


月之暗面(Moonshot AI)有了它的首个AI Agent。
最近,Kimi Researcher(深度研究)开启内测。根据官方介绍,其定位并非一个简单的“搜索工具”,而是一个能够生成带引用来源的深度研究报告的AI Agent。根据技术博客披露的数据,Kimi Researcher在实际运行中平均会搜索超过200个URL,运行70多次搜索查询,最终生成超过1万字的深度报告。在Humanity’s Last Exam(HLE)这一高难度基准测试中,其得分达到26.9%,创下了该测试的最高纪录。
(我们也拿到了一些Kimi深度研究内测名额,将优先提供给有具体需求的朋友。有兴趣的读者可以添加微信,并发送暗号:AI Agent,简短介绍你对AI Agent的使用情况和需求。我们会手动邀请你加入我们的AI Agent交流群。群里会不定期提供最新AI Agent类产品上手体验内测资格,以及与开发团队直接交流的机会。)

2024年以来,AI Agent领域呈现两个明显趋势:一是从“外挂式”向“内化式”转变,即从依赖外部工具调用转向提升模型本身的能力;二是从规则驱动向学习驱动转变,让AI通过大规模训练自主发现解决问题的策略。Kimi Researcher的推出,正是这一趋势的具体体现。
在当前AI领域,Agent被普遍认为是通往通用人工智能(AGI)的重要方向。目前,行业内构建Agent的主流方法之一,是采用“工作流(Workflow)”模式。例如,Devin 和 Manus 都采用了明显的任务拆分 + 预定义执行流程架构:先由 Planner 制定多阶段计划,然后 Executor 调用工具一步步完成任务,并根据反馈继续调整。
这种方法通过提示词工程(Prompt Engineering)和模块化设计,将大语言模型与各种外部工具进行链接,其优势在于流程清晰、可控性强。但同时,这种依赖人类预先设计流程的模式,在面对开放、复杂任务时,也存在灵活性不足、难以泛化等挑战,这促使一些团队开始探索新的技术路径。
Kimi Researcher所选择的,就是另一条不同的技术路线:端到端的强化学习(End-to-End Reinforcement Learning, E2E RL)。这一方法的核心,是让模型在一个模拟的环境中通过大量的自主探索和试错来学习,目标是让模型自己“领悟”出完成任务的策略,而不是严格遵循一套由人类编写的固定步骤。这种将能力“内化”于模型自身的思路,与“工作流”模式下模型作为“调用者”的思路有显著不同。
采用端到端强化学习训练Agent面临诸多技术挑战,首先是环境的不稳定性,网络搜索结果会随时间变化;其次是长序列决策问题,一个研究任务可能需要上百个步骤;最后是计算资源消耗,每次训练迭代都需要大量的“试错”过程。月之暗面通过部分展开(Partial Rollout)等技术创新,将训练效率提升了1.5倍。
值得注意的是,将E2E RL应用于研究型Agent的探索并非孤例。OpenAI官方Deep Research系统卡中提到,该模型学习了包括浏览、使用Python工具进行计算分析以及推理整合大量网站信息的能力。其训练方法与o1模型所使用的强化学习方法一脉相承。
根据OpenAI团队成员Isa Fulford 和 Josh Tobin在红杉资本的播客《OpenAI’s Deep Research on Training AI Agents End-to-End》中的分享,Deep Research 并非通过手动将模型和工具拼成 workflow,而是用端到端强化学习在浏览+推理任务上训练模型,让其自主规划、回退、调整策略,Deep Research使用了类似的端到端强化学习进行训练,由于Deep Research处理的任务往往没有标准可验证的答案来提供奖励信号,分析表明他们可能使用了LLM as Judge(大型语言模型作为评判者)来实施强化学习。在强化学习中,奖励机制是核心,而LLM as Judge是一种通过语言模型评估Agent行为并提供反馈的方法。这种方法特别适用于没有明确奖励信号的复杂任务,能够优化Agent的表现。
而当不同团队不约而同地选择相似的技术方向时,他们各自积累的技术基础可能会带来最终产品的差异。例如,月之暗面以其长上下文(Long Context)技术为基础,而OpenAI则以其通用推理能力见长的模型系列为基础,这些不同的技术侧重,可能会影响其Agent在处理任务时的具体表现和能力边界。
在产品层面,Kimi Researcher将后端的技术以“双报告系统”的形式呈现给用户:一份是包含详细文字和可溯源引用的深度报告,另一份则是动态、可视化的网页报告,后者通过思维导图和图表来提升信息获取效率。此外,产品在交互上会尝试主动澄清用户的模糊需求,以帮助定义清晰的问题。
要理解这一技术选择背后的具体思考、挑战与惊喜,来自其团队核心成员的第一人称分享,提供了最直接的视角。
以下为月之暗面研究员冯一尘、毛绍光在知乎问题《月之暗面 Kimi 首个 Agent 开启内测,可生成易追溯的万字报告,有哪些技术亮点?》下的回答,已获得官方授权,括号内灰色文字部分均为编者注。
冯一尘回答
谢邀, 很高兴和大家分享Kimi智能体(Agent)首个产品Kimi Researcher背后的一些技术思考。
Kimi-Researcher,是一个人类最后一场考试(Humanity’s Last Exam)(由非营利组织 Center for AI Safety(CAIS)与 Scale AI 于 2024 年联合创建的大规模多学科闭合问答基准测试,包含约 3000 道专家级高难度问题,涵盖生物、化学、物理、数学、人文等领域,被视为检验 AI 系统是否具备真正专家级推理能力的终极挑战。)达到SOTA(State-Of-The-Art,指当前最优/最先进的成绩) 26.9%、可生成万字追溯报告的模型Agent,也是我们用端到端强化学习(RL)从0到1打磨出来的首个大模型Agent产品。我们构建Kimi-Researcher的核心理念是:我们并非在搭建一个“搜索工具”,而是在训练一个真正会“做研究”的AI Agent。
为了实现这一点,我们选择了一条更难走、但我们坚信是通往更强智能Agent的必经之路:端到端的强化学习 (End-to-End Reinforcement Learning)。
其实这个项目从去年上半年立项,到10月份探索版发布,我们内部也经历了不少认知上的转变。随着thinking模型路线逐步清晰,我们意识到有两个关键变量极其重要:
一是要做“能长思考”的Agent,二是要用端到端强化学习。为什么要做长思考模型,Flood(月之暗面研究员Flood Sung)在这个回答(https://www.zhihu.com/question/10114790245/answer/84028353434)已经解释得很详细,我就重点讲讲我们为什么坚持端到端RL。
传统Agent方法的局限
目前主要有两种做法:
-
Workflow(工作流,指预先定义的任务执行步骤和逻辑。传统Agent通过组合不同的工作流来完成任务,如“搜索→分析→总结”的固定流程)拼装:比如基于OpenAI/Claude去搭建(通过API调用底层模型,再通过预设规则组合各种工具)“多Agent+规划器+子任务”,靠手动Prompt和条件规则,把复杂任务拆分成小模块。每换一次底层模型,整个workflow就要大改一遍,灵活性受限。而且基于OpenAI/Claude搭建的Agent在国内也无法开放使用。
-
SFT(模仿学习):人工标注完整任务轨迹,Agent模仿这些轨迹,提升Agent整体的能力。但这里面收集数据很耗费人力,难以Scale到大量的数据。
这些方案本质都受限于“人能设计/人能标注”的上限,不符合我们相信的scaling。
端到端强化学习(RL)的优势:让模型自己“进化”
在强化学习的设定下,我们为Agent建立了一个虚拟的环境,让它像一个真正的“科研”新手一样,通过海量的自主探索、试错、并从“做对了”的成功经验中学习,最终“进化”出强大的研究能力。对比传统方法的好处:
-
挣脱“固定流程”的束缚,更灵活通用。RL Agent的行为不是被规则写死的,而是根据当前任务动态生成的。这让它在面对闻所未闻的复杂问题时,有能力探索出创造性的解决方案。我们升级底层模型时,也无需重构整个Agent体系。
-
能力上限更高,用“数据”而非“设计”来驱动增长 当我们发现Agent在某类问题上表现不佳时,我们的解决方案不是去绞尽脑汁地修改Prompt或Workflow,而是将这类问题加入到训练数据中,通过增加“训练题量”和算力,让模型自己学会如何解决。前者的天花板是“人的智慧”,后者的天花板是“数据和算力”——我们坚信后者要高得多。
-
能Scale。相比SFT依赖人类标注,RL路线可以让Agent在环境中不断探索,只要我们能准确判断任务是否成功(即提供准确的奖励信号),加大算力去Rollout(在强化学习中,指让Agent在环境中执行一系列动作并收集经验数据的过程,对于长任务,Rollout会消耗大量计算资源和时间),就能获得源源不断的、高质量的on-policy训练数据(指在当前策略下收集的数据,这些数据更能反映模型的实际行为模式,训练效果优于使用历史数据或其他模型产生的数据),让模型持续不断地自我迭代和提升。(感兴趣的同学可以去读下The Bitter Lesson)(由强化学习之父Richard Sutton撰写的著名文章,核心观点是:在AI研究中,依赖人类知识的复杂方法最终会被那些能更好利用大规模计算的通用方法所超越。)
RL的效果和“涌现”的惊喜
这条路虽然难,但端到端强化学习给我带来了很多惊喜。
在Humanity’s Last Exam(人类的最后一场考试)这个榜单上,我们的Agent模型得分从最初的8.6%跃升至26.9%,这一巨大增长几乎完全归功于强化学习。这一成绩也走到了世界前沿,相比OpenAI Deep Research团队在相关工作上从20分左右 (o3) 提升到26.6分的成果,进一步证明了强化学习在Agent训练上的巨大价值。
在HLE这个评测集上,我们的pass@4(pass@k是评估AI模型的常用指标,表示在k次尝试中至少有一次成功的概率 )指标达到了40.17%,这意味着即使面对非常困难的问题,Agent 在4次自主尝试内,就有超过四成的概率能成功解决。对于训练而言,只要Agent能探索到正确的路径,我们就有机会把它转化为模型的内在能力。
更有意思的是,我们观察到了很多智能的“涌现”:
-
模型在已经很快找到初步答案后,并不会立即停止,而是会主动进行多轮搜索,从不同来源的信息进行交叉验证,以确保结论的准确性。
-
我们甚至观察到,模型在遇到一个极度专业的问题、现有信息无法解答时,它会“思考”并产生一个action——“给这篇论文的作者发邮件寻求解答”。(当然,出于安全原因我们拦截了这种action)
这些行为都不是我们预先设计的,而是模型在追求“完成任务”这个最终目标的过程中,自己学会的有效策略。这让我们看到了通往更通用智能的希望。
Kimi-Researcher能做什么
它能帮你对一个陌生领域快速上手,生成一份带引用的深度报告;能帮你做论文研读和文献综述;甚至能成为你的科研Copilot。我们自己也常用 Kimi-Researcher 做信息搜集与分析。
-
场景1: 尽调与搜索
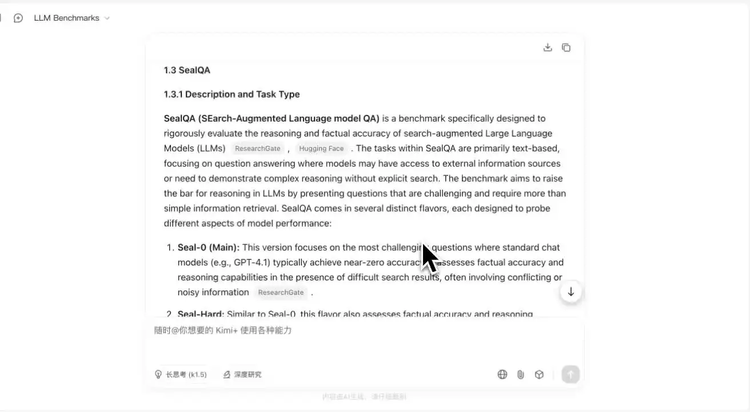
我们自己就用Kimi-Researcher去调研“有哪些衡量模型推理能力、且SOTA分数在20分以内的benchmark”,它成功找到了几个我们团队尚未关注到的最新的benchmark,非常有价值。
Kimi 除了找到了AGI-2,HLE,OlympiadBench,还找到FrontierMath和6月1日新发布的Seal QA。
Prompt:Survey all advanced benchmarks that all frontier LLM scores lower than 20%, focus on text. example like HLE
-
场景2:知识体系梳理
Kimi researcher 可以帮你理解复杂知识结构,比如下面这个案例,Kimi 依时间线梳理关键事件、制度差异及影响因素,帮助快速把握三大体系的逻辑脉络,为课堂讲解和研究写作提供了结构化材料。
Prompt:分析人类历史上三大货币体系的演变:金本位、布雷顿森林体系、浮动汇率制度

-
场景3: Make a 101
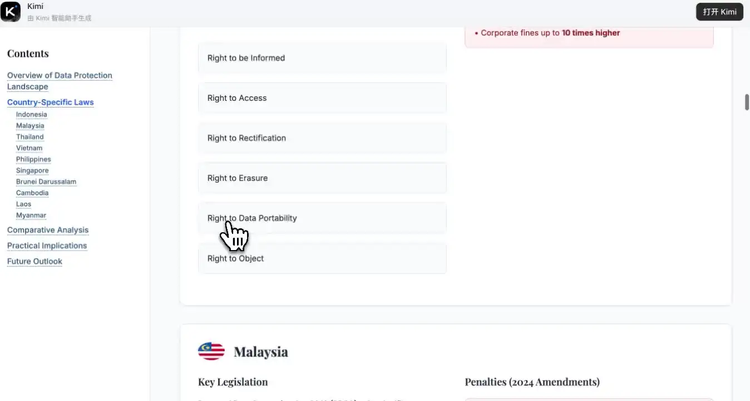
可以快速了解一个陌生领域,比如隐私法,有一个overview:
Prompt:I’m an in-house lawyer at a Chinese robotic company, and the management is considering expanding into Southeast Asian countries. However, I’m not quite confident about the data and privacy requirements in those countries. Could you help me list the names of the data and privacy laws of Southeast Asian countries (on a country-by-country basis), and preferably provide a brief summary and key takeaways of those laws?
Kimi 在十几分钟内生成了一份信息全面、结构清晰的万字报告,内容涵盖10个国家的关键法规和政策信息、以及核心条款的对比。

关键数据点在可交互报告中一目了然。哪国更宽松、哪国要求更严,不再需要逐段比对文本。
-
场景4: 陪你探索你的热爱
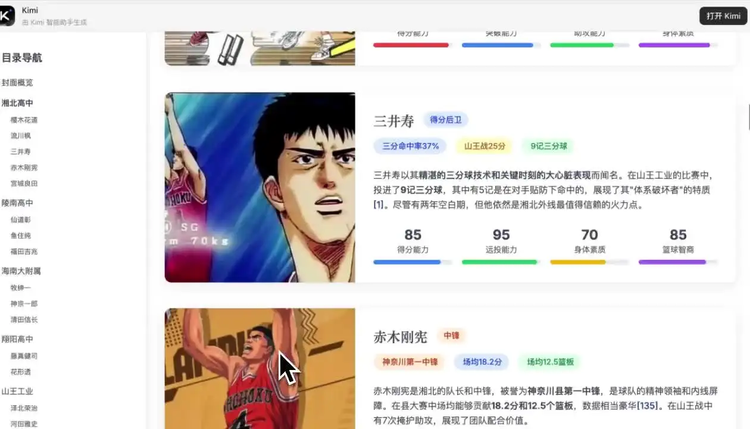
甚至能基于虚拟漫画世界中的比赛数据分析人物角色的技术特点:
Prompt:研究一下灌篮高手的各个球队中主力队员在篮球技术面板的实际能力,给出球探分析报告
-
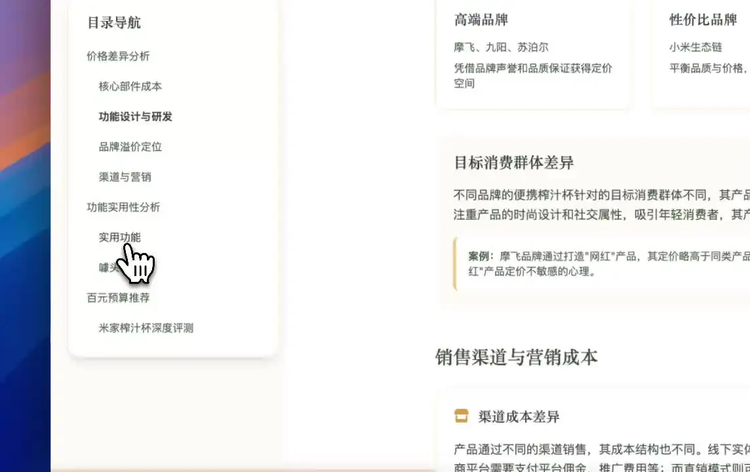
场景5: 帮你挑选参数复杂、需求个性化的商品
Prompt:我最近在考虑入手一个便携榨汁杯,主要是想早上做早餐的时候快速打一杯果汁或代餐奶昔。但我发现现在市面上这种榨汁杯五花八门,价格差异也很大,有的只要五六十元,有的能卖到三四百,甚至看到一些小众品牌比大牌还贵。功能介绍上也都差不多,比如“磁吸充电”“一键启动”“轻音高速电机”等等。
请你从一个行业内人士的角度,帮我讲讲:为什么便携榨汁杯在相似功能下价格差这么多?
哪些宣传功能是实用的,哪些只是噱头?
在一百元左右的预算内,有哪些值得推荐、质量靠谱的款式?
我希望你能分析得详细一些,帮我少踩点坑。
也欢迎大家分享更多使用案例,以及建议。
总而言之,Kimi Researcher不只是一个新功能,更是我们在Agent技术路线上的一次坚定探索和阶段性成果。我们相信,通过强化学习,未来的AI Agent将不再仅仅是“工具”,而是能与人类深度协作的“伙伴”。
产品后续还会持续更新和开源,非常欢迎大家体验和关注我们的技术博客(https://moonshotai.github.io/Kimi-Researcher/)。
毛绍光回答
谢邀,非常开心能参与到Kimi-Researcher这个工作,很激动看到这个模型/产品的落地。作为一个Agent方向的研究者,这段工作对我个人是一段非常精彩难忘的旅程。借此机会分享一些对Agent方向发展的思考和Kimi-Researcher工作中的一些思考。
如我们这Tech Blog中提到,Kimi-Researcher是一个完全依靠RL训练的Agent 模型(RL即Reinforcement Learning强化学习,这是AI领域的一种训练方法,通过试错和奖励机制让模型学习最优策略),这件事情走通是一件很酷的事情。Agent在ChatGPT之后,这个概念再次复兴,在前司也参与过一些和Agent相关的早期工作(2019年加入微软,通用人工智能组资深研发工程师,主要研究方向为基于语言模型的推理,AI智能体及多智能体系统。开发的相关技术被应用于微软Microsoft 365 Word等产品),包括最早在23年初利用Prompt把ChatGPT链接API扩展模型的能力和MultiAgent的一些工作。早期Agent领域有一些非常不错的工作,随着搭了越来越多的框架和应用demo后(LangChain、AutoGPT等),这个概念越来越火。再后来,Agent进入到了一个“有些奇怪”的方向,在一段时间内,做Agent的人和做模型的人分道扬镳,似乎模型层和应用层被划开了,Agent变成了针对模型层面的Prompt Engineering和工程侧外接不同模块,做Agent的工作逐渐趋同,工作差异性小,无外乎写Prompt调用工具,定Workflow等等,看不到特别让人兴奋的论文 or 工作。和同行的一些研究员们聊的时候,我们也会感到这个方向越来越没意思了,有点加速衰亡的感觉。
大概在去年下半年开始,我开始认为Agent应该是一个模型本身,而不只是Model + Workflow。在我看来,Workflow虽然扩充了模型的边界,但是随着任务的复杂程度提高,要定义的workflow的复杂程度指数上升,而在Workflow Agent运行过程中,这种Workflow Agent很难产生泛化,也比较难对没有处理的任务产生通用性,这会使得Workflow Agent变成打补丁,遇到一个问题,解决一个问题。
因此我们面临了两个选择,第一,等基础模型变得更强,基于API搭Workflow,稳定得拿搭Workflow的增益,第二,让Agent的能力进入到模型本身,从Reasoner(具备推理能力的语言模型)走到Agent,Agent自己本身就是模型。
机缘巧合,在今年年初加入了Kimi,来到这里后发现大家的vision非常一致,就是提高模型的智能,提高模型的边界,或者说就是要做AGI。自然我们坚定地选择了第二条路,训一个Agent Model会面临很多的挑战,尽管RL在训练Reasoning Model时展现出惊人的效果,但Agent RL还是面临许多不一样的挑战,比如说Agent是工作在真实环境中的,他面临的环境是动态的,比如环境会时常发生一些抖动,同一个工具在不同的情况下会产生不同的调用结果,再比如Agent的任务是long-horizon的(指需要模型进行多步骤、长序列的推理和决策才能完成的复杂任务,Agent需要完成的研究任务可能包含数十甚至上百个步骤,每一步都会影响后续决策),这对于模型本身的context长度管理,rollout的效率以及训练的稳定性都带来了很多的挑战,再比如如何找到可以激发模型Agent能力的训练数据,以及每条成功的Trajectory(在强化学习语境中,指Agent从初始状态到终止状态所经历的一系列状态、动作和奖励的完整序列)都是极长的context,怎样有效的学习。一些具体的细节我们写在了技术blog(https://http://moonshotai.github.io/Kimi-Researcher/)中,未来也会有technical report分享更多details。
AI领域日新月异,每天都会有新的新闻,四个月前刚加入Moonshot,到今天,有种很久的感觉:)
这段旅程的最大感受是 认知+坚持,在前期用充分的实验拿认知,确定好方向,要坚持做下去,给训练一些耐心,也给自己一些沉淀。在Kimi的工作是非常有爽感,模型/产品/开发/数据的沟通交互非常高效,认知、数据的共享也加快了我们的项目进度,身边的同事对AI充满信心又才华横溢。
Kimi-Researcher从6.20起已逐步开始向大家开放,但碍于服务的稳定性,我们需要一段时间逐步推向更大的用户群体,希望Kimi-Researcher可以给大家带来深度报告和好的体验。 Kimi-Researcher只是这段旅程的一个开始,他验证了我们可以通过RL的形式将Agent需要的能力内化进模型本身,未来我们会继续增加Task和工具,让模型进一步在探索中泛化,General Agent就在不远的“明天”!
本文看法仅代表个人观点,与Moonshot AI不构成直接关系:)
彩蛋部分:同事用kimi-Researcher给我做的个人网站,真的被惊讶到了!
邮箱都给找出来了… 不过Microsoft的邮箱已经不用了。

(文:硅星人Pro)