


论文作者来自阿里巴巴通义实验室的 3D 团队。第一作者何益升,本科毕业于武汉大学,博士毕业于香港科技大学;通讯作者原玮浩,本科毕业于浙江大学,博士毕业于香港科技大学;团队 Leader 董子龙,本科博士均毕业于浙江大学。
三维数字头像的建模、驱动和渲染是计算机图形学与计算机视觉的重要课题之一,在虚拟会议、影视制作、游戏开发等领域有广泛应用。传统方法依赖多视角数据或视频序列训练,存在计算成本高、输入条件难、泛化能力弱等问题。
近年来,基于神经辐射场(NeRF)和 3D 高斯溅射(Gaussian Splatting)的技术虽提升了建模质量,但仍面临多视角/视频输入训练的依赖以及神经后处理导致的渲染效率低的问题。
LAM(Large Avatar Model)的提出,旨在通过单张图像实现实时可驱动的 3D 高斯头像生成,突破传统方法对视频数据或复杂后处理的依赖,为轻量化、跨平台的 3D 数字人应用提供新思路。

-
论文标题:LAM:Large Avatar Model for One-shot Animatable Gaussian Head
-
论文地址:https://arxiv.org/abs/2502.17796
-
项目主页: https://aigc3d.github.io/projects/LAM
-
代码库:https://github.com/aigc3d/LAM
-
国外 Demo:https://huggingface.co/spaces/3DAIGC/LAM
-
国内 Demo:https://www.modelscope.cn/studios/Damo_XR_Lab/LAM_Large_Avatar_Model
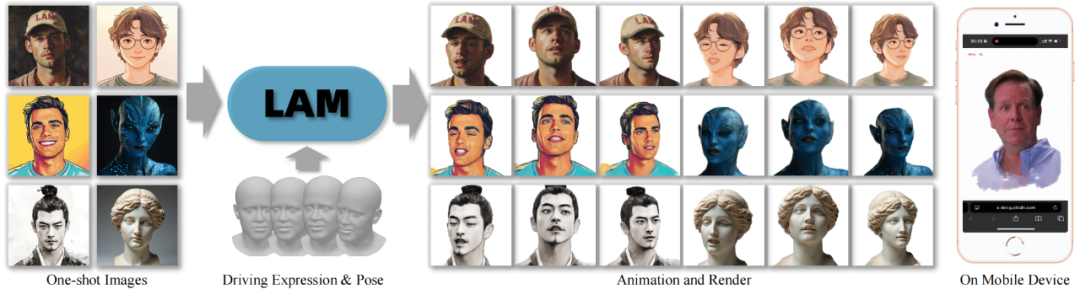
核心亮点:
🔥 单图秒级生成超写实 3D 数字人
🔥 WebGL 跨平台超实时驱动渲染,手机跑满 120FPS
🔥 低延迟实时交互对话数字人 SDK 已全开源
方法
LAM 的核心目标是:单图输入、一次前向传播生成可驱动的 3D 高斯头像,无需后处理网络,并兼容传统图形渲染管线实现跨平台实时渲染。其技术框架围绕以下核心突破展开:
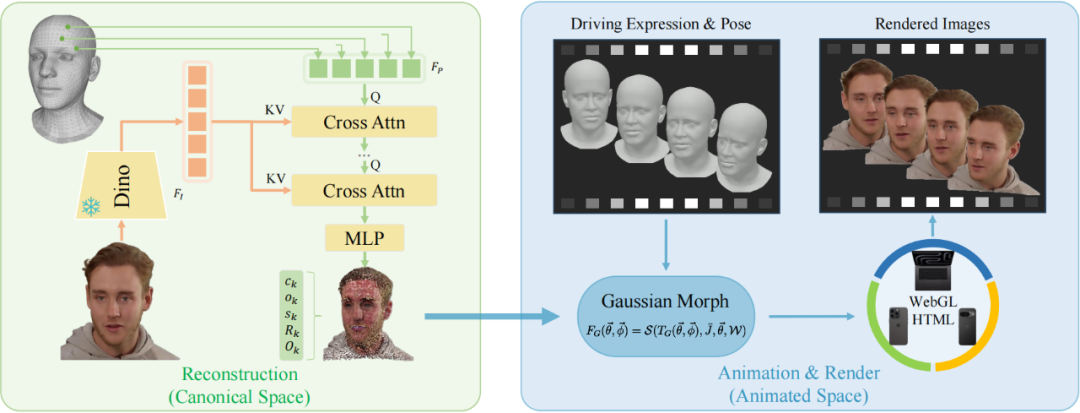
规范化空间的三维高斯球生成
-
人头模型先验引导:LAM 基于 FLAME 头部模板的顶点来初始化高斯球位置,结合形状混合形变(Blendshapes)与骨骼线性蒙皮(LBS)的驱动机制,将三维头像的生成置于规范化空间(Canonical Space),统一不同表情与姿态的几何表达,降低生成复杂度。
-
多模态特征交互 Transformer:LAM 利用预训练的 DinoV2 提取输入图像的多层级特征,通过堆叠式交叉注意力模块(Cross-Attention)让 3D 空间中的点特征与 2D 空间中的图像特征进行交互,预测 3D 高斯球的位置、颜色、透明度等属性,并引入形变偏移(Offset)优化人头的几何形状(如头发、饰品等)。
-
细分网格增强细节:FLAME 原始顶点数只有 5023 个,表达能力有限,LAM 通过网格细分算法(Mesh Subdivision)增加点密度(默认两次细分达 81424 点),从而提升头发、胡须等细节的建模能力。使用不同的细分程度,也可以在模型生成质量与渲染速度之间进行平衡。
无需神经后处理的驱动与渲染
-
传统动画驱动机制直接迁移:生成的规范空间中的 3D 高斯人头,可直接使用骨骼线性混合蒙皮(LBS)与形状混合形变(Blendshapes)参数,驱动表情与姿态变化,无需额外神经网络参与动画或渲染计算,达到超实时的渲染效率。
-
海量视频数据训练:传统 3D 数字人的训练数据要求苛刻,有时甚至需要多视角视频数据,难以 scale up,而 LAM 的模型架构使其可以在普通的单目视频上进行训练,从而可以很轻易地 scale up。在模型训练中,一段视频中取任意一帧作为输入图片,生成 3D 高斯人头,然后基于视频检测得到的头部姿态和面部表情,渲染不同帧的图片,与真值之间求损失来优化生成网络。
跨平台超实时渲染架构
-
轻量化 3D 高斯表达:LAM 的驱动和渲染没有任何神经网络的参与,是直接使用传统动画驱动 + 三维高斯溅射渲染,因此可以直接兼容传统图形管线。
-
WebGL 渲染:LAM 基于 WebGL 实现了表情、动作驱动和三维高斯溅射的渲染,天然支持跨平台的特性,可以在不同设备如电脑、手机、电视、大屏等设备上进行直接驱动和渲染,效率达到超实时,如 8W 点模型可以在 Macbook 上轻松跑满屏幕上限 120FPS,2W 点模型甚至能在移动端跑到 120FPS。

实验
定量结果
论文在 VFHQ(高分辨率视频人脸数据集)与 HDTF(高清对话视频数据集)上验证 LAM 性能,对比对象包括 NeRF 方法及 3D 高斯溅射方法,指标涵盖重建质量、身份一致性、动画精度与渲染效率。
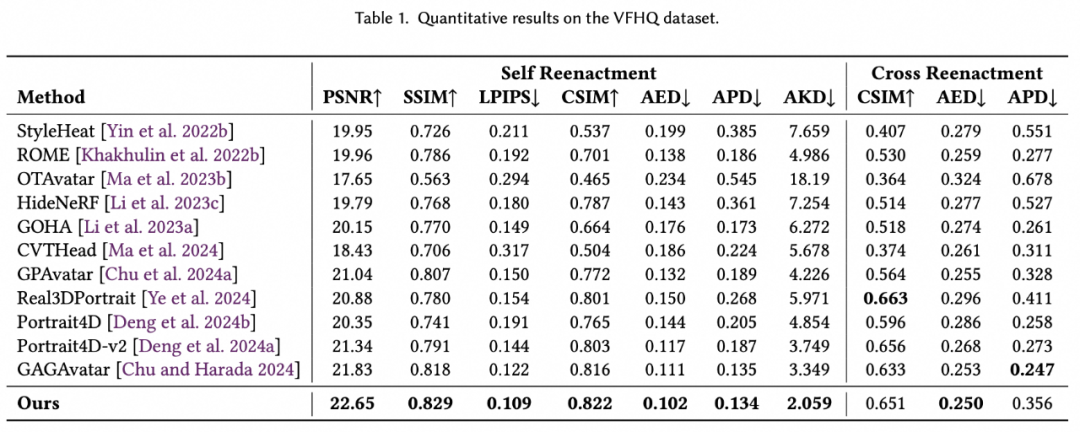
从结果来看,LAM 以超写实的图像质量刷新记录,以无神经网络的超轻量模型击败之前的重网络模型。
更多应用
LAM 不仅限于单图生成,也可以结合图像大模型进行实现跨模态艺术创作:
-
文本驱动生成
结合文生图模型,用户输入提示词(如「戴帽子的卡通男性」)生成任意风格的人头图像,LAM 可以直接转换为可驱动三维高斯模型。如图所示,生成的头像可准确保留提示中的服饰元素(帽子)与艺术风格(卡通化):

-
3D 风格迁移
通过图像编辑模型对输入图像进行年龄、妆容等编辑,LAM 可以同步更新高斯属性。例如将真人头像转化为油画风格时,模型保留几何结构仅调整颜色与纹理等:

交互对话数字人解决方案
以 LAM 为基础,通义实验室构建了完整的智能交互对话数字人解决方案,融合通义千问大语言模型、通义语音算法、通义数字人驱动算法,构建成熟、鲁棒的完整工程方案,实现轻量化、低成本、低延迟、跨平台的端侧渲染,支持智能客服、情感陪伴、教育培训等产品。
目前,完整的解决方案均已开源,包括整个链路中的各个模块。即使用开源的代码库,就可以实现输入一张图片,生成超写实 3D 数字人,进行实时的对话聊天。
©
(文:机器之心)