题是:
如何基于可扩展的视频生成模型的进展来开发交互式的视觉世界模型?
2. 交互式视频预测作为世界模型
世界模型是由智能体学习用于模拟环境的内部模型。环境通常被建模为部分可观测的马尔可夫决策过程 (POMDP) , 其中状态转移概率定义为 , 且智能体往往仅能获得状态的不完全观测 。
尽管世界模型作为一种通用形式可以学习多种类型的数据,视频是一种与任务无关、广泛可获取且包含丰富知识的模态。因此,我们专注于学习视觉世界模型(即 ),并将其形式化为交互式视频预测问题,这是一个智能体产生动作和世界模型推演转移的交替过程:
基于循环架构的世界模型,如 Dreamer,天然支持如上逐帧的可交互性,但循环神经网络的可扩展性不足,难以建模复杂的现实世界数据。视频生成模型,如 Stable Video Diffusion 和 VideoGPT 等,虽然发展了更加可扩展的架构,但其往往具有时间维度上非因果的信息融合模块,导致它们仅能提供轨迹级的交互性:
即,仅允许在视频生成开始前输入文本/动作条件,缺乏在模拟过程中进行中间动作控制的能力,且通常生成固定长度的视频。
3. iVideoGPT
iVideoGPT是一种通用且高效的世界模型架构。它将视觉观测(通过压缩标记化)、动作和奖励等多模态信号整合为一个标记(token)序列,并通过自回归 Transformer 进行下一个标记预测(next-token prediction)提供交互式体验。
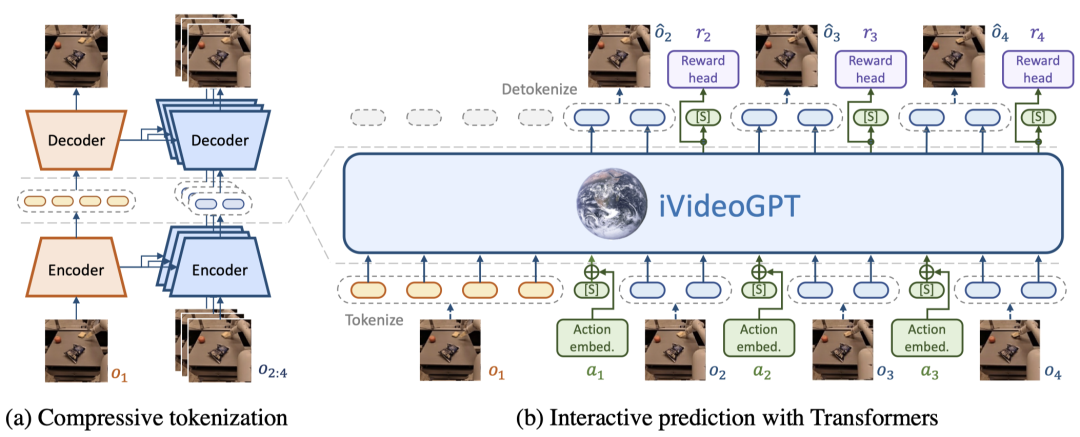
3.1 视频的压缩标记化
Transformer 更加擅长处理离散标记序列。不同于使用每帧独立的图像 tokenizer 导致序列过长,或使用 3D tokenzier 进行时空压缩时牺牲交互性,我们提出了一种具有双编码解码器的条件 VQGAN 来进行视频的压缩标记化。
具体地, 初始帧 包含丰富的上下文信息, 被每帧独立地离散化为 个标记:
相比之下,由于初始帧和未来帧之间存在时空冗余,仅需编码关键的动态信息,例如移动物体的位置和姿态等。为此,采用了条件编码器和解码器,仅需更少数量的个标记:
其中条件机制通过多尺度特征图之间的交叉注意力实现(与本组前序工作 ContextWM 相同)。
在本文中, 且 ,带来了每帧 16 倍的标记数量压缩。这样的压缩标记化带来了两个主要益处:
-
更短的标记序列,可加快生成速度,从而加速基于模型的规划和强化学习的 rollout; -
更容易保持视频内容的时间一致性,专注于关键动态信息的建模。
3.2 基于自回归 Transformer 的交互式预测
经标记化后,视频被展平为一个标记序列:
其中插入了特殊的槽标记(slot token),用于指示帧之间的边界,并便于融入额外的低维模态(见下)。一个 GPT 式的自回归 Transformer 被训练用于生成下一个标记,从而实现未来的逐帧预测。在本文中,我们采用了 GPT-2 尺寸的 LLaMA 架构。
采用下一个token预测的序列建模范式为我们带来了指定不同任务、输入、输出的高度灵活性。
(1) 序列建模的灵活性:多模态
iVideoGPT 可以灵活地整合不同模态的输入输出。在本文中,我们通过线性映射将动作信息添加到槽标记的嵌入中;对于奖励预测,我们在每帧观测的最后一个标记的隐藏状态后接一个线性预测头并使用 MSE 损失训练。
实现完全的多模态离散标记序列也是可行的,可以利用相关工作中已经发展了的动作、奖励量化(quantization)等技术。
(2) 序列建模的灵活性:多任务
为了初步展示兼容不同任务的灵活性,我们训练了一种 iVideoGPT 的变体,用于基于目标的视频预测(goal-conditioned video prediction):。这可以简单通过重新排列帧序列实现,而保持模型架构和训练过程不变:
4. 预训练与微调范式

基于 GPT 的架构具有良好的可扩展性,这使我们可以在大规模数据上进行有效的预训练。
世界模型的视频预训练范式(action-free video pre-training)以视频预测作为自监督预训练任务。我们基于这一通用任务预训练 iVideoGPT,优化交叉熵损失来预测未来帧的标记:
其中是需要预测的帧的第一个标记的下标。
本文中,我们专门为机械臂操作领域预训练了 iVideoGPT,使用来自 Open X-Embodiment (OXE) 机械臂操作和 Something-Something v2 人手操作的混合数据集,总计 140 万条轨迹。不同机械臂和人手具有高度异构的动作空间,但可以被轻松统一在视频预训练框架下。
预训练的 iVideoGPT 可以作为基础模型,微调到多种下游任务,包括基于动作的视频预测、基于视觉的模型预测控制和强化学习等。
5. 实验
5.1 视频预测
我们展示了 iVideoGPT 在不同数据集和设置上的视频预测结果。在大规模 Open X-Embodiment 数据上,基于无动作视频预测训练的 iVideoGPT 能够生成与真实轨迹不同,清晰、自然、多样化的机械臂操作轨迹,这说明它理解了与环境交互的一般规律。基于目标的视频预测训练的 iVideoGPT 则能够更加准确地预测到达目标的轨迹。
与之相比,基于循环网络架构的 DreamerV3-XL 模型(2 亿参数,与 iVideoGPT 相当)则缺乏在真实世界数据上进行大规模训练的能力,其在 OXE 上的预训练未能准确建模自然的机械臂动力学转移,仅能产生质量低且模糊的预测。

iVideoGPT 可以自然扩展到基于动作的预测和高分辨率,并且不会有明显的时间不一致和闪烁伪影的问题。在下游数据集 BAIR robot pushing 和 RoboNet 上,iVideoGPT 取得了与最先进的模型相当的性能,并在架构上同时实现了交互性和可扩展性。

5.2 基于视觉的模型预测控制
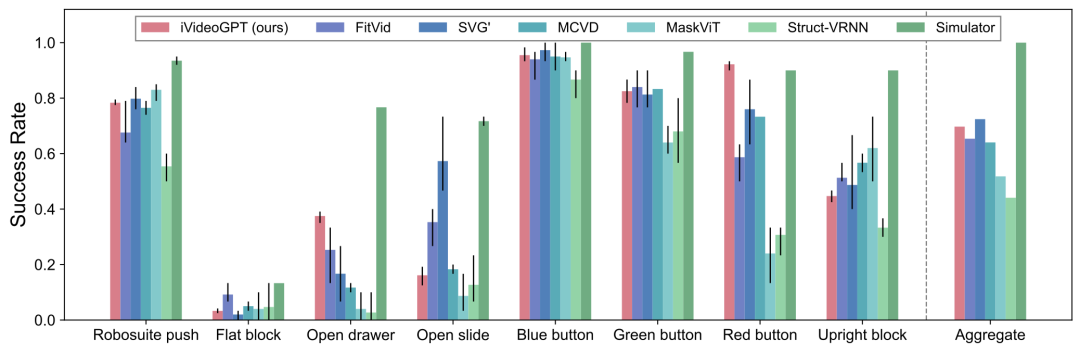
优秀的感知指标并不总是正相关于有效的控制性能。我们在面向视觉规划的视频预测基准 VP2 上也进行了评估。iVideoGPT不仅可以在该领域上预测真实的物体碰撞,还在两个 RoboDesk 控制任务中以较大优势超越所有基线,并在平均性能上与最强模型相当。
5.3 基于视觉的强化学习
利用 iVideoGPT 作为交互式世界模型,我们基于 MBPO 实现了一种基于模型的强化学习算法:通过策略与世界模型交互生成虚拟轨迹来增广 replay buffer,以训练标准的 Actor-critic 算法(DrQ-v2)。将强大的世界模型作为环境的可插入式替代,这一简单的算法避免了使用潜空间想象(latent imagination;Dreamer 等最先进的 MBRL 算法广泛使用)技术,实现了模型学习与策略学习的解耦,能够显著简化算法设计空间,从而大幅提高 MBRL 算法在真实世界应用中的实用性和有效性。
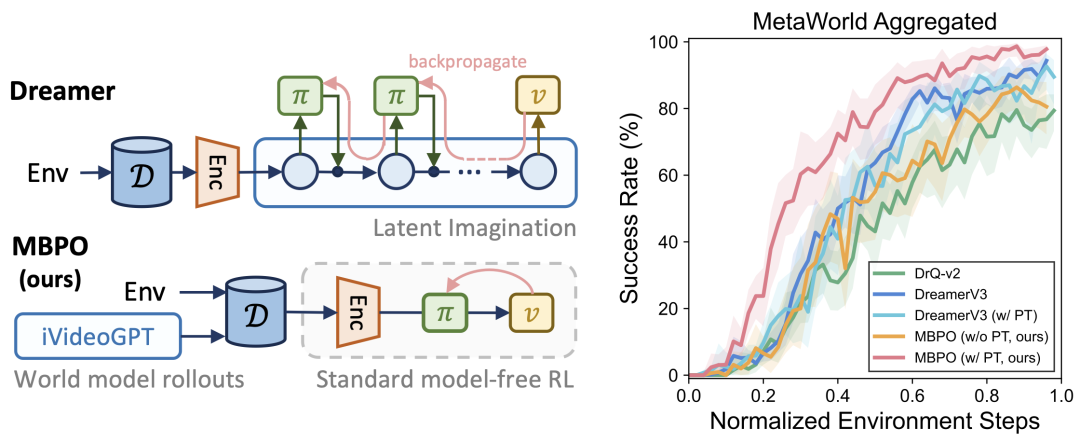
我们在 MetaWorld 上 6 个具有不同难度的操作任务上进行了实验。我们的基于模型的算法不仅相较于无模型的基线显著提高了样本效率,还能够达到甚至超越 DreamerV3 的性能。据我们所知,这是 MBPO 首次成功应用于视觉连续控制任务。我们还证明了 iVideoGPT 的预训练能够帮助其快速适应到 MetaWorld 环境,提升 MBRL 的样本效率。相反,DreamerV3 则无法从其在相同数据上低效的预训练中获益。
5.4 模型分析
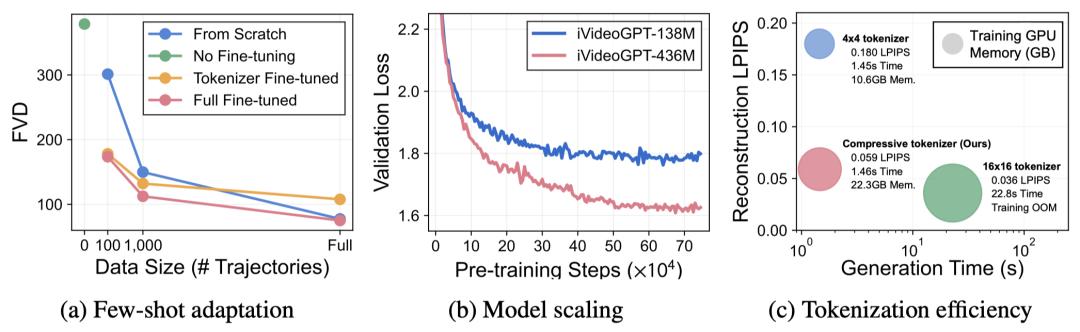
我们从以下几个方面对模型能力进行了分析:
-
少样本适配:预训练能够在下游数据不足(1,000 或 100 条轨迹)的情况下提供显著的性能收益; -
模型扩展:通过增加计算可以构建更强大的 iVideoGPT,符合 Scaling Law; -
计算效率:压缩标记化技术在略微牺牲重建质量的条件下,可以在训练时显著节省显存,并在推理时加快生成速度(1.46s vs. 22.8s); -
场景-运动信息解耦:通过在重建未来帧时去除解码器中的对初始帧的交叉注意力模块,解码器仍然能够重建出与原始轨迹运动方式相同的轨迹,但视觉场景信息几乎完全丢失。

6. 总结
总而言之,我们提出了 iVideoGPT,这是一种基于压缩标记化和自回归 Transformer 的通用且高效的世界模型架构。iVideoGPT 能够在百万条人类与机器人操作轨迹上进行预训练,并适配于广泛的下游任务,实现了精准且具备良好泛化能力的视频预测,以及简化但高效的基于模型的强化学习。本研究弥合了视频生成模型与世界模型之间的差距,推进了通用交互式世界模型的发展。
iVideoGPT 仍有很大的空间可以改进。公开的机器人数据的数量和多样性仍然不足,iVideoGPT 需要在更广泛的数据上进行预训练,以便获取真正通用的世界知识,并观察在更复杂的机器人任务上的 Scaling Law。
欢迎感兴趣的朋友阅读我们的论文 (https://arxiv.org/abs/2405.15223) 或者访问项目主页 (https://thuml.github.io/iVideoGPT) 查看更多细节内容。

(文:极市干货)