

机器之心编辑部
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。
近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。
大多数语言模型都基于 Transformer 架构,其在进行自回归解码(即逐字生成文本)时,需要将所有先前 token 的注意力状态存储在一个名为 KV 缓存的内存区域中。

KV 缓存是模型进行快速推理的基石,但它的大小会随着输入文本的长度线性增长。例如,使用 Llama-3-70B 模型处理一个长度为 128K token 的提示(这大约相当于 Llama 3 技术报告本身的长度),就需要分配高达 42GB 的内存专门用于存储 KV 缓存。
许多先前的工作意识到了这个问题,并提出了从内存中丢弃(驱逐)部分键值对的方法,以实现所谓的「稀疏注意力」。然而,在一个公平的环境下对它们进行横向比较却异常困难。

生成过程 = 预填充(对输入进行前向传播并保存键值对)+ 后填充(一次解码一个输出词元)。
有些论文旨在加速预填充阶段;另一些则忽略该阶段,转而致力于最小化后填充阶段的内存开销。同样,有的研究侧重于吞吐量,而另一些则着力于优化内存使用。
陈丹琦团队提出了「KV 足迹」作为一种统一的度量标准,它是在所有时间步中,未被逐出的键值缓存条目所占比例的聚合值。这一个指标就同时涵盖了预填充和解码两个阶段的全部开销,使得在同等基础上比较不同方法成为可能。

-
论文标题:Cache Me If You Can: How ManyKVsDoYouNeed for Effective Long-Context LMs?
-
论文地址:https://arxiv.org/pdf/2506.17121v1
-
代码地址: https://github.com/princeton-pli/PruLong
为了确保比较的实用价值,团队定义了「关键 KV 足迹」:即在模型性能相对于完整的全注意力机制不低于 90% 的前提下,一个方法所能达到的最小 KV 足迹。这个「90% 性能」的硬性标准,确保了我们比较的是真正有用的、未严重牺牲模型能力的优化方法。
该度量标准揭示了先前 KV 驱逐方法存在的高峰值内存问题。其中后填充驱逐由于与预填充阶段的驱逐不兼容,导致其 KV 足迹非常高。团队对这类方法进行了改进,使其能够在预填充期间驱逐 KV,从而显著降低了 KV 足迹。
接着,团队转向「新近度驱逐」方法,并在此基础上提出了 PruLong,这是一种端到端的优化方法,用于学习哪些注意力头需要保留完整的 KV 缓存,而哪些则不需要。PruLong 在节省内存的同时保持了长上下文性能,其 KV 足迹比先前的方法小 12%,并且在具有挑战性的召回任务中保持了原有的性能。
KV 缓存驱逐的统一框架
测量关键的 KV 占用空间
给定一个包含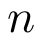 个 token 的提示语
个 token 的提示语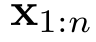 ,基于 Transformer 的语言模型通常分两个阶段来生成一个响应
,基于 Transformer 的语言模型通常分两个阶段来生成一个响应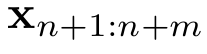 :
:
-
预填充
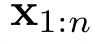 在一次前向传播过程中被处理。每个注意力头 的键值状态
在一次前向传播过程中被处理。每个注意力头 的键值状态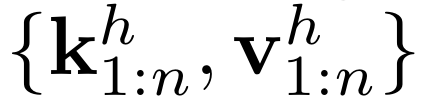 被存储在 KV 缓存中。这里
被存储在 KV 缓存中。这里 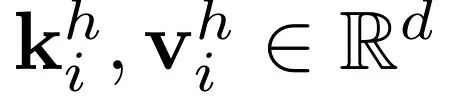 ,其中 是该注意力头的维度。
,其中 是该注意力头的维度。-
解码
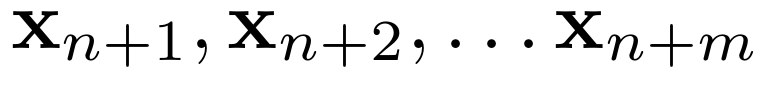 这些 token,每次生成时都会读取并更新 KV 缓存。
这些 token,每次生成时都会读取并更新 KV 缓存。KV 缓存的存储消耗会随着提示长度和生成长度的增加而线性增长,研究人员提出了许多方法来解决这一开销问题。总体而言,这些方法通过稀疏化注意力模式,从而允许某些 KV 条目被驱逐。
然而,这些方法针对推理流程的不同阶段进行了定制:有些方法在预填充阶段之后丢弃 KV 条目,而另一些方法则在预填充阶段也对 KV 缓存进行修剪。这使得对不同方法进行公平且全面的比较变得困难。首先探讨为何常用的 KV 缓存大小指标无法衡量模型在实际应用中的实用性。
在实际应用中,对长上下文进行单次前向传播的预填充操作成本高昂。对于长输入序列,将输入序列分割成多个块,并在多次前向传播中处理这些块的分块预填充方法正日益成为标准实践。这种方法通常能够减少与长输入相关的峰值 GPU 内存占用,并使得较短提示的解码过程能够与较长提示的额外块同时进行。
此外,像多轮对话或交错工具调用等场景,还需要多个解码和预填充阶段,这就需要一种全面的方法来衡量 KV 占用空间。而推测性解码进一步模糊了预填充阶段和解码阶段之间的界限,因为解码过程变得更加依赖计算资源。
在考虑预填充和解码过程中都进行多次前向传播的推理情况时,「KV 占用空间」应考虑随时间变化的内存使用情况。例如,它应反映出在分块预填充过程中,是否在预填充完成之前就已经驱逐了 KV 条目。
具体的推理过程由输入长度、输出长度以及因方法而异的实现细节来表征。由于缺乏能够捕捉所有这些细微差别的指标,本研究提出了一种理想化的指标,该指标能够:(1)跟踪整个预填充和解码过程中的 KV 缓存内存使用情况;(2)考虑每个 KV 条目的生命周期,从而实现对不同方法的公平且全面的比较。
本研究检查这些方法的注意力模式(图 1),并将每个键值(KV)条目分类为:活跃的(在当前步骤中使用)、非活跃的(在当前步骤中存储但未使用)或被驱逐的(在任何未来的步骤中都未使用,并从内存中移除)。本研究将 KV 占用空间定义为所有时间步中未被驱逐的注意力条目的数量。该数值被归一化为完全因果注意力。
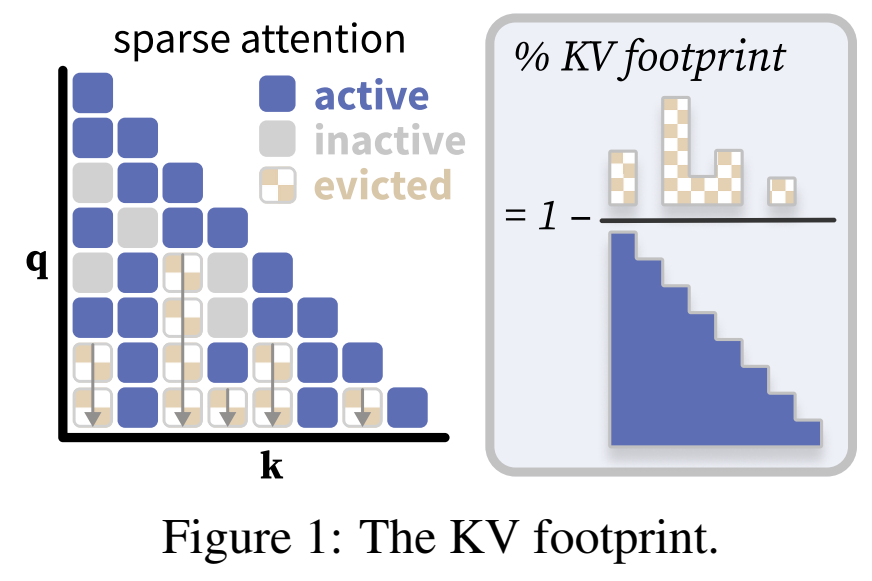
例如,在图 1 中,KV 占用空间为 。一种理想的方法会尽早驱逐 KV,以尽量减少占用空间。本研究考虑了另一种指标,该指标跟踪注意力矩阵中的峰值 KV 占用率。在实验中,这两种指标得出的结论相似。
本研究还讨论了方法与实际性能指标(如总令牌吞吐量和 GPU 内存利用率)之间的关系。研究发现,在许多情况下,KV 占用空间与吞吐量密切相关,但具体的排名取决于 KV 驱逐之外的实现细节——不同方法在不同实现框架下的实际效率差异很大。
关键 KV 占用空间:以往的研究通常在固定的稀疏度水平下报告任务性能,但本研究认为,一个更有意义的指标是在保留大部分原始性能的情况下所能达到的稀疏度。本研究将关键 KV 占用空间定义为一种方法在长上下文任务中保留完整注意力性能的一部分(本文中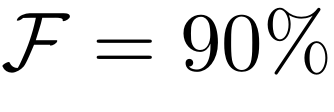 )时所需的最小占用空间。低于此阈值,性能下降可能会过于严重,导致该方法无法继续使用。
)时所需的最小占用空间。低于此阈值,性能下降可能会过于严重,导致该方法无法继续使用。
高效长上下文推理的现有方法
本研究调研了高效的长上下文方法,并讨论了它们如何契合本研究的 KV 占用空间框架。表 1 概述了主要方法,展示了这些方法如何进行不同的权衡以及使用不同的稀疏性概念。
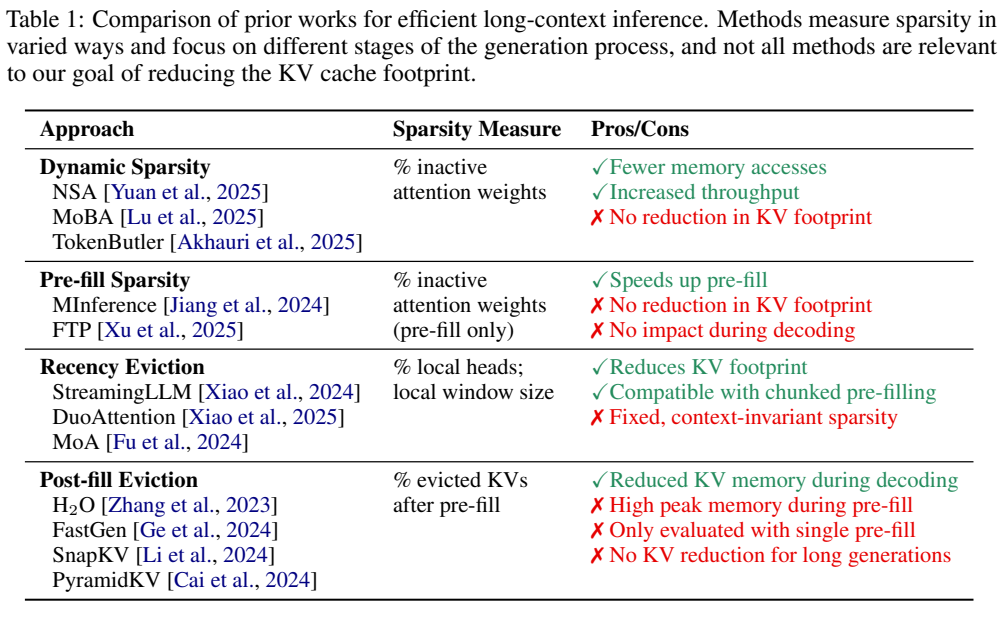
动态和预填充稀疏性方面:Native Sparse Attention、MoBA、QUEST 和 TokenButler 将 KV 缓存视为两级层次结构,仅将相关的注意力块从高带宽内存(HBM)加载到片上 SRAM 进行处理。像 MInference 和 FTP 这类技术,在预填充阶段使用动态稀疏注意力来近似全注意力。动态稀疏性方法会产生更多非活跃的 KV,能够提升吞吐量,但它们并未减少 KV 内存,因此这些方法与本研究的关注点正交。
近期性驱逐:先前的研究确定了流式注意力头,这些注意力头仅关注局部滑动窗口和一组初始的「汇聚令牌」。驱逐远距离的键值(KV)条目会大幅减少 KV 占用空间(图 2),因为在上下文长度增加时,KV 缓存的大小保持固定,并且这种方法可在预填充和解码过程中应用。然而,近期性驱逐可能会「遗忘」相关的远距离上下文,这促使 DuoAttention 和 MoA 仅将一部分注意力头转换为流式头。作为 KV 缓存压缩的有前景的候选方法,后续将更详细地讨论这些方法。
后填充驱逐:我们使用「后填充驱逐」这一术语来指代在预填充阶段结束后从键值(KV)缓存中删除令牌的方法。这些方法依赖于通常基于注意力分数的启发式规则来识别上下文中最重要键值对。这些方法可以在预填充后大量修剪键值对,并在解码过程中减少 KV 内存。然而,在具有长提示和短生成的推理场景中,由于所有 KV 条目在预填充期间都保存在内存中,这也会在驱逐前导致相当大的峰值内存,后填充驱逐只能实现有限的 KV 占用空间减少。
正交技术:量化通过降低 KV 缓存的精度而非基数来节省内存,并且可以与本文考虑的任何方法结合使用。另一个方向是在预训练新语言模型之前设计内存高效的架构。这可能涉及在查询或层之间重用 KV 状态,降低键值维度,或者交错全局和局部注意力层。其他方法是用循环层、线性注意力或状态空间层替换 softmax 注意力。这些方法与 KV 驱逐正交。
PruLong:一种用于注意力头专业化的端到端方法
本研究探讨过:驱逐「陈旧」键值对(KVs)虽能显著降低内存占用,但可能导致重要历史信息的丢失。这一发现推动了后续研究工作,旨在识别哪些注意力头关注全局上下文、哪些聚焦局部上下文,从而仅对局部注意力头中的 KVs 执行驱逐操作。
DuoAttention 将注意力头分为两类:检索头,从整个上下文中召回相关信息;流式头,仅关注最近的 token 和输入序列开头的少量「汇聚」token。DuoAttention 通过将注意力机制表示为流式注意力和全注意力的叠加,并通过参数化来学习注意力头的类型。
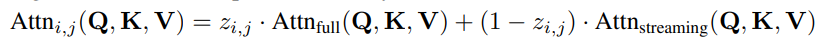
其中,
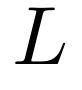
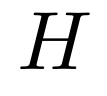
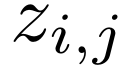

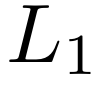
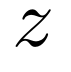
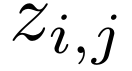
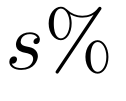
虽然 DuoAttention 在实证中表现出色,但团队发现了几种进一步降低其关键 KV 占用空间的方法。团队结合这些见解,设计出 PruLong(长程精简注意力机制),一种用于 KV 驱逐的端到端方法。PruLong 像 DuoAttention 一样将注意力头分为两类,但在训练目标、参数化和训练数据方面进行了创新。接下来将依次介绍这些内容。
-
下一个 token 预测损失
PruLong(长程精简注意力机制)直接最小化混合注意力模型的下一个 token 预测损失,而非最后一个隐藏状态的重建误差,这与这些模型在文本生成中的使用方式更为契合。
-
针对注意力类型优化离散掩码
DuoAttention 学习一个连续的门控变量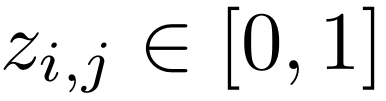 ,该变量易于优化,但没有反映出在推理过程中
,该变量易于优化,但没有反映出在推理过程中 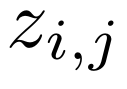 会被四舍五入为 0 或 1,因此引入了训练-测试差距。PruLong(长程精简注意力机制)将视为从由
会被四舍五入为 0 或 1,因此引入了训练-测试差距。PruLong(长程精简注意力机制)将视为从由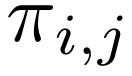 参数化的伯努利分布中抽取的二进制掩码,并通过来自剪枝文献的既定方法——将伯努利分布重新参数化为硬实体随机变量,实现端到端优化。最终目标如下
参数化的伯努利分布中抽取的二进制掩码,并通过来自剪枝文献的既定方法——将伯努利分布重新参数化为硬实体随机变量,实现端到端优化。最终目标如下
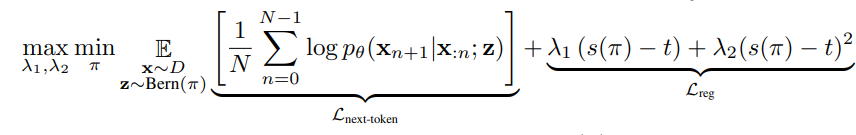
其中,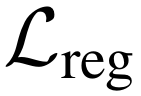 (正则化损失)通过约束掩码整体稀疏度
(正则化损失)通过约束掩码整体稀疏度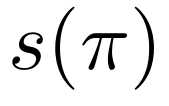 (稀疏度函数)逼近目标值
(稀疏度函数)逼近目标值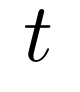 (目标稀疏度),该过程通过 min-max 优化实现——
(目标稀疏度),该过程通过 min-max 优化实现——
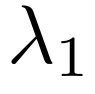

-
利用自然长上下文数据
PruLong 利用自然长上下文数据。DuoAttention 的合成训练数据仅需要简单的长程回忆能力,而实际应用场景可能需要更复杂的能力。PruLong 由高天宇等人在自然长上下文预训练数据上进行训练,这些数据包含代码仓库和书籍等,具有多样的长程依赖关系。
PruLong 论文地址:https://arxiv.org/abs/2410.02660

©
(文:机器之心)